

Abstract
Jointly achieving parsimony and good predictive power in high dimensions is a main challenge in statistics. Non-local priors (NLPs) possess appealing properties for model choice, but their use for estimation has not been studied in detail. We show that for regular models NLP-based Bayesian model averaging (BMA) shrink spurious parameters either at fast polynomial or quasi-exponential rates as the sample size n increases, while non-spurious parameter estimates are not shrunk. We extend some results to linear models with dimension p growing with n. Coupled with our theoretical investigations, we outline the constructive representation of NLPs as mixtures of truncated distributions that enables simple posterior sampling and extending NLPs beyond previous proposals. Our results show notable high-dimensional estimation for linear models with p ≫ n at low computational cost. NLPs provided lower estimation error than benchmark and hyper-g priors, SCAD and LASSO in simulations, and in gene expression data achieved higher cross-validated R2 with less predictors. Remarkably, these results were obtained without pre-screening variables. Our findings contribute to the debate of whether different priors should be used for estimation and model selection, showing that selection priors may actually be desirable for high-dimensional estimation.
Keywords: Model Selection, MCMC, Non Local Priors, Bayesian Model Averaging, Shrinkage
1. Introduction
Developing high-dimensional methods to balance parsimony and predictive power is a main challenge in statistics. Non-local priors (NLPs) are appealing for Bayesian model selection. Relative to local priors (LPs), NLPs discard spurious covariates faster as the sample size n grows, but preserve exponential rates to detect non-zero coefficients (Johnson and Rossell, 2010). When combined with Bayesian model averaging (BMA), this regularization has important consequences for estimation.
Denote the observations by , where is the sample space. We entertain a collection of models Mk for k = 1, …, K with densities fk(yn | θk, ϕk), where θk ∈ Θk ⊆ Θ are parameters of interest and ϕk ∈ Φ is a fixed-dimension nuisance parameter. Let pk = dim(Θk) and without loss of generality let MK be the full model within which M1, …, MK−1 are nested (Θk ⊂ ΘK = Θ). To ease notation let (θ, ϕ) = (θK, ϕK) ∈ Θ×Φ be the parameters under MK and p = pK = dim(Θ). A prior density π(θk | Mk) for θk ∈ Θk under Mk is a NLP if it converges to 0 as θk approaches any value θ0 consistent with a sub-model Mk′ (and a LP otherwise).
Definition 1
Let θk ∈ Θk, an absolutely continuous measure with density π(θk | Mk) is a non-local prior if for any θ0 ∈ Θk, ⊂ Θk, k′ ≠ k.
For precision we assume that intersections Θk ∩ Θk′ have 0 Lebesgue measure and are included in some Mk″, k″ ∈ {1, …, K}. As an example consider a Normal linear model yn ~ N(Xnθ, ϕI) where Xn is an n × p matrix with p predictors, θ ∈ Θ = ℝp and ϕ ∈ Φ = ℝ+. As we do not know which columns in Xn truly predict yn we consider K = 2p models by setting elements in θ to 0, i.e. fk(yn | θk, ϕk) = N(yn; Xk,nθk, ϕkI) where Xk,n is a subset of columns of Xn. We develop our analysis considering the following NLPs
| (1) |
| (2) |
| (3) |
where i ∈ Mk are the non-zero coefficients and πM, πI and πE are called the product MOM, iMOM and eMOM priors (pMOM, piMOM and peMOM).
A motivation for considering K models is to learn which parameters are truly needed to improve estimation. Consider the usual BMA estimate
| (4) |
where P (Mk | yn) ∝ mk(yn)P (Mk) and mk(yn) = ∫ ∫ fk(yn | θk, ϕk)π(θ | ϕk, Mk)π(ϕk | Mk)dθkdϕk is the integrated likelihood under Mk. BMA shrinks estimates by assigning small P (Mk | yn) to unnecessarily complex models. The intuition is that NLPs assign even smaller weights. Let Mt be the smallest model such that ft(yn | θt, ϕt) minimizes Kullback-Leibler divergence (KL) to the data-generating density f*(yn) amongst all (θ, ϕ) ∈ Θ × Φ. For instance, in Normal linear regression this means minimizing the expected quadratic error E((yn − Xnθ)′(yn − Xnθ)) with respect to f*(yn) (which may not be a linear model and include Xn when it is random). Under regular models with fixed P (Mk) and p, if π(θk | Mk) is a LP and Mt ⊂ Mk then (Dawid, 1999). Models with spurious parameters are hence regularized at a slow polynomial rate, which we shall see implies E(θi | yn) = Op(n−1)r (Section 2), where r depends on model prior probabilities. Any LP can be transformed into a NLP to achieve faster shrinkage, e.g. E(θi | yn) = Op(n−2)r (pMOM) or (peMOM, piMOM). We note that another strategy is to shrink via r, e.g. Castillo and Van der Vaart (2012) and Castillo et al. (2014) show that P (Mk) decreasing fast enough with pk achieve good posterior concentration. Martin and Walker (2013) propose a related empirical Bayes strategy. Yet another option is to consider the single model MK and specify absolutely continuous shrinkage priors that induce posterior concentration (Bhattacharya et al., 2012). For a related review on penalized-likelihood strategies see Fan and Lv (2010).
In contrast our strategy is based upon faster mk(yn) rates, a data-dependent quantity. For Normal linear models with bounded P (Mk)/P (Mt) Johnson and Rossell (2012) and Shin et al. (2015) showed that when p = O(nα) or (respectively) with α < 1 and certain regularity conditions pertain one obtains when using certain NLPs and to 0 when using any LP, which from (4) implies the strong oracle property . We note that when sparse unbounded P (Mk)/P (Mt) are used, consistency of P (Mt | yn) may still be achieved with LPs, e.g. setting prior inclusion probabilities for γ > 0 as in Liang et al. (2013) or Narisetty and He (2014).
Our main contribution is considering parameter estimation under NLPs, as previous work focused on model selection. We characterize complexity penalties and BMA shrinkage for certain linear and asymptotically Normal models (Section 2). We also provide a fully general NLP representation from latent truncations (Section 3) that justifies NLPs intuitively and adds flexibility in prior choice. Suppose we wish to both estimate θ ∈ ℝ and test M1 : θ = 0 vs. M2 : θ ≠ 0. Figure 1 (grey) shows a Cauchy(0, 0.25) prior expressing confidence that θ is close to 0, e.g. P (|θ| > 0.25) = 0.5. Under this prior P (θ = 0 | yn) = 0 and hence there is no BMA shrinkage. Instead we set P (θ = 0) = 0.5 and, conditional on θ ≠ 0, a Cauchy(0,0.25) truncated to exclude (−λ, λ), where λ is a practical significance threshold (Figure 1(top)). Truncated priors have been discussed before, e.g. Verdinelli and Wasserman (1996), Rousseau (2007). They encourage coherence between estimation and testing, but they cannot detect small but non-zero coefficients. Suppose that we set λ ~ G(2.5, 10) to express our uncertainty about λ. Figure 1 (bottom) shows the marginal prior on θ after integrating out λ. It is a smooth version of the truncated Cauchy that goes to 0 as θ → 0, i.e. a NLP. Section 4 exploits this construction for posterior sampling. Finally, Section 5 studies finite-sample performance in simulations and gene expression data, in particular finding that BMA achieves lower quadratic error than the posterior modes used in Johnson and Rossell (2012).
