

Abstract
A major problem for evolutionary theory is understanding the so-called open-ended nature of evolutionary change, from its definition to its origins. Open-ended evolution (OEE) refers to the unbounded increase in complexity that seems to characterize evolution on multiple scales. This property seems to be a characteristic feature of biological and technological evolution and is strongly tied to the generative potential associated with combinatorics, which allows the system to grow and expand their available state spaces. Interestingly, many complex systems presumably displaying OEE, from language to proteins, share a common statistical property: the presence of Zipf’s Law. Given an inventory of basic items (such as words or protein domains) required to build more complex structures (sentences or proteins) Zipf’s Law tells us that most of these elements are rare whereas a few of them are extremely common. Using algorithmic information theory, in this paper we provide a fundamental definition for open-endedness, which can be understood as postulates. Its statistical counterpart, based on standard Shannon information theory, has the structure of a variational problem which is shown to lead to Zipf’s Law as the expected consequence of an evolutionary process displaying OEE. We further explore the problem of information conservation through an OEE process and we conclude that statistical information (standard Shannon information) is not conserved, resulting in the paradoxical situation in which the increase of information content has the effect of erasing itself. We prove that this paradox is solved if we consider non-statistical forms of information. This last result implies that standard information theory may not be a suitable theoretical framework to explore the persistence and increase of the information content in OEE systems.
Keywords: complexity, algorithmic complexity, open-ended evolution, Zipf’s Law
1. Introduction
Life has been evolving on our planet over billions of years, undergoing several major transitions along with multiple events of both slow and rapid change affecting structure and function [1–4]. Life seems to be indefinitely capable of increasing in complexity. This is illustrated, as an instance, by the trend towards larger genomes and diverse cell types exhibited by multicellular organisms. Moreover, the emergence of high neuronal plasticity and complex communication provided the substrate for non-genetic modes of adaptation. A key concept that pervades many of these innovations is the idea that evolution is ‘open-ended’. Following [5], open-ended evolution (OEE) can be defined as follows: ‘a process in which there is the possibility for an indefinite increase in complexity.’ What kind of systems can exhibit such unbounded growth in complexity [6]? What are the conditions under which the complexity—and thus, the information content of the system—can increase and what are the footprints of such an open-ended increase of complexity? Which kind of information is encoded in an OEE system? The aim of this paper is to give hints to the these questions.
Open-ended evolutionary change needs a dynamical behaviour allowing complexity to grow in an unbounded way [5,7]. This requires a very large exploration space but this is only a necessary requirement. For example, as noticed in [8] mathematical models used in population genetics involving infinite alleles—using Markov models—do not display OEE. Previous attempts to address the problem of OEE involved different approximations and degrees of abstraction. John von Neumann was one of the early contributors to this issue [5,9,10]. In all these studies, some underlying mechanism is assumed to be operating, and arguments are made concerning the presence of self-replication, genotype–phenotype mappings, special classes of material substrates and physico-chemical processes [5,11]. On the other hand, a theory of OEE might demand a revision of the role of novel niches and abiotic changes, as well as refining what we understand as the open-endedness of a system [12,13]. Special suitable candidates for OEE systems are complex systems exhibiting generative rules and recursion. The best-known case is human language. Thanks to recursion, syntactic rules are able to produce infinite well-formed structures and thereby the number of potential sentences in a given language is unbounded [14]. In another example, Darwinian evolution proceeds through tinkering [15,16], continuously reusing existing parts. These are first copied—hence bringing in some redundancy into evolving systems—but are later on modified through mutation or recombination. Despite the obvious differences existing between Darwinism in biology and human-guided engineering [15], this process of tinkering appears to be common too in the growth of technological systems, thus indicating that copy-and-paste dynamics might be more fundamental than expected [17].
These systems are very different in their constitutive components, dynamics and scale. However, all share the presence of a common statistical pattern linked to their diversity: fat-tailed distributions. Four examples are provided in figure 1. In all these cases, the frequency distribution of the basic units decays following approximately Zipf’s Law. Zipf’s Law was first reported for the distribution of city sizes [21], and then popularized as a prominent statistical regularity widespread across all human languages: in a huge range of the vocabulary, the frequency of any word is inversely proportional to its rank [22,23]. Specifically, if we rank all the occurrences of words in a text from the most common word to the less common one, Zipf’s Law states that the probability p(si) that in a random trial we find the ith most common word si (with i = 1, …, n) falls off as
| 1.1 |
with γ ≈ 1 and Z the normalization constant, i.e. . Stated otherwise, the most frequent word will appear twice as often as the second most frequent word, three times as often as the third one, and so on. This pattern is found in many different contexts and can emerge under different types of dynamical rules (see [23–27] and references therein).
Figure 1.

Zipf’s Law distributions are commonly found in very different systems candidates to display open-endedness. Here, we show several examples of scaling behaviour involving (a) LEGO systems, (b) written language and (c) proteins. In (a), we display (in log scale) the probability of finding the ith most abundant type of LEGO brick within a very large number of systems (see details in [18]). In (b), the log-scale rank-size distribution of Herman Melville’s Moby Dick is displayed. The dashed line shows the frequency versus rank for words having length 5, which is the average length of words in this particular book. The plot displayed in (c) shows, with linear axes, the corresponding rank distribution of protein folds in a large protein database (redrawn from [19]). The line is a power-law fit. Here the names of some of the domains, which are associated with particular functional traits, are indicated. (d) Zipf’s Law in the frequency of logic modules used in evolved complex circuits (adapted from [20]).