Figure 1.
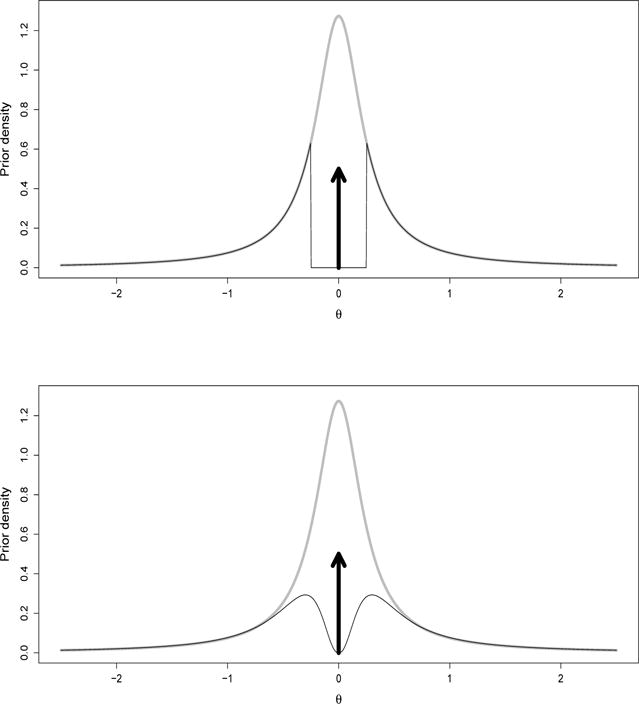
Marginal priors for θ ∈ ℝ (estimation prior Cauchy(0, 0.0625) shown in grey). Top: mixture of point mass at 0 and Cauchy(0, 0.0625) truncated at λ = 0.25; Bottom: same as top with λ ~ IG(3, 10)
2. Data-dependent shrinkage
We now show that NLPs induce a strong data-dependent shrinkage. To see why, note that any NLP can be written as π(θk, ϕk | Mk) ∝ dk(θk, ϕk)πL(θk, ϕk | Mk), where dk(θk, ϕk) → 0 as θk → θ0 for any θ0 ∈ Θk′ ⊂ Θk and πL(θk, ϕk) is LP. NLPs are often expressed in this form but the representation is always possible since . Intuitively, dk(θk, ϕk) adds a penalty term that improves both selection and shrinkage via (4). The theorems below make the intuition rigorous. Proposition 1 shows that NLPs modify the marginal likelihood by a data-dependent term that converges to 0 for certain models containing spurious parameters. The result does not provide precise rates, but shows that under very general situations NLPs improve Bayesian regularization. Proposition 2 gives rates for posterior means and modes under a given Mk for finite p asymptotically Normal models and growing p linear models, whereas gives Proposition 3 Bayes factor and BMA rates.
We first discuss the needed regularity assumptions. Throughout we assume that π(θk, ϕk | Mk) is proper, π(ϕk | Mk) is continuous and bounded for all ϕk ∈ Φ, denote by mk(yn) the integrated likelihood under π(θk | ϕk, Mk) = dk(θk, ϕk)πL(θk, ϕk) and by that under the corresponding LP. Assumptions A1–A5, B1–B4 are from Walker (1969) (W69, Supplementary Section 1) and guarantee asymptotic MLE normality and validity of second order log-likelihood expansions, e.g. including generalized linear models with finite p. A second set of assumptions for finite p models follows.
Conditions on finite-dimensional models
-
C1Let A ⊂ Θk × Φ be such that for any minimizes KL to f*(yn). For any as n → ∞
-
C2
Let . The ratio of marginal likelihoods as n → ∞, ε ∈ (0, 1).
-
C3
Let (θ*, ϕ*) minimize KL(f*(yn), fK(θ, ϕ) for (θ, ϕ) ∈ (Θ, Φ). There is a unique Mt with smallest pt such that and , for any k such that Mk ⊄ Mt.
-
C4
In C3 ϕ* is fixed and for fixed where either an = 1 or with an ≫ n−1/2 (pMOM) or an ≫ n−1/4 (peMOM, piMOM).
C1 essentially gives MLE consistency and C2 a boundedness condition that guarantees under a pMOM for a certain neighbourhood N(A) of the KL-optimal parameter values, the key to ensure that dk(θk, ϕk) acts as a penalty term. Redner (1981) gives general conditions for C1 that include even certain non-identifiable models. C2 is equivalent to the ratio of posterior densities under τ and τ(1 + ε) at an arbitrary (θk, ϕk) and converging to a constant, which holds under W69 or Conditions D1–D2 below (see proof of Proposition 1 for details). C3 assumes a unique smallest model minimizing KL to f*(yn) and that there is no equivalent model Mk ⊅ Mt, e.g. for linear models no Mk ⊅ Mt can have pk = pt variables being perfectly collinear with Xt,n. C4 allows θ* to be either fixed or to vanishes at rates slower than n−1/2 (pMOM) or n−1/4 (peMOM, piMOM), to characterize the ability to estimate small signals. Finally, for linear models we consider the following.
Conditions on linear models of growing dimension
-
D1
Suppose fk(yn | θk, ϕk) = N(yn; Xk,nθk, ϕkI), θk ∈ Θk, pk = dim(θk) = O(nα) and α < 1.
-
D2
There are fixed a, b, n0 > 0 such that for all n > n0, where l1, lk are the smallest and largest eigenvalues of .
D1 reflects the common practice that although p ≫ n one does not consider models with pk ≥ n, which lead to data interpolation. D2 guarantees strong MLE consistency (Lai et al., 1979) and implies that no considered model has perfectly collinear covariates, aligning with applied practice. For further discussion on eigenvalues see Chen and Chen (2008) and Narisetty and He (2014). We now state our first result. All proofs are in the Supplementary Material.
Proposition 1
Let mk(yn), be as above.
- We have: , where
- Assume fk(yn | θk, ϕk) with finite pk satisfies C1 under a peMOM or piMOM prior or C2 under a pMOM prior for some A. If is a singleton (identifiable models), then . For any A, if
for some t ∈ {1, …, K}, then when Mt ⊂ Mk, k ≠ t and
when Mk ⊆ Mt. Let fk(yn | θk, ϕk) = N(yn; Xn,kθk, ϕkI), with growing pk, satisfy D1–D2. Let minimize KL to f*(yn) with and . Then and , where , . Further, if then with c = 0 when either Mt ⊂ Mk or Mt ⊄ Mk but a column in converges to zero. Else, c > 0.
That is, even when the data-generating f*(yn) does not belong to the set of considered models, gk(yn) converges to 0 for certain Mk containing spurious parameters, e.g. for linear models when either Mt ⊂ Mk or Mt ⊄ Mk but some columns in Xk,n are uncorrelated with Xt,n given Xk,n ∩ Xt,n. Propositions 2–3 give rates for the case when .
Proposition 2
Let be the unique MLE and minimize KL to the data-generating for . Assume C3–C4 are satisfied.
Let fk(y | θk, ϕk) with fixed pk satisfy W69 and be the posterior mode, with for i = 1, …, pk under a pMOM, peMOM or piMOM prior. If is fixed then for some 0 < c < ∞. If with an → 0 as in C4 then for pMOM and for peMOM, piMOM. If then for pMOM and for peMOM, piMOM with 0 < c < ∞. Further, any other posterior mode is Op(n−1/2) (pMOM) or Op(n−1/4) (peMOM, piMOM).
Under the conditions in (i) for pMOM and for peMOM/piMOM.
Let fk(yn | θk, ϕk) = N(yn; Xn,kθk, ϕkI) satisfy D1–D2 with diagonal . Then the rates in (i)–(ii) remain valid.
We note that given that there is a prior mode in each of the 2pk quadrants (combination of signs of θki) there always exists a posterior mode satisfying the sign conditions in (i). Further, for elliptical log-likelihoods given that the pMOM, peMOM and piMOM priors have independent symmetric components the global posterior mode is guaranteed to occur in the same quadrant as . Part (i) first characterizes the behaviour of this dominant mode and subsequently the behaviour of all other modes. Conditional on Mk, spurious parameter estimates converge to 0 at n−1/2 (pMOM) or n−1/4 (peMOM,piMOM). Vanishing are captured as long as (pMOM) or (peMOM, piMOM). This holds for fixed pk or linear models with growing pk and diagonal . We leave further extensions as future work.
Proposition 3 shows that weighting these estimates with P (Mk | yn) gives a strong selective shrinkage. We denote , , , p1 = p − p0 and let be the mean under the data-generating f(yn | θ*, ϕ*).
Proposition 3
Let E(θi | yn) be as in (4), Mt the data-generating model, BFkt = mk(y)/mt(y) and an as in C4. Assume that P (Mk)/P(Mt) = o(n(pk−pt)) for Mt ⊂ Mk.
Let all Mk satisfy W69, C3 and p be fixed. If Mt ⊄ Mk, then BFkt = Op(e−n) under a pMOM, peMOM or piMOM prior if are fixed and if . If Mt ⊂ Mk then under a pMOM prior and under peMOM or piMOM.
- Under the conditions in (i) let an be as in C4 and r = maxkP(Mk)/P(Mt) where pk = pt + 1, Mt ⊂ Mk. Then the posterior means and sums of squared errors satisfy
pMOM peMOM-piMOM E(θi | yn) SSR E(θi | yn) SSR Op(p1n−1) Op(p1n−1) Op(p1n−1) Op(p1n−1/2) rOp(n−2) Op(p0r2n−4) - Let yn ~ N(Xn,kθk, ϕkI) satisfy D1–D2 with diagonal and known ϕ. Let ε, be arbitrarily small constants and assume that P (θ1 ≠ 0, …, θp ≠ 0) is exchangeable with r = P (δi = 1)/P (δi = 0). Then
pMOM peMOM-piMOM E(θi | yn, ϕ) E(θi | yn, ϕ) O(p1/n1−ε) Op(p1/n1−ε) O(p1/n1−ε) rOp(n−2) Op(p0r2/n4−ε)
BMA estimates for active coefficients are of their true value (Op(n−1/4) for vanishing under peMOM or piMOM), but inactive coefficients estimates are shrunk at rOp(n−2) or (to be compared with rOp(n−1) under the corresponding LPs) where r are the prior inclusion odds. The condition for Mt ⊂ Mk ensures that complex models are not favoured a priori (usually P (Mk)/P (Mt) = O(1)). The condition in Part (iii) prevents the prior from favouring overly sparse solutions. For instance, a Beta-Binomial(1, l) prior on the model size gives r = 1/l, hence any fixed finite l satisfies . Suppose that we set l = p, then is satisfied as long as for some α < 1.
3. Non-local priors as truncation mixtures
We establish a correspondence between NLPs and truncation mixtures. Our discussion is conditional on Mk, hence for simplicity we omit ϕ and denote π(θ) = π(θ | Mk), p = dim(Θk).
3.1. Equivalence between NLPs and truncation mixtures
We show that truncation mixtures define valid NLPs, and subsequently that any NLP may be represented in this manner. Given that the representation is not unique, we give two constructions and discuss their merits. Let πL(θ) be an arbitrary LP and λ ∈ ℝ+ a latent truncation.
Proposition 4
Define π(θ | λ) ∝ πL(θ)I(d(θ) > λ), where for any θ0 ∈ Θk′⊂ Θk, and πL (θ) is bounded in a neighborhood of θ0. Let π(λ) be a marginal prior for λ placing no probability mass at λ = 0. Then π(θ) = ∫π(θ | λ)π(λ)dλ defines a NLP.
Corollary 5
Assume that . Let where λ = (λ1, …, λp)′ have an absolutely continuous prior π(λ). Then ∫π(θ | λ)π(λ)dλ is a NLP.
Example 1
Consider yn ~ N(Xθ, ϕI), where θ ∈ ℝp, ϕ is known and I is the n×n identity matrix. We define a NLP for θ with a single truncation point with and some π(λ), e.g. Gamma or Inverse Gamma. Obviously, the choice of π(λ) affects π(θ) (Section 3.2). An alternative prior is
giving marginal independence when π(λ1, …, λp) has independent components.
We address the reverse question: given any NLP, a truncation representation is always possible.
Proposition 6
Let π(θ) ∝ d(θ)πL(θ) be a NLP and denote h(λ) = Pu (d(θ) > λ), where Pu(·) is the probability under πL(θ). Then π(θ) is the marginal prior associated to π(θ | λ) ∝ πL(θ)I(d(θ) > λ) and π(λ) = h(λ)/Eu (d(θ)) ∝ h(λ), where Eu (·) is the expectation with respect to πL(θ).
Corollary 7
Let be a NLP,
and assume that ∫h(λ)dλ < ∞. Then π(θ) is the marginal prior associated to and π(λ) ∝ h(λ).
Corollary 7 adds latent variables but greatly facilitates sampling. The condition ∫h(λ)dλ < ∞ is guaranteed when πL(θ) has independent components (apply Proposition 6 to each θi).
Example 2
The pMOM prior with , πL(θ) = N(θ, 0, τI) can be represented as and
where h(·) is the survival function for a product of independent chi-square random variables with 1 degree of freedom (Springer and Thompson, 1970). Prior draws are obtained by
Draw u ~ Unif(0, 1). Set λ = P −1(u), where P(u) = Pπ(λ ≤ u) is the cdf associated to π(λ).
Draw θ ~ N(0, τI)I(d(θ) > λ).