The examples shown in figure 1 involve: (a) LEGO® models, (b) human language, (c) proteins, and (d) evolved electronic circuits. The first example provides an illustration of structures emerging through copy–paste and combination in a non-biological setting. This toy system allows exploitation of the intrinsic combinatorial explosion associated with the multiple ways in which different bricks can be interlinked. In figure 1a, we plot the number of times that each type of brick occurred within a very large dataset of LEGO models [18]. The rank plot reveals that some simple bricks—as those shown in figure 1a, right—are extremely common whereas most bricks, having more complex shapes and larger size, are rare. The analysis showed that the statistical distribution can be well fitted using a generalized form of equation (1.1) known as the Pareto–Zipf distribution. This reads
| 1.2 |
where Z is again the corresponding normalization and i0 a new parameter that allows us to take into account the curvature for small i-values. This picture is similar to the one reported from the study of large written corpora, as illustrated in figure 1b [28]. Our third example is given by the so-called protein domains, which are considered the building blocks of protein organization and an essential ingredient to understand the large-scale evolution of biological complexity [29–32]. Here each protein domain—or fold—is characterized by its essentially independent potential for folding in a stable way and each protein can be understood as a combination of one, two or more domains. In figure 1c, the rank distribution of observed folds from a large protein database is displayed. Domains define the combinatorial fabric of the protein universe and their number, although finite, has been increasing through evolution [31]. The fourth example gives the frequency of use of four-element modules within complex circuits [20].
The repertoire of LEGO® bricks, words, protein domains and circuit modules provide the raw materials to combinatorial construction, but they also share the underlying presence of grammar, to be understood here as the compact description of a language. As indicated in [18], if we treat pieces of LEGO® as words and models as utterances, LEGO® appears as a class of artificial language and the resulting structures are passed from generation to generation through cultural transmission. This is of course a largely metaphoric picture, since the final outcome of the combinatorics is usually a non-functional design, unbounded by the potential combinations but not by functional constraints. This might actually be the reason why its statistical distribution, described by equation (1.2) deviates from equation (1.1). Protein domains too exhibit a grammar in which a set of generative rules for combining the available folds provides an explanatory mechanism for the observed repertoire of protein structures [19,33,34]. In summary, these systems—and others like electronic circuits or genomes, molecular networks [35–37] and complex circuits [38] and even evolved technology [39]—are characterized by a growth process that is expanding their inventories over time, the presence of generative rules allowing new structures to emerge, and a common statistical pattern described by Zipf’s Law.
In this paper, we provide a general definition, or postulates of OEE based on algorithmic information theory (AIT), and we show that the common presence of Zipf’s Law in these seemingly disparate systems may be deeply connected to their potentially open-ended nature. Furthermore, we explore the consequences that OEE has for the conservation of information, identifying the information loss paradox in OEE systems. This paradoxical situation, in which the system loses all its past information in the long run, even though the step-by-step information transmission is maximized, is shown to be a problem of the statistical nature of Shannon information theory. Indeed, we prove that, in the general setting of AIT, information can be conserved and systems can grow without bounds without removing the traces of its past. Therefore, the general study of OEE systems must be framed in a theoretical construct not based on standard information theory, but in a much more general one, inspired in non-statistical forms of information content. We finally observe that the connection of fundamental results of computation theory, and even Gödel’s incompleteness theorem, with general problems of evolutionary theory has been approached before in [8,40,41].
2. Algorithmic information theory
AIT [42–52] is a natural framework to address the problem of OEE. It incorporates powerful (still unexplored) tools to model the complexity of living systems, which, for example, has often been associated with information storage in the genome [40,48]. Such information results from the growth of genome complexity through both gene duplication and the interactions with the external world and is (by definition) a path-dependent process. Here we consider that we encode our evolving system into strings of symbols. We assume that, as long as the system evolves, such descriptions can grow and change, in a path-dependent way. As we shall see, the derived abstract framework is completely general, and applies to any system susceptible of displaying OEE.
A natural question arises when adopting such an abstract framework: why are we using Kolmogorov Complexity for our approach to OEE? The first reason is that it is based on strings obtained from a given alphabet, which naturally connects with a representation based on sequences [48] such as those in some of our examples from figure 1. Second, it connects with information theory (which is the most suitable coarse-grained first approximation to biology [53]) resulting in a more fundamental framework. Third, it consistently distinguishes predictable from unpredictable sequences in a meaningful way, and how these scale with size. Finally, the algorithmic definition based on the use of a program matches our intuition that evolution can be captured by some computational picture.
Let us first introduce a key concept required for our analysis: Kolmogorov—or algorithmic—complexity, independently developed by Kolmogorov [45], Somolonoff [46] and Chaitin [47]. Roughly speaking, if a given process can be described in terms of a string of bits, the complexity of this string can be measured as the shortest computer program capable of generating it [49,50]. The underlying intuition behind this picture—see figure 2—is that simple, predictable strings, such as 10101010101010 … can be easily obtained from a small piece of code that essentially says ‘write “10”’ followed by ‘repeat’ as many times as needed. This would correspond to a regular system, such as a pendulum or an electronic oscillator—see figure 2a,b—and the simple dynamical pattern is reproduced by a short program. Instead, a random string generated by means of a coin toss (say 0100110011101101011010 …) would only be reproduced by using a program that writes exactly that sequence and is thus as long as the string itself—figure 2c,d. Other stochastic processes generating fluctuations—figure 2e,f —and represented as strings of n bits can be similarly described, and their complexity shall lie somewhere between both extremes.
Figure 2.

Measuring string complexity. If ℓ(p) is the length of the program, the Kolmogorov complexity K(x) is defined as the smallest program able to write x. Simple dynamical systems (a) such as oscillators produce predictable, simple strings (b) thus having a low complexity. On the other extreme (c), a coin toss creates a completely random sequence and the program (d) is such that K(x) = ℓ(x). A system exhibiting broad distributions (e–f) and a large set of states is also likely to display high K(x).
The stochasticity inherent to the most algorithmically complex strings (e.g. a coin toss, as introduced above) invites us to think in terms of statistical or information entropy. But the Kolmogorov complexity is, conceptually, a more fundamental measure of the complexity of such processes [51,52]. A formal definition follows. Let x and p be finite binary strings of length ℓ(x) and ℓ(p), respectively. Let be a universal Turing machine. Note that a finite binary string p can define the computations that a universal Turing machine [54] will implement when p is fed as an input—i.e. it can define programs executed by the Turing machine. We will consider a set of prefix free programs: in such a set of programs, no program is the prefix of another program. This property is crucial for most of the results of AIT or even standard information theory [51,52]. Let denote the output of the computer when running the program p. Considering now all possible programs p that produce x as an output when fed into , the (prefix free) Kolmogorov complexity of the string x with respect to the universal computer is defined as [51]
| 2.1 |
This quantity is computer independent up to an additive constant [51,52] so we will omit the subindex when referring to it. If x is a random string, we would have a simple relation:
| 2.2 |
since all ℓ(x) bits need to be included, and we say that the sequence x is incompressible.
In addition, and as it happens with the statistical entropy, one can define the conditional algorithmic complexity as follows: let x, y and p be finite binary strings again and let be a universal Turing machine to which a description of y has already been made available. The Kolmogorov complexity of x given y is the length of the shortest program p that, when applied to a universal Turing machine, modifies y to display x as an output
| 2.3 |
Notice that even though K(x) can be arbitrarily large, K(x|y) accounts for the minimum program that knows the differences between x and y and amends them.1
3. General conditions for open-ended evolution: postulates
We shall concern ourselves with dynamic systems whose description can be made in terms of finite binary strings σt at each time step t over evolutionary time. The complexity of such an object at time t is given by K(σt). This object shall evolve through intermediate steps in a path-dependent manner; thus the quantities K(σt), K(σt+Δt) and K(σt+Δt|σt) and the relationships between them will play a paramount role.
Let σt be the description of the system at time t. Let the sequence Σ(t) ≡ {σ1, σ2, …, σt} be the history of the system until time t in arbitrary time units. We want the process that builds σt to be an open-ended evolutionary one, hence we turn our attention to the complexity of its evolutionary history Σ(t). A minimal condition that this historical process has to obey to be called open-ended is that its complexity (properly normalized) always increases:
Axiom 3.1 Open-endedness. —
We say that the process that generates σt is open-ended if
3.1 for all t = 1, …, ∞.
Of all open-ended processes that obey equation (3.1), we are interested in those whose complexity is not bounded:
Axiom 3.2 Unboundedness. —
We say that the process generating σt has an unbounded complexity if for any natural number there is a time t such that
3.2
These two axioms imply that information is always being added by the generative process in the long term—hence more bits are needed to describe later stages of the evolutionary history. The knowledge of the history up to time t is not enough to predict what will happen next. If it were, the description of later stages of the evolutionary history would be implicit in the description of the history at time t, and axiom 3.1 would be violated. Equation (3.2) also implies that the information of the processes we are interested in will never converge, eventually diverging for large times. These equations do not impose any condition on the complexity of the system at a given time step. Notably, (i) they admit a situation in which the description of the system—but not of its history—drops (K(σt) > K(σt+1), which might happen in biology [55], see also figure S1) and (ii) they do not imply any connection between states σt and σt+1. This second point is possible because we have not requested yet that this is an evolutionary process. We would hardly call a process ‘evolutionary’ if its successive steps are completely unrelated, hence:
Axiom 3.3 Heredity principle. —
Evolutionary processes attempt to minimize the action
3.3
That is, evolutionary processes try to minimize the amount of operations implemented to move the system from one state to the next, under whichever other constraints might apply. In the case of open-ended evolutionary systems, they try to minimize the number of operations needed to unfold in time while always increasing the informational content of the evolutionary history (as equations (3.1) and (3.2) demand). We could apply the same axiom, say, to Darwinian evolutionary processes saying that they attempt to minimize equation (3.3) subjected to random mutation and selection. (Note that this has no saying on whether Darwinian processes are inherently open-ended or not.) Axiom 3.3 defines an AIT-based least action principle that imposes that the information carried between successive steps is maximized as much as other constraints allow, thus turning the generative process into a path-dependent one. Without the Heredity principle, we could end up with a sequence of totally unrelated objects—i.e. a purely random, unstructured process hardly interpretable as an evolving system.
We take these axioms as our most general postulates of OEE. Note how they capture a very subtle, blurry tension between memory, to preserve past configurations and the system’s ability to innovate, thus always adding new information that can upset established structures. As other authors have hinted at [5,12,13], OEE phenomenology seems to emerge out of this conflict, which is also familiar in other aspects of complex and critical systems, designs and behaviours [56–58]. These are often described by a compromise, the ‘edge of chaos’, between unchanging, ordered states and structureless, disordered configurations.
In a nutshell, our working definition of open-endedness implies that the size of the algorithm describing the history of the system does not converge in time. Therefore, even if every evolutionary stage accepts a finite algorithm as a description, the evolutionary path is asymptotically uncomputable. These postulates are assumed to be satisfied by all open-ended systems. However, they turn out to be too generic to extract conclusions of how OEE systems may behave or which kind of observable footprints are expected from them. To gain a greater insight about the effects of OEE we can study a strong version of these postulates that applies not to evolutionary histories, but to objects themselves. Hence we demand that:
| 3.4 |
at any t = 1, …, ∞ and that for every natural number there is a time t such that
| 3.5 |
Also, in the strong version of OEE the action:
| 3.6 |
is minimized, constrained by equations (3.4) and (3.5). As before, S(σt → σt+1) denotes an informational entropy—or missing information—when inferring σt+1 from σt. We know from [49] that this quantity is bounded by
| 3.7 |
As discussed before, the general OEE postulates—equations (3.1)–(3.3)—allow for the complexity of σt to drop, so such processes are not necessarily OEE in the strong sense defined by equations (3.4)–(3.6). However, it can be proved that every unbounded OEE process in the general sense must contain an unbounded OEE process in the strong sense—see the electronic supplementary material. That is, the strong version of OEE still can teach us something about the footprints of open-ended evolution.