As drawbacks, P(u) requires Meijer G-functions and is cumbersome to evaluate for large p and sampling from a multivariate Normal with truncation region is nontrivial. Corollary 7 gives an alternative. Let P (u) = P (λ < u) be the cdf associated to where h(·) is the survival of a . For i = 1, …, p, draw ui ~ Unif(0, 1), set λi = P−1 (ui) and draw θi ~ N(0, τ)I(θi > |λi|). The function P−1(·) can be tabulated and quickly evaluated, rendering efficient computations. Supplementary Figure 1 shows 100,000 draws from pMOM priors with τ = 5.
3.2. Deriving NLP properties for a given mixture
We show how two important characteristics of a NLP functional form, the penalty and tails, depend on the chosen truncation. We distinguish whether a single or multiple truncation variables are used.
Proposition 8
Let π(θ) be the marginal of , where h(λ) = Pu(d(θ1) > λ, …, d(θp) > λ) and λ ∊ ℝ+ with P (λ = 0) = 0. Let dmin(θ) = min{d(θ1), …, d(θp)}.
- Consider any sequence {θ(m)}m≥1 such that Then
for some λ(m) ∊ (0, dmin(θ(m)). If π(λ) = ch(λ) then . Let {θ(m)}m≥1 be any sequence such that . Then where c > 0 is either a positive constant or ∞. In particular, if then c < ∞.
Property (i) is important as Bayes factor rates depend on the penalty, which we see is given by the smallest d(θ1), …, d(θp). Property (ii) shows that π(θ) inherits its tail behavior from πL(θ). Corollary 9 is an extension to multiple truncations.
Corollary 9
Let π(θ) be the marginal NLP for , where h(λ) = Pu (d1(θ1) > λ1,…,dp(θp) > λp) under πL(θ) and π(λ) is absolutely continuous.
Let {θ(m)}m≥1 such that for i = 1, …, p. Then for some , .
Let {θ(m)}m≥1 such that for i = 1, …p. Then where c ∈ ℝ+ ∪ {∞}. In particular, if E (h(λ)−1) < ∞ under π(λ), then c < ∞.
That is, multiple independent truncation variables give a multiplicative penalty and tails are at least as thick as those of πL(θ). Once a functional form for π(θ) is chosen, we need to set its parameters. Although the asymptotic rates (Section 2) hold for any fixed parameters, their value can be relevant in finite samples. Given that posterior inference depends solely on the marginal prior π(θ), whenever possible we recommend eliciting π(θ) directly. For instance, Johnson and Rossell (2010) defined practical significance in linear regression as signal-to-noise ratios , and gave default τ assigning . Rossell et al. (2013) found analogous τ for probit regression, and also considered learning τ either via a hyper-prior or minimizing posterior predictive loss (Gelfand and Ghosh, 1998). Consonni and La Rocca (2010) devised objective Bayes strategies. Yet another possibility is to match the unit information prior e.g. setting which can be regarded as minimally informative (in fact prior e.g. for the MOM default τ = 0.358). When π(θ) is not in closed-form prior elicitation depends both on τ and π(λ), but prior draws can be used to estimate for any t. An analytical alternative is to set π(λ) so that E(λ) = d(θi, ϕ)when , i.e. E(λ) matches a practical relevance threshold. For instance, for t = 0.2 and π(λ) ~ IG(a, b) under the MOM prior we would set E(λ) = b/(a−1) = 0.22/τ, and under the eMOM prior . Both expressions illustrate the dependence between τ and π (λ). Here we use default τ (Section 5), but as discussed other strategies are possible.
4. Posterior sampling
We use the latent truncation characterization to derive posterior sampling algorithms. Section 4.1 provides two Gibbs algorithms to sample from arbitrary posteriors, and Section 4.2 adapts them to linear models. Sampling is conditional on a given Mk, hence we drop Mk to keep notation simple.
4.1. General algorithm
First consider a NLP defined by a single latent truncation, i.e. , where h(λ) = Pu (d(θ) > λ) and π (λ) a prior on λ ∊ ℝ+. The joint posterior is
| (5) |
Sampling from π(θ | yn) directly is challenging as it is highly multi-modal, but straightforward algebra gives the following kth Gibbs iteration to sample from π(θ, λ | yn).
Algorithm 1. Gibbs sampling with a single truncation
Draw λ(k) ~ π(λ | yn, θ(k−1)) ∝ I(d(θ) > λ)π(λ)/h(λ). When π(λ) ∝ h(λ) as in Proposition 6, λ(k) ~ Unif(0, d(θ(k−1))).
Draw θ(k) ~ π(θ | yn, λ(k)) ∝ πL(θ | yn)I(d(θ) > λ(k)).
That is, λ(k) is sampled from a univariate distribution that reduces to a uniform when setting π(λ) ∝ h(λ), and θ(k) from a truncated version of πL(), which may be a LP that allows posterior sampling. As a difficulty, the truncation region {θ : d(θ) > λ(k)} is non-linear and non-convex so that jointly sampling θ = (θ1, …, θp) may be challenging. One may apply a Gibbs step to each element in θ1, …, θp sequentially, which only requires univariate truncated draws from πL(·), but the mixing of the chain may suffer. The multiple truncation representation in Corollary 7 provides a convenient alternative. Consider , where h(λ) = Pu(d1(θ1) > λ1, … dp(θp) > λp). The following steps define the k Gibbs iteration:
Algorithm 2. Gibbs sampling with multiple truncations
Draw If π(λ) ∝ h(λ) as in Corollary 7, .
Draw
Now the truncation region in Step 2 is defined by hyper-rectangles, which facilitates sampling. As in Algorithm 1, by setting the prior conveniently Step 1 avoids evaluating π(λ) and h(λ).
4.2. Linear models
We adapt Algorithm 2 to a linear regression yn ~ N(Xθ, ϕI) with the three priors in (1)-(3). We set the prior ϕ ~ IG(aϕ/2, bϕ/2). For all three priors, Step 2 in Algorithm 2 samples from a multivariate Normal with rectangular truncation around 0, for which we developed an efficient algorithm. Kotecha and Djuric (1999) and Rodriguez-Yam et al. (2004) proposed Gibbs after orthogonalization strategies that result in low serial correlation, which Wilhelm and Manjunath (2010) implemented in the R package tmvtnorm for restrictions l ≤ θi ≤ u. Here we require sampling under di(θi) ≥ l, a non-convex region. Our adapted algorithm is in Supplementary Section 3 and implemented in R package mombf. An important property is that the algorithm produces independent samples when the posterior probability of the truncation region becomes negligible. Since NLPs only assign high posterior probability to a model when the posterior for non-zero coefficients is well shifted from the origin, the truncation region is indeed often negligible. We outline the algorithm separately for each prior.
4.2.1. pMOM prior
Straightforward algebra gives the full conditional posteriors
| (6) |
where S = X′X + τ−1I, m = S−1X′yn and is the sum of squared residuals. Corollary 7 represents the pMOM prior in (1) as
| (7) |
marginalized with respect to , where h(·) is the survival of a chi-square with 1 degree of freedom. Algorithm 2 and simple algebra give the kth Gibbs iteration
Step 1 samples unconditionally on λ, so that no efficiency is lost for introducing these latent variables. Step 3 requires truncated multivariate Normal draws.