4. Statistical systems: a variational approach to open-ended evolution
We will explore now the consequences of the definition stated above for systems that accept a description—possibly partial—in terms of statistical ensembles. The aim is to write the three conditions for OEE described by equations (3.4)–(3.6) in the language of statistical information theory. We will assume now that the statistical properties of this very finite string σt are themselves accurately accounted for by a random variable Xt. In other words: we consider that the string σt as a sequence of observations at the system at time t. This will provide a description of the system, in terms of observable states, at time t. We further consider that such a description of the system is the outcome of a random variable Xt. Then, the algorithmic complexity K(σt) is of the order of the Shannon entropy H(Xt) associated with the random variable Xt [51,52]:
Recall that this is the minimal information required to describe the behaviour of a single outcome of Xt, not a a sequence of trials of the random variable Xt.2 This random variable will represent an observation or realization of the system. Assume that we discretize the time, so we use the subscript n or m instead of t, and that we label the states i = 1, …, n. Now let us define the following family of nested subsets:
The open-ended evolutionary process will traverse the above family of nested subsets, adding a new state per evolutionary time step. We now define a sequence of different random variables
such that Xk takes values over the set Ωk and follows the probability distribution pk(1), …, pk(k), with . Then
The variational principle derived from the path-dependent process implies now the minimization of the conditional entropy of the random variable Xn+1 given the random variable Xn, namely
where . We will finally assume (without loss of generality) that the probability distributions p2, …, pn are sorted in decreasing order, i.e.:
In the electronic supplementary material, we discuss the conditions under which the consecutive achievement of ordered probability distributions is possible.
Therefore, for statistical systems, the previous constraints for open-endedness from equations (3.4) and (3.5) must now be rewritten as follows: first,
| 4.1 |
and, for any , there will be a n such that
| 4.2 |
In addition, the path dependence condition stated in equation (3.6) implies that:
| 4.3 |
In summary, we took a set of conditions, described by equations (3.4)–(3.6), valid in the general AIT framework, and we have re-written them in terms of statistical entropy functions through equations (4.1)–(4.3). We finally observe that the condition that the probability distribution must be strictly ordered leads to
Accordingly, the case of total randomness (fair coin toss) is removed.
4.1. Minimizing the differences between shared states
Condition (4.3) is difficult to handle directly. Nevertheless, it can be approached as follows: we first find a minimum by extremalizing a given Kullback–Leibler (KL) divergence, and then we will prove that this solution indeed converges to the absolute minimum of H(Xn+1|Xn).
Let us define the distribution as
is the probability that k < n + 1 appears when we draw the random variable Xn+1 excluding the outcomes = n + 1. Clearly, and pn are defined over the set Ωn, whereas pn+1 is defined over the set Ωn+1. Since the support sets for both and pn are the same, one can use the KL divergence defined as the relative entropy (or information gain) between pn and :
Now we impose the condition of path dependence as a variational principle over the KL divergence and then we write the following Lagrangian which defines the evolution of our system:
The minimization of this Lagrangian with respect to the variables upon which it depends imposes that
which implies that
| 4.4 |
By construction, 0 < θn+1 < 1. Equation (4.4) imposes that the conditional probabilities between Xn and Xn+1 read as
This defines a channel structure that leads to
| 4.5 |
being H(θn+1) the entropy of a Bernoulli process having parameter θn+1, i.e.:
In the electronic supplementary material, it is proven that
We thus have found the specific form of the conditional entropy governing the path dependency of the OEE system, imposed by equation (4.3).
We finally remark some observations related to the flow of information between past and present states. First, we note that, from equation (4.5), the relationship between the entropies of Xn and Xn+1 satisfies the following Fano’s-like equality:
| 4.6 |
Finally, from the definition of mutual information between Xn and Xn+1, one obtains:
and from equations (4.5) and (4.6) we arrive at the amount of information transmitted from the time step n to n + 1:
| 4.7 |
This is a good estimate of the maximum possible information transmitted per evolutionary time step. Nevertheless, even in this case, we shall see that the statistical information transmitted along time in an open-ended system has to face a paradoxical behaviour: the total loss of any past history in the long run—see §4.3.
4.2. Zipf’s Law: the footprint of OEE
As discussed at the beginning, a remarkably common feature of several systems known to exhibit OEE is the presence of Zipf’s Law. We will rely now on previous results [24,25] to show that the solution to the problem discussed above is given precisely by Zipf’s Law. We first note that, thanks to equation (4.4), the quotient between probabilities:
remains constant for all n as soon as pn(i + j) > 0. In the electronic supplementary material, following [25], we provide the demonstration that, in a very general case, the solution of our problem lies in the range defined by
It can be shown that δ → 0 if the size of the system is large enough. Therefore,
which leads us to the scaling distribution:
| 4.8 |
In other words, Zipf’s Law is the only asymptotic solution, which immediately suggests a deep connection between the potential for open-ended evolutionary dynamics and the presence of this particular power law. Note that Zipf’s Law is a necessary footprint of OEE, not a sufficient one: other mechanisms might imprint the same distribution [23]. We emphasize the remarkable property that this result is independent of the particular way the evolving system satisfies the OEE conditions imposed by equations (4.1)–(4.3).
4.3. The loss of information paradox in OEE
The above description of the evolution of open-ended statistical ensembles leads to an unexpected result: statistical systems displaying OEE lose any information of the past after a large period of complexity growing. Indeed, although information is conserved in a huge fraction step by step, it is not conserved at all if we compare large periods of evolution. Therefore, the capacity to generate an ensemble encoding an unbounded amount of information through evolution results in a total erasure of the past, even if a strong path dependency principle is at work (figure 3).
Figure 3.
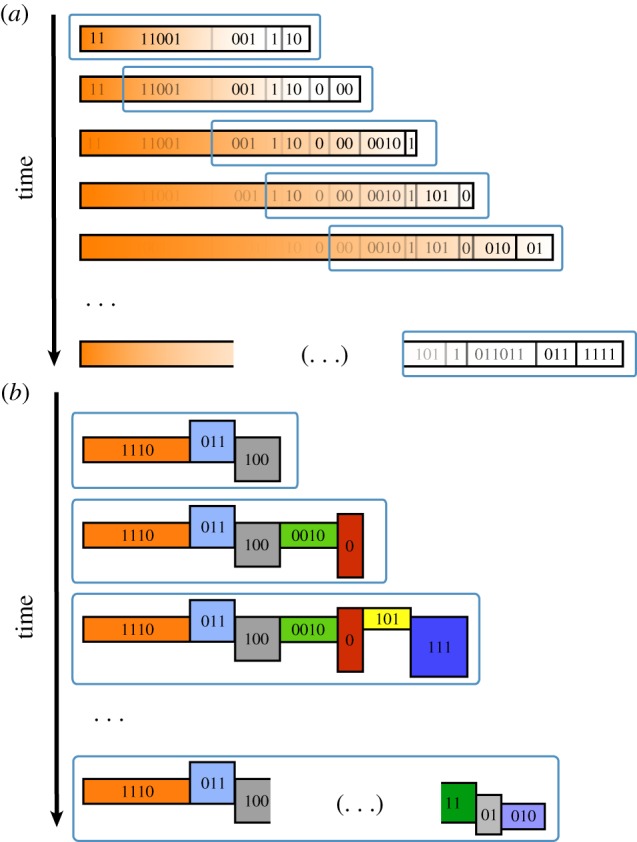
The paradox of information loss: (a) a statistical description of the system displays OEE. This means that, through time, the entropy of the ensemble grows without bounds. The consequence of that is that the information about the past history is totally erased as time goes by. Only a fraction of the history closer to the present survives. Therefore, there is no conservation of the information—see §4.3. (b) If our information is encoded in a non-statistical way, such as bit strings, it can be preserved. The historical information survives through evolutionary stages, even if the system displays OEE.
To see what happens with information along the evolutionary process in the limit of large n’s, we first rewrite mutual information between Xn and Xm, m < n as follows:
where, in this case, . Then we define the following constant Cm:
where the θk’s are the ones arising from equation (4.4). From here, one can prove—see the electronic supplementary material—that:
Now, observe that we can generalize equation (4.7) as follows:
This allows us to obtain the following chain of inequalities:
| 4.9 |
The above inequalities have an interesting consequence. Indeed, from equation (4.9), if Cn → ∞, then
| 4.10 |
In the electronic supplementary material, it is proven that, in OEE statistical systems, indeed we have that Cn → ∞. Thus, I(Xm : Xn) → 0: no statistical information is conserved in open-ended systems in the long term.
4.4. Solving the paradox: algorithmic information can be maintained
We have shown above that statistical information cannot be maintained through arbitrarily long evolutionary paths if the evolution is open-ended. The emphasis is on the word statistical. As we shall see, using a rather informal reasoning, other types of information based on the general setting of AIT can be maintained. Let σn be a description, in bits, of an object at time n and σN its description at time N > n. Let us assume that σN, in its most compressed form, can only be written as a concatenation of two descriptions, to be indicated with symbol ‘’:
Now assume that K(σN) = μN, K(σn) = μn and K(σN−n) = μ(N − n), with 0 < μ < 1. If πn is the minimal program that prints σn and πN−n is the minimal program that prints σN−n. Then, there is a program πN defined as
such that, when applied to a universal Turing machine, gives σN, i.e. . If we already know πn, it is clear that
We observe that, under the assumptions we made
so K(σN|σn) ≈ |K(σN) − K(σn)| close to the bound provided by Zurek [49], already used in equation (3.7). As we shall see, the immediate consequence of that is that the algorithmic mutual information between σN and σn does not depend on N. Let I(σN : σn) be the algorithmic mutual information between σN and σn:
Then, one has that:
we thus have
| 4.11 |
Within the AIT framework this implies that information of previous stages of the evolution can be maintained.
The result reported above has an important consequence: in an OEE system in which information is maintained, the information is encoded by generative rules that cannot be captured by simple statistical models. Therefore, Shannon information theory is of little use to understand the persistence of the memory of past states in OEE systems.
5. Discussion
In this paper, we have considered a new approach to a key problem within complex systems theory and evolution, namely, the conditions for open-ended evolution and its consequences. We provided a general formalization of the problem through a small set of postulates summarized by equations (3.1)–(3.6) based on the framework of AIT. Despite the high degree of abstraction—which allows us to extract very general results—important specific conclusions can be drawn: (i) in statistically describable systems, Zipf’s Law is the expected outcome of OEE. (ii) OEE systems have to face the statistical information loss paradox: Shannon information between different stages of the process tends to zero, and all information of the past is lost in the limit of large time periods. (iii) This paradoxical situation is solved when considering non-statistical forms of information, and we provided an example where algorithmic information between arbitrary time steps is maintained. This result, however, does not invalidate previous approaches of statistical information theory concerning the study of flows of information within the system [59], since our result refers to the structural complexity of the evolving entity. It is important to stress that information may unfold in several meanings or formal frameworks when talking about evolving systems. Moreover, further explorations should inquire into the role of information flows in keeping and promoting the increase of structural complexity of evolving systems. In addition, it is worth emphasizing that, at the current level of development, our framework might fail to incorporate some processes, such as exaptation or abiotic external drives, that are not fully algorithmic but identified as key actors in evolutionary systems [13]. All these issues are relevant in order to understand and eventually build OEE systems, as it is the case within the context of artificial life [12,60] by considering the possibility of building a system able to evolve under artificial conditions and maintain a constant source of creativity [61,62].
Since Zipf’s Law is the outcome of a statistical interpretation of the OEE postulates given in equations (3.1)–(3.6), one may be tempted to conclude that information is not conserved in those systems exhibiting Zipf’s Law in its statistical patterns. Instead, in line with the previous paragraph, it is important to stress that the statistical ensemble description can be just a partial picture of the system, and that other mechanisms of information prevalence, not necessarily statistic, are at work. Therefore, if our system exhibits Zipf’s Law and we have evidence of information conservation, the statistical pattern may be interpreted as the projection of other types of non-statistical information to the statistical observables.