4.2.2. piMOM prior
We assume dim(Θ) < n. The full conditional posteriors are
| (8) |
where S = X′X, m = S−1X′yn and . Now, the piMOM prior is πI(θ | ϕ) =
| (9) |
In principle any τN may be used, but τN ≥ 2τ guarantees d(θi, ϕ) to be monotone increasing in , so that its inverse exists (Supplementary Section 4). By default we set τN = 2τ. Corollary 7 gives
| (10) |
and , where h(λi) = P(d(θi, ϕ) > λi) which we need not evaluate. Algorithm 2 gives the following MH within Gibbs procedure.
- MH step
- Propose
- Set ϕ(k) = ϕ* with probability , else ϕ(k) = ϕ(k−1).
Step 3 requires the inverse d−1(·), which can be evaluated efficiently combining an asymptotic approximation with a linear interpolation search (Supplementary Section 4). As a token, 10,000 draws for p = 2 variables required 0.58 seconds on a 2.8 GHz processor running OS X 10.6.8.
4.2.3. peMOM prior
The full conditional posteriors are
| (11) |
where S = X′X + τ−1I, m = S−1X′yn, a* = aϕ + n + p, . Corollary 7 gives
| (12) |
and . Again h(λi) has no simple form but is not required by Algorithm 2, which gives the kth Gibbs iteration
- Propose
- Set ϕ(k) = ϕ* with probability , else ϕ(k) = ϕ(k−1).
5. Examples
We assess our posterior sampling algorithms and the use of NLPs for high-dimensional estimation. Section 5.1 shows a simple yet illustrative multi-modal example. Section 5.2 studies p ≥ n cases and compares the BMA estimators induced by NLPs with benchmark priors (BP, Fernández et al. (2001)), hyper-g priors (HG, Liang et al. (2008)), SCAD (Fan and Li, 2001), LASSO (Tibshirani, 1996) and Adaptive LASSO (ALASSO, Zhou (2006)). For NLPs and BP we used R package mombf 1.6.0 with default prior dispersions τ = 0.358, 0.133, 0.119 for pMOM, piMOM and peMOM (respectively), which assign 0.01 prior probability to (Johnson and Rossell, 2010), and ϕ ~ IG(0.01/2, 0.01/2). The model search and posterior sampling algorithms are described in Supplementary Section 5. Briefly, we performed 5,000 Gibbs iterations to sample from P(Mk|yn) and subsequently sampled θk given Mk, yn as outlined in Section 4.2. For HG we used R package BMS 0.3.3 with default alpha=3 and 105 MCMC iterations in Section 5.2, for the larger example in Section 5.3 we used package BAS with 3 × 106 iterations as it provided higher accuracy at lower running times. For LASSO, ALASSO and SCAD we set the penalization parameter with 10-fold cross-validation using functions mylars and ncvreg in R packages parcor 0.2.6 and ncvreg 3.2.0 (respectively) with default parameters. The R code is in the supplementary material. For all Bayesian methods we set a Beta-Binomial(1,1) prior on the model space. This is an interesting sparsity-inducing prior, e.g. for Mk with pk = pt + 1 it assigns P(Mk)/P(Mt) = 1/(p − pt). From Proposition 3 if p > n this penalty more than doubles the shrinkage of E(θi|yn) under LPs, i.e. they should perform closer to NLPs. Also note that BP sets θk|ϕk, with g = max{n, p2}, which in our p ≥ n simulations induces extra sparsity and thus shrinkage. We assess the relative merits of each method without any covariate pre-screening procedures.
5.1. Posterior samples for a given model
We simulated n = 1, 000 realizations from yi ~ N(θ1x1i + θ2x2i, 1), where (x1i, x2i) are drawn from a bivariate Normal with E(x1i) = E(x2i) = 0, V(x1i) = V(x2i) = 2, Cov(x1i, x2i) = 1. We first consider θ1 = 0.5, θ2 = 1, and compute posterior probabilities for the four possible models. We assign equal a priori probabilities and obtain exact mk(yn) using pmomMarginalU, pimomMarginalU and pemomMarginalU in mombf (the former has closed-form, for the latter two we used 106 importance samples). The posterior probability assigned to the full model under all three priors is 1 (up to rounding) (Supplementary Table 1). Figure 2 (left) shows 900 Gibbs draws (100 burn-in) obtained under the full model. The posterior mass is well-shifted away from 0 and resembles an elliptical shape for the three priors. Supplementary Table 2 gives the first-order auto-correlations, which are very small. This example reflects the advantages of the orthogonalization strategy, which is particularly efficient as the latent truncation becomes negligible.
Figure 2.
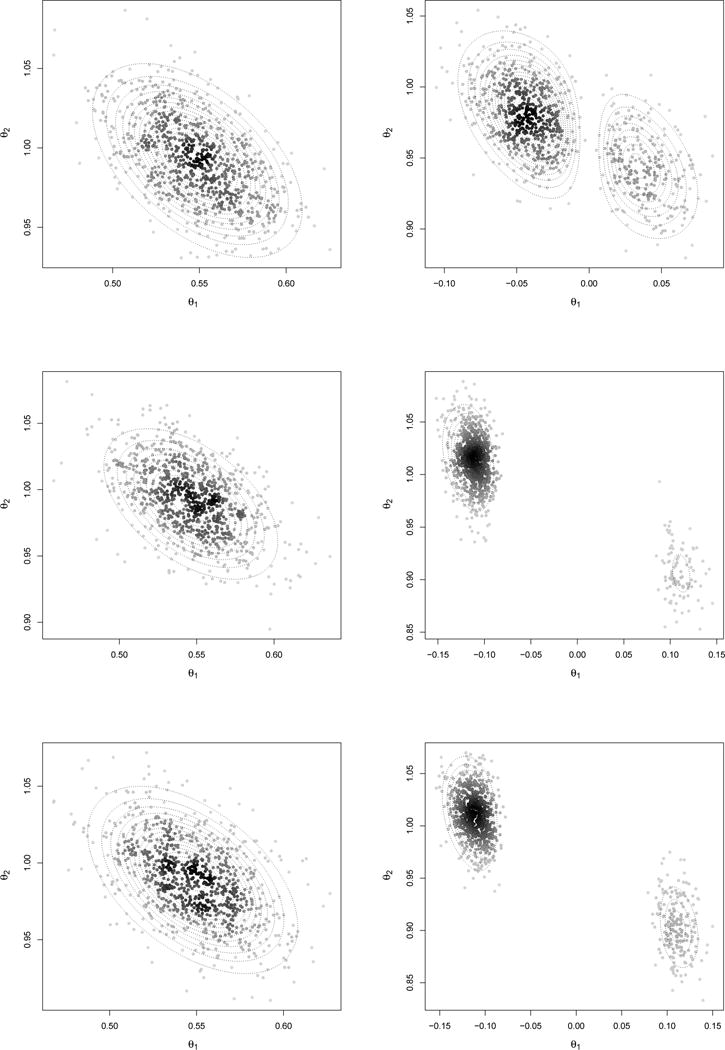
900 Gibbs draws when θ = (0.5, 1)′ (left) and θ = (0, 1)′ (right) and posterior density contours. Top: MOM (τ = 0.358); Middle: iMOM (τ = 0.133); Bottom: eMOM (τ = 0.119)
We now set θ1 = 0, θ2 = 1 and keep n = 1000 and (x1i, x2i) as before. We simulated several data sets and in most cases did not observe a noticeable posterior multi-modality. We portray a specific simulation that did exhibit multi-modality, as this poses a greater challenge from a sampling perspective. Table 1 shows that the data-generating model has highest posterior probability. Although the full model was clearly dismissed in light of the data, as an exercise we drew from its posterior. Figure 2 (right) shows 900 Gibbs draws after a 100 burn-in, and Supplementary Table 2 shows a low auto-correlation. The samples adequately captured the multiple modes.