Biological systems exhibit marked potential capacity for OEE resulting from their potential for growing and exploring new states and achieving novel functionalities. This open-endedness pervades the apparently unbounded exploration of the space of the possible. The two biological systems cited in the Introduction, namely human language and the protein universe, share the presence of an underlying grammar, which both enhances and constrains their combinatorial potential. Analogously, the example provided by models of evolution through gene duplication or tinkering revealed that scaling laws and other properties displayed by protein networks emerge from the amplification phenomena introduced by growth through copy-and-paste dynamics [63–65]. One way of doing this is provided by the tinkered nature of evolutionary change, where systems evolve by means of extensive reuse of previous parts to explore novel designs [15,16,32]. This mechanism fully matches our assumptions: generative rules that enable expansion of the state space, while the redundant nature of the process enables most of the previous structures to be kept. Again, our axioms capture this delicate balance between memory and innovation, order and disorder, that OEE systems seem to exploit as they unfold.
We reserve a final word for a general comment on the role of OEE in the theory of biology. Postulates described by equations (3.1)–(3.6) explicitly relate OEE to unpredictability. This, according to classic results like the no free lunch theorem [66], puts a question mark on the possibility of a theory of evolution in the sense of classical physics. This issue, discussed also in [8], may exclude the possibility of a predictive theory in terms of the explicit evolutionary innovations that will eventually emerge. Nevertheless, in this paper we prove that this is not an all-or-nothing situation: interestingly, the postulates of OEE, which rule out the existence of a predictive theory, are precisely the conditions that allow us to identify one of the possible statistical regularities—Zipf’s Law—governing such systems and thereby make predictions and, eventually, propose physical principles for them, adding a new, unexpected ingredient to the debate on predictability and evolution [67]. According to that, these principles would predict the statistical observables, but not the specific events that they represent.
Supplementary Material
Acknowledgements
We thank Jordi Piñero, Sergi Valverde, Jordi Fortuny, Kepa Ruiz-Mirazo, Carlos Rodríguez-Caso and the members of the Complex Systems Lab for useful discussions. B.C.-M. thanks Stefan Thurner, Rudolf Hanel, Peter Klimek, Vittorio Loretto and Vito DP Servedio for useful comments on previous versions of the manuscript.
Endotes
This quantity has been used as a conditional complexity within the context of evolved symbolic sequences [48]. In this case, K(s | e) referred to the length of the smallest program that gives the string s from a given environment e, also defined as a string.
Rigorously speaking, one should say that, if σ is the description in bits of the outcomes of N trials of Xt, then K(σ)/N → H(Xt).
Data accessibility
This article has no additional data.
Authors' contributions
B.C.-M., L.F.S. and R.S. contributed to the idea, development, and mathematical derivations in this paper. All three authors contributed to the writing and elaboration of figures.
Competing interests
We declare we have no competing interests.
Funding
This work has been supported by the Botín Foundation, by Banco Santander through its Santander Universities Global Division, a MINECO FIS2015-67616 fellowship, the Secretaria d’Universitats i Recerca del Departament d’Economia i Coneixement de la Generalitat de Catalunya (R.S. and L.F.S.) and the Santa Fe Institute (R.S.).
Reference
- 1.Maynard-Smith J, Szathmáry E. 1995. The major transitions in evolution. Oxford, UK: Oxford University Press. [Google Scholar]
- 2.Schuster P. 1996. How does complexity arise in evolution? Complexity 2, 22–30. ( 10.1002/(ISSN)1099-0526) [DOI] [Google Scholar]
- 3.Lane N. 2009. Life ascending: the ten great inventions of evolution. London, UK: Profile Books. [Google Scholar]
- 4.Solé R. 2016. Synthetic transitions: towards a new synthesis. Phil. Trans. R. Soc. B 371, 20150438 ( 10.1098/rstb.2015.0438) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5.Ruiz-Mirazo K, Umerez J, Moreno A. 2008. Enabling conditions for ‘open-ended’ evolution. Biol. Philos. 23, 67–85. ( 10.1007/s10539-007-9076-8) [DOI] [Google Scholar]
- 6.Bedau MA, McCaskill JS, Packard NH, Rasmussen S, Adami C, Green DG, Ikegami T, Kaneko K, Ray TS. 2000. Open problems in artificial life. Artif. Life 6, 363–376. ( 10.1162/106454600300103683) [DOI] [PubMed] [Google Scholar]
- 7.Nehaniv CL. 2000. Measuring evolvability as the rate of complexity increase. In Artificial Life VII Workshop Proc (eds Maley CC, Boudreau E), Portland, OR, pp. 55–57. New York, NY: MIT Press. [Google Scholar]
- 8.Day T. 2012. Computability, Gödel’s incompleteness theorem, and an inherent limit on the predictability of evolution. J. R. Soc. Interface 9, 624–639. ( 10.1098/rsif.2011.0479) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9.Von Neumann J, Burks AW. 1966. Theory of self-reproducing automata. IEEE Trans. Neural Networks 5, 3–14. [Google Scholar]
- 10.McMullin B. 2000. John von Neumann and the evolutionary growth of complexity: looking backward, looking forward. Artif. Life 6, 347–361. ( 10.1162/106454600300103674) [DOI] [PubMed] [Google Scholar]
- 11.Ruiz-Mirazo K, Peretó J, Moreno A. 2004. A universal definition of life: autonomy and open-ended evolution. Origins Life Evol. Biosph. 34, 323–346. ( 10.1023/B:ORIG.0000016440.53346.dc) [DOI] [PubMed] [Google Scholar]