Table 1.
Expression data with p = 172 or 10, 172 genes. : mean (MOM, iMOM, BP, HG) or selected number of predictors (SCAD, LASSO, ALASSO). R2 coefficient is between (yi, ŷi) (leave-one-out cross-validation). CPU time on Linux OpenSUSE 13.1, 64 bits, 2.6GHz processor, 31.4Gb RAM for 1,000 Gibbs iterations (MOM,iMOM,BP) or 3×106 model updates (HG)
| p = 172 | p = 10, 172 | |||||
|---|---|---|---|---|---|---|
|
|
R2 |
|
R2 | CPU time | ||
| MOM | 4.3 | 0.566 | 6.5 | 0.617 | 1m 52s | |
| iMOM | 5.3 | 0.560 | 10.3 | 0.620 | 59m | |
| BP | 4.2 | 0.562 | 3.0 | 0.586 | 1m 23s | |
| HG | 11.3 | 0.562 | 26.4 | 0.522 | 11m 49s | |
| SCAD | 29 | 0.565 | 81 | 0.535 | 16.7s | |
| LASSO | 42 | 0.586 | 159 | 0.570 | 23.7s | |
| ALASSO | 24 | 0.569 | 10 | 0.536 | 2m 49s | |
5.2. High-dimensional estimation
5.2.1. Growing p, fixed n and θ
We perform a simulation study with n = 100 and growing p = 100, 500, 1000. We set θi = 0 for i = 1, …, p − 5, the remaining 5 coefficients to (0.6, 1.2, 1.8, 2.4, 3) and residual variances ϕ = 1, 4, 8. Covariates were sampled from x ~ N(0, Σ), where Σii = 1 and all correlations set to ρ = 0 or ρ = 0.25. We remark that ρ are population correlations, the maximum sample correlations when ρ = 0 were 0.37, 0.44, 0.47 for p = 100, 500, 1000 (respectively), and 0.54, 0.60, 0.62 when ρ = 0.25. We simulated 1,000 data sets under each setup.
Figure 3 shows sum of squared errors (SSE) averaged across simulations for ϕ = 1, 4, 8, ρ = 0, 0.25. pMOM and piMOM perform similarly and present a lower SSE as p grows than other methods in all scenarios. To obtain more insight on how the lower SSE is achieved, Supplementary Figures 2–3 show SSE separately for θi = 0 (left) and θi ≠ 0 (right). The largest differences between methods were observed for θi = 0, the performance of pMOM and piMOM coming closer for smaller signal-to-noise ratios . For θi ≠ 0 differences in SSE are smaller, iMOM slightly outperforming MOM. For all methods as decrease the SSE worsens relative to the oracle least squares (Supplementary Figures 2–3, right panels, black horizontal segments).
Figure 3.
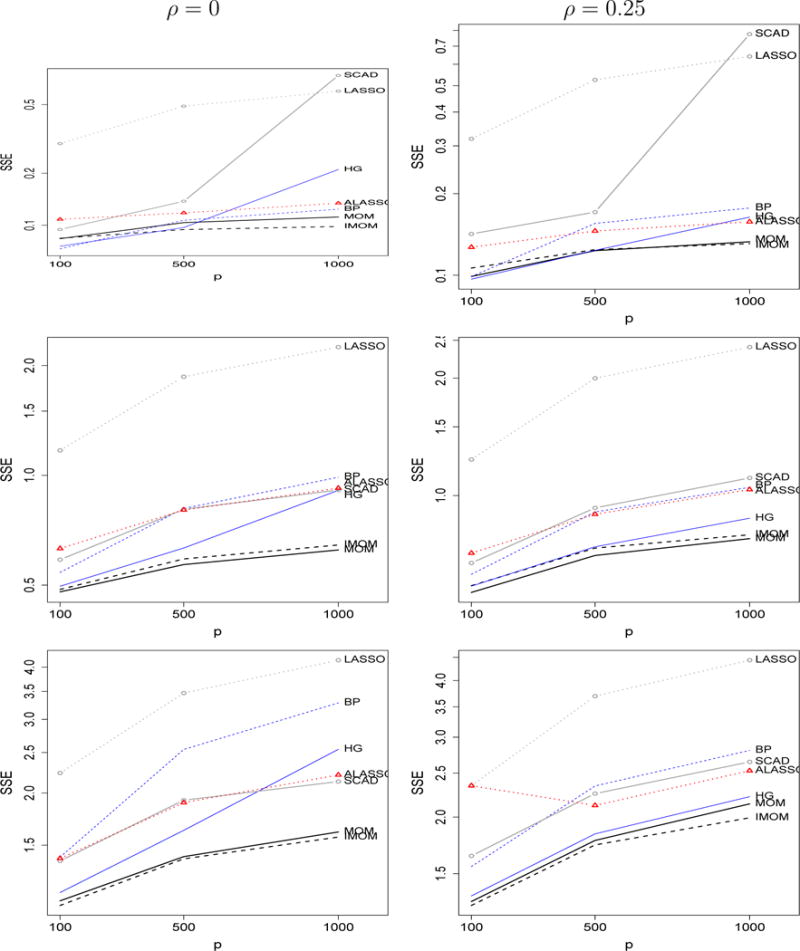
Mean SSE when ϕ = 1, 4, 8 (top, middle, bottom), ρ = 0, 0.25 (left, right). Simulation settings: n = 100, p = 100, 500, 1000 and 5 non-zero coefficients 0.6, 1.2, 1.8, 2.4, 3.0.
5.2.2. Growing p, θ = O(n−1/4)
We extend the simulations by considering p = 100, 500, 1000 and ρ = 0, 0.25 as before in a setting with vanishing θ = O(n−1/4). Specifically, we set n = 100, 250, 500 for p = 100, 500, 1000 (respectively), θi = 0 for i = 1, …, p − 5 as before and the remaining 5 coefficients to n−1/4(0.6, 1.2, 1.8, 2.4, 3) and ϕ = 1. The goal is to investigate if NLP shrinkage rate comes at a cost of reduced precision when the coefficients are truly small. Note that n−1/4 is only slightly larger than the n−1/2 error of the MLE, and hence represents fairly small coefficients.
Figure 4 shows the total SSE and Supplementary Figure 4 that for zero (left) and non-zero (right) coefficients. MOM and iMOM present the lowest overall SSE in most situations but HG and ALASSO achieve similar performance, certainly closer than the earlier sparser scenario with fixed θ, n = 100 and growing p.
Figure 4.
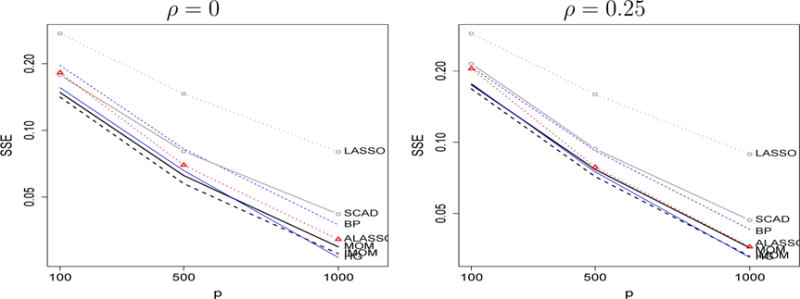
Mean SSE when non-zero θ = n−1/4 (0.6, 1.2, 1.8, 2.4, 3.0), ρ = 0, 0.25 (left, right), ϕ = 1. Simulation settings: (n = 100, p = 100), (n = 250, p = 500), (n = 500, p = 1000)
Because NLPs assign high prior density to a certain range of values, we conducted a further study when θ contains an ample range of non-zero coefficients (i.e. both large and small). To this end, we set n = 100, 250, 500 for p = 100, 500, 1000 with ϕ = 1 as before, θi = 0 for i = 1, …, p − 11, vanishing (θp−10, …, θp−6) = n−1/4 (0.6, 1.2, 1.8, 2.4, 3) and fixed (θp−5, …, θp) = (0.6, 1.2, 1.8, 2.4, 3). Figure 5 shows the overall MSE and Supplementary Figure 5 that for θi = 0 and θi ≠ 0 separately. The lowest overall MSE is achieved by iMOM and MOM, followed by HG and BP, whereas ALASSO is less competitive than in the earlier simulations where all θi = O(n−1/4). Overall, these results support that NLPs remain competitive even with small signals and that their performance relative to competing methods is best in sparse situations, agreeing with our theoretical findings.
Figure 5.
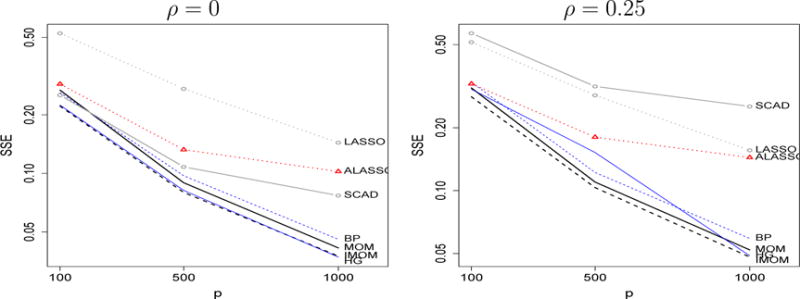
Mean SSE when non-zero (θp−10, …, θp−6) = n−1/4(0.6, 1.2, 1.8, 2.4, 3), (θp−5, …, θp) = (0.6, 1.2, 1.8.2.4, 3) and ρ = 0, 0.25 (left, right), ϕ = 1. Simulation settings: (n = 100, p = 100), (n = 250, p = 500), (n = 500, p = 1000)
5.3. Gene expression data
We assess predictive performance in high-dimensional gene expression data. (Calon et al., 2012) used mice experiments to identify 172 genes potentially related to the gene TGFB, and showed that these were related to colon cancer progression in an independent data set with n = 262 human patients. TGFB plays a crucial role in colon cancer and it is important to understand its relation to other genes. Our goal is to predict TGFB in the human data, first using only the p = 172 genes and then adding 10,000 extra genes that we selected randomly from the 18,178 genes with distinct Entrez identifier contained in the experiment. Their absolute Pearson correlations with the 172 genes ranged from 0 to 0.892 with 95% of them being in (0.003,0.309). Both response and predictors were standardized to zero mean and unit variance (data and R code in Supplementary Material). We assessed predictive performance via the leave-one-out cross-validated R2 coefficient between predictions and observations. For Bayesian methods we report the posterior expected number of variables in the model (i.e. the mean number of predictors used by BMA), and for SCAD and LASSO the number of selected variables.
Table 1 shows the results. For p = 172 all methods achieve similar R2, that for LASSO being slightly higher, although pMOM, piMOM and BP used substantially less predictors. These results appear reasonable in a moderately dimensional setting where genes are expected to be related to TGFB. However, when using p = 10, 172 predictors important differences between methods are observed. The BMA estimates based on pMOM and piMOM remain parsimonious (6.5 and 10.3 predictors, respectively) and the cross-validated R2 increases roughly to 0.62. The BP prior dispersion parameter g = 1722 induces strong parsimony, though relative to NLPs the non-selectiveness of this penalty causes some loss of prediction power (R2 = 0.586). For the remaining methods the number of predictors increased sharply and R2 did not improve relative to the p = 172 case. Predictors with large marginal inclusion probabilities in pMOM/piMOM included genes related to various cancer types (ESM1, GAS1, HIC1, CILP, ARL4C, PCGF2), TGFB regulators (FAM89B) or AOC3 which is used to alleviate certain cancer symptoms. These findings suggest that NLPs effectively detected a parsimonious subset of predictors in this high-dimensional example. We also note that computation times were highly competitive. BP and NLPs are programmed in mombf in an identical manner (piMOM has no closed-form expressions, hence the higher time) whereas HG is implemented in BAS with a slightly more advanced MCMC model search algorithm (e.g. pre-ranking variables and considering swaps). NLPs focus P (Mk | yn) on smaller models, which alleviates the cost required by matrix inversions (non-linear in the model size). NLPs also concentrate P (Mk | yn) on a smaller subset of models, which tend to be revisited and hence the marginal likelihood need not be recomputed. Regarding the efficiency of our posterior sampler for (θ, ϕ), we ran 10 independent chains with 1,000 iterations each and obtained mean serial correlations of 0.32 (pMOM) and 0.26 (piMOM) across all non-zero coefficients. The mean correlation between Ê(θ | yn) across all chain pairs was > 0.99 (pMOM and piMOM). Supplementary Section 5 contains further convergence assessments.
6. Discussion
We showed how combining BMA with NLPs gives a coherent joint framework encouraging model selection parsimony and selective shrinkage for spurious coefficients. Beyond theory, the latent truncation construction motivates NLPs from first principles, adds flexibility in prior choice and enables effective posterior sampling even under strong multi-modalities. We obtained strong results when p ≫ n in simulations and gene expression data, with parsimonious models achieving accurate cross-validated predictions and good computation times. Note that these did not require procedures to pre-screen covariates, which can cause a loss of detection power. Interestingly, NLPs achieved low estimation error even in settings with vanishing coefficients: their slightly higher SSE for active coefficients was compensated by a lower SSE for inactive coefficients. That is, NLPs can be advantageous even with sparse vanishing θ, although of course they may be less competitive in non-sparse situations. An important point is that inducing sparsity via P (Mk) (e.g. Beta-Binomial) or vague π(θk | Mk) (e.g. the BP) also performed reasonably well, although relative to the NLP data-adaptive sparsity there can be a loss of detection power.