- 12.Taylor T. et al. 2016. Open-ended evolution: perspectives from the OEE workshop in York. Artif. Life 22, 408–423. ( 10.1162/ARTL_a_00210) [DOI] [PubMed] [Google Scholar]
- 13.de Vladar HP, Santos M, Szathmáry E. 2017. Grand views of evolution. Trends Ecol. Evol. 32, 324–334. ( 10.1016/j.tree.2017.01.008) [DOI] [PubMed] [Google Scholar]
- 14.Hauser MD, Chomsky N, Fitch WT. 2002. The faculty of language: what is it, who has it and how did it evolve? Science 298, 1569–1579. ( 10.1126/science.298.5598.1569) [DOI] [PubMed] [Google Scholar]
- 15.Jacob F. 1977. Evolution as tinkering. Science 196, 1161–1166. ( 10.1126/science.860134) [DOI] [PubMed] [Google Scholar]
- 16.Solé RV, Ferrer R, Montoya JM, Valverde S. 2002. Selection, tinkering, and emergence in complex networks. Complexity 8, 20–33. ( 10.1002/cplx.v8:1) [DOI] [Google Scholar]
- 17.Solé RV, Valverde S, Casals MR, Kauffman SA, Farmer D, Eldredge N. 2013. The evolutionary ecology of technological innovations. Complexity 18, 15–27. ( 10.1002/cplx.v18.4) [DOI] [Google Scholar]
- 18.Crompton A. 2012. The entropy of LEGO. Environ. Planning B 39, 174–182. ( 10.1068/b37063) [DOI] [Google Scholar]
- 19.Searls DB. 2002. The language of genes. Nature 420, 211–217. ( 10.1038/nature01255) [DOI] [PubMed] [Google Scholar]
- 20.Raman K, Wagner A. 2011. The evolvability of programmable hardware. J. R. Soc. Interface 8, 269–281. ( 10.1098/rsif.2010.0212) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 21.Auerbach F. 1913. Das Gesetz der Bevlkerungskonzentration. Petermanns Geographische Mitteilungen 59, 74–76. [Google Scholar]
- 22.Zipf G. 1949. Human behavior and the principle of least-effort. Cambridge, MA: Addison-Wesley. [Google Scholar]
- 23.Newman MEJ. 2004. Power laws, Pareto distributions and Zipf’s law. Contemp. Phys. 46, 323–351. ( 10.1080/00107510500052444) [DOI] [Google Scholar]
- 24.Corominas-Murtra B, Solé RV. 2010. Universality in Zipf’s law. Phys. Rev. E 82, 011102 ( 10.1103/PhysRevE.82.011102) [DOI] [PubMed] [Google Scholar]
- 25.Corominas-Murtra B, Solé RV. 2011. Emergence of Zipf’s law in the evolution of communication. Phys. Rev. E 83, 036115 ( 10.1103/PhysRevE.83.036115) [DOI] [PubMed] [Google Scholar]
- 26.Corominas-Murtra B, Hanel R, Thurner S. 2015. Understanding scaling through history-dependent processes with collapsing sample space. Proc. Natl Acad. Sci. USA 112, 5348–5353. ( 10.1073/pnas.1420946112) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27.Corominas-Murtra B, Hanel R, Thurner S. 2016. Extreme robustness of scaling in sample space reducing processes explains Zipf's law in diffusion on directed networks. New J. Phys. 18, 093010 ( 10.1088/1367-2630/18/9/093010) [DOI] [Google Scholar]
- 28.Ferrer R, Solé RV. 2002. Zipf’s law in random texts. Adv. Complex Syst. 5, 1–6. ( 10.1142/S0219525902000468) [DOI] [Google Scholar]
- 29.Koonin EV, Wof YI, Karev GP. 2002. The structure of the protein universe and genomic evolution. Nature 420, 218–223. ( 10.1038/nature01256) [DOI] [PubMed] [Google Scholar]
- 30.Vogel C, Bashton M, Kerrison ND, Chothia C, Teichmann SA. 2004. Structure, function and evolution of multidomain proteins. Curr. Opin. Struct. Biol. 14, 208–216. ( 10.1016/j.sbi.2004.03.011) [DOI] [PubMed] [Google Scholar]
- 31.Kim KM, Caetano-Anollés G. 2012. The evolutionary history of protein fold families and proteomes confirms that the archaeal ancestor is more ancient than the ancestors of other superkingdoms. BMC Evol. Biol. 12, 13 ( 10.1186/1471-2148-12-13) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32.Rodriguez-Caso C, Medina MA, Solé RV. 2005. Topology, tinkering and evolution of the human transcription factor network. FEBS J. 272, 6423–6434. ( 10.1111/EJB.2005.272.issue-24) [DOI] [PubMed] [Google Scholar]
- 33.Przytycka T, Srinivasan R, Rose GD. 2002. Recursive domains in proteins. Prot. Sci. 11, 409–417. ( 10.1110/ps.24701) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34.Gimona M. 2006. Protein linguistics—a grammar for modular protein assembly? Nature Rev. Cell. Biol. 7, 68–73. ( 10.1038/nrm1785) [DOI] [PubMed] [Google Scholar]
- 35.Schuster P, Fontana W, Stadler PF, Hofacker IL. 1994. From sequences to shapes and back: a case study in RNA secondary structures. Proc. R. Soc. Lond. B 255, 279–284. ( 10.1098/rspb.1994.0040) [DOI] [PubMed] [Google Scholar]
- 36.Huynen MA, Stadler PF, Fontana W. 1996. Smoothness within ruggedness: the role of neutrality in adaptation. Proc. Natl Acad. Sci. USA 93, 397–401. ( 10.1073/pnas.93.1.397) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37.Nimwegen E, Crutchfield JP, Huynen M. 1999. Neutral evolution of mutational robustness. Proc. Natl Acad. Sci. USA 96, 9716–9720. ( 10.1073/pnas.96.17.9716) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38.Fernandez P, Solé RV. 2007. Neutral fitness landscapes in signaling networks. J. R. Soc. Interface 4, 41–47. ( 10.1098/rsif.2006.0152) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39.Arthur WB, Polak W. 2006. The evolution of technology within a simple computer model. Complexity 11, 23–31. ( 10.1002/(ISSN)1099-0526) [DOI] [Google Scholar]
- 40.Adami C. 1998. Introduction to artificial life. New York, NY: Springer. [Google Scholar]
- 41.Hernández-Orozco S, Hernández-Quiroz F, Zenil H. 2018. Undecidability and irreducibility conditions for open-ended evolution and emergence. Artif. Life 24, 56–70. ( 10.1162/ARTL_a_00254) [DOI] [PubMed] [Google Scholar]
- 42.Solomonoff RJ. 1960. A preliminary report on a general theory of inductive inference. Technical Report ZTB-138, Zator Company, Cambridge, MA.
- 43.Chaitin GJ. 1977. Algorithmic information theory. IBM J. Res. Dev. 21, 350–359. ( 10.1147/rd.214.0350) [DOI] [Google Scholar]
- 44.Chaitin GJ. 1990. Information, randomness and incompleteness: papers on algorithmic information theory, vol. 8 Singapore: World Scientific. [Google Scholar]
- 45.Kolmogorov AN. 1965. Three approaches to the quantitative definition of information. Problems Inform. Transm. 1, 1–7. [Google Scholar]
- 46.Solomonoff R. 1964. A formal theory of inductive inference part I. Inform. Control 7, 1–22. ( 10.1016/S0019-9958(64)90223-2) [DOI] [Google Scholar]
- 47.Chaitin GJ. 1969. On the simplicity and speed of programs for computing infinite sets of natural numbers. J. ACM 16, 407–422. ( 10.1145/321526.321530) [DOI] [Google Scholar]
- 48.Adami C, Cerf NJ. 2000. Physical complexity of symbolic sequences. Physica D 137, 62–69. ( 10.1016/S0167-2789(99)00179-7) [DOI] [Google Scholar]
- 49.Zurek WH. 1989. Thermodynamic cost of computation, algorithmic complexity and the information metric. Nature 341, 119–124. ( 10.1038/341119a0) [DOI] [Google Scholar]
- 50.Chaitin GJ. 1982. Algorithmic information theory. New York, NY: John Wiley & Sons, Inc. [Google Scholar]
- 51.Li M, Vitányi PMB. 1997. An introduction to Kolmogorov complexity and its applications, 2nd edn Berlin, Germany: Springer. [Google Scholar]
- 52.Cover TM, Thomas JA. 1991. Elements of information theory. New York, NY: Wiley. [Google Scholar]
- 53.Hopfield JJ. 1994. Physics, computation, and why biology looks so different. J. Theor. Biol. 171, 53–60. ( 10.1006/jtbi.1994.1211) [DOI] [Google Scholar]
- 54.Turing A. 1936. On computable numbers, with an application to the Entscheidungsproblem. Proc. Lond. Math. Soc. 42, 230–265. ( 10.1112/plms/s2-42.1.230) [DOI] [Google Scholar]
- 55.Neef A, Latorre A, Peretó J, Silva FJ, Pignatelli M, Moya A. 2011. Genome economization in the endosymbiont of the wood Cryptocercus punctulatus due to drastic loss of amynoacid synthesis capabilities. Genome Biol. Evol. 3, 1437–1448. ( 10.1093/gbe/evr118) [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56.Kaufmann SA. 1993. The origins of order: self-organization and selection in evolution. Oxford, UK: Oxford University Press. [Google Scholar]
- 57.Mora T, Bialek W. 2011. Are biological systems poised at criticality? J. Stat. Phys. 144, 268–302. ( 10.1007/s10955-011-0229-4) [DOI] [Google Scholar]
- 58.Muñoz MA. 2018. Colloquium: criticality and dynamical scaling in living systems. Rev. Mod. Phys. 90, 031001 ( 10.1103/RevModPhys.90.031001) [DOI] [Google Scholar]
- 59.Tkačik G, Bialek W. 2016. Information processing in living systems. Annu. Rev. Condens. Matter Phys. 7, 12.1–12.29. ( 10.1146/annurev-conmatphys-031214-014803) [DOI] [Google Scholar]
- 60.Solé RV, Valverde S. 2013. Macroevolution in silico: scales, constraints and universals. Palaeontology 56, 1327–1340. ( 10.1111/pala.2013.56.issue-6) [DOI] [Google Scholar]
- 61.Kauffman SA. 2000. Investigations. Oxford, UK: Oxford University Press. [Google Scholar]
- 62.Nguyen A, Yosinski J, Clune J. 2016. Understanding innovation engines: automated creativity and improved stochastic optimization via deep learning. Evol. Comput. 24, 545–572. ( 10.1162/EVCO_a_00189) [DOI] [PubMed] [Google Scholar]
- 63.Pastor-Satorras R, Smith E, Solé RV. 2003. Evolving protein interaction networks through gene duplication. J. Theor. Biol. 222, 199–210. ( 10.1016/S0022-5193(03)00028-6) [DOI] [PubMed] [Google Scholar]
- 64.Solé RV, Pastor-Satorras R, Smith E, Kepler TB. 2002. A model of large-scale proteome evolution. Adv. Complex Syst. 5, 43–54. ( 10.1142/S021952590200047X) [DOI] [Google Scholar]
- 65.Dorogovtsev SN, Mendes JFF. 2003. Evolution of networks: from biological nets to the Internet and WWW. Oxford, UK: Oxford University Press. [Google Scholar]
- 66.Wolpert DH, Macready WG. 1997. No free lunch theorems for optimization. IEEE Trans. Evol. Comp. 1, 67–82. ( 10.1109/4235.585893) [DOI] [Google Scholar]
- 67.Hordijk W. 2016. Evolution: limited and predictable or unbounded and lawless? Biol. Theory 11, 187–191. ( 10.1007/s13752-016-0251-5) [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
This article has no additional data.