Our results show that it is not only possible to use the same prior for estimation and selection, but may indeed be desirable. We remark that we used default informative priors, which are relatively popular for testing, but perhaps less readily adopted for estimation. Developing objective Bayes strategies to set the prior parameters is an interesting venue for future research, as well as determining shrinkage rates in more general p ≫ n cases, and adapting the latent truncation construction beyond linear regression, e.g. generalized linear, graphical or mixture models.
Supplementary Material
Acknowledgments
Both authors were partially funded by the NIH grant R01 CA158113-01. We thank Merlise Clyde for providing the BAS package.
References
- Bhattacharya A, Pati D, Pillai NS, Dunson DB. Bayesian shrinkage Technical report. arXiv preprint arXiv:1212.6088. 2012 [Google Scholar]
- Calon A, Espinet E, Palomo-Ponce S, Tauriello DVF, Iglesias M, Céspedes MV, Sevillano M, Nadal C, Jung P, Zhang XHF, Byrom D, Riera A, Rossell D, Mangues R, Massague J, Sancho E, Batlle E. Dependency of colorectal cancer on a tgf-beta-driven programme in stromal cells for metastasis initiation. Cancer Cell. 2012;22(5):571–584. doi: 10.1016/j.ccr.2012.08.013. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Castillo I, Van der Vaart AW. Needles and straw in a haystack: Posterior concentration for possibly sparse sequences. The Annals of Statistics. 2012;40(4):2069–2101. [Google Scholar]
- Castillo I, Schmidt-Hieber J, van der Vaart AW. Bayesian linear regression with sparse priors. Technical report, arXiv preprint arXiv:1403.0735. 2014 [Google Scholar]
- Chen J, Chen Z. Extended Bayesian information criteria for model selection with large model spaces. Biometrika. 2008;95(3):759–771. [Google Scholar]
- Consonni G, La Rocca L. On moment priors for Bayesian model choice with applications to directed acyclic graphs. In: Bernardo JM, Bayarri MJ, Berger JO, Dawid AP, Heckerman D, Smith AFM, West M, editors. Bayesian Statistics 9 - Proceedings of the ninth Valencia international meeting. Oxford University Press; 2010. pp. 119–144. [Google Scholar]
- Dawid AP. The trouble with Bayes factors Technical report. University College London; 1999. [Google Scholar]
- Fan J, Li R. Variable selection via nonconcave penalized likelihood and its oracle properties. Journal of the American Statistical Association. 2001;96:1348–1360. [Google Scholar]
- Fan J, Lv J. A selective overview of variable selection in high dimensional feature space. Statistica Sinica. 2010;20:101–140. [PMC free article] [PubMed] [Google Scholar]
- Fernández C, Ley E, Steel MFJ. Benchmark priors for Bayesian model averaging. Journal of Econometrics. 2001;100:381–427. [Google Scholar]
- Gelfand AE, Ghosh SK. Model choice: A minimum posterior predictive loss approach. Biometrika. 1998;85:1–11. [Google Scholar]
- Johnson VE, Rossell D. Prior densities for default Bayesian hypothesis tests. Journal of the Royal Statistical Society B. 2010;72:143–170. [Google Scholar]
- Johnson VE, Rossell D. Bayesian model selection in high-dimensional settings. Journal of the American Statistical Association. 2012;24(498):649–660. doi: 10.1080/01621459.2012.682536. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Kotecha JH, Djuric PM. Proceedings, 1999 IEEE International Conference on Acoustics, Speech and Signal Processing. IEEE Computer Society; 1999. Gibbs sampling approach for generation of truncated multivariate gaussian random variables; pp. 1757–1760. [Google Scholar]
- Lai TL, Robbins H, Wei CZ. Strong consistency of least squares in multiple regression. Journal of multivariate analysis. 1979;9:343–361. [Google Scholar]
- Liang F, Paulo R, Molina G, Clyde MA, Berger JO. Mixtures of g-priors for Bayesian variable selection. Journal of the American Statistical Association. 2008;103:410–423. [Google Scholar]
- Liang F, Song Q, Yu K. Bayesian modeling for high-dimensional generalized linear models. Journal of the American Statistical Association. 2013;108(502):589–606. [Google Scholar]
- Martin R, Walker SG. Asymptotically minimax empirical bayes estimation of a sparse normal mean vector. Technical report. 2013 arXiv preprint arXiv:1304.7366. [Google Scholar]
- Narisetty NN, He X. Bayesian variable selection with shrinking and diffusing priors. The Annals of Statistics. 2014;42(2):789–817. [Google Scholar]
- Redner R. Note on the consistency of the maximum likelihood estimator for nonidentifiable distributions. Annals of Statistics. 1981;9(1):225–228. [Google Scholar]
- Rodriguez-Yam G, Davis RA, Scharf LL. PhD thesis. Department of Statistics, Colorado State University; 2004. Efficient Gibbs sampling of truncated multivariate normal with application to constrained linear regression. [Google Scholar]
- Rossell D, Telesca D, Johnson VE. Statistical Models for Data Analysis XV. Springer; 2013. High-dimensional Bayesian classifiers using non-local priors; pp. 305–314. [Google Scholar]
- Rousseau J. Approximating interval hypothesis: p-values and Bayes factors. In: Bernardo JM, Bayarri MJ, Berger JO, Dawid AP, editors. Bayesian Statistics. Vol. 8. Oxford University Press; 2007. pp. 417–452. [Google Scholar]
- Shin M, Bhattacharya A, Johnson VE. Scalable Bayesian variable selection using nonlocal prior densities in ultrahigh-dimensional settings. arXiv. 2015:1–33. doi: 10.5705/ss.202016.0167. http://arxiv.org/abs/1507.07106. [DOI] [PMC free article] [PubMed]
- Springer MD, Thompson WE. The distribution of products of beta, gamma and gaussian random variables. SIAM Journal of Applied Mathematics. 1970;18(4):721–737. [Google Scholar]
- Tibshirani R. Regression shrinkage and selection via the Lasso. Journal of the Royal Statistical Society, B. 1996;58:267–288. [Google Scholar]
- Verdinelli I, Wasserman L. Bayes factors, nuisance parameters and imprecise tests. In: Bernardo JM, Berger JO, Dawid AP, Smith AFM, editors. Bayesian Statistics. Vol. 5. Oxford University Press; 1996. pp. 765–771. [Google Scholar]
- Walker AM. On the asymptotic behaviour of posterior distributions. Jornal of the Royal Statistical Society B. 1969;31(1):80–88. [Google Scholar]
- Wilhelm S, Manjunath BG. tmvtnorm: a package for the truncated multivariate normal distribution. The R Journal. 2010;2:25–29. [Google Scholar]
- Zhou H. The adaptive LASSO and its oracle properties. Journal of the American Statistical Association. 2006;101(476):1418–1429. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.