

Abstract
Principal Component Analysis (PCA) is a classical method for reducing the dimensionality of data by projecting them onto a subspace that captures most of their variation. Effective use of PCA in modern applications requires understanding its performance for data that are both high-dimensional and heteroscedastic. This paper analyzes the statistical performance of PCA in this setting, i.e., for high-dimensional data drawn from a low-dimensional subspace and degraded by heteroscedastic noise. We provide simplified expressions for the asymptotic PCA recovery of the underlying subspace, subspace amplitudes and subspace coefficients; the expressions enable both easy and efficient calculation and reasoning about the performance of PCA. We exploit the structure of these expressions to show that, for a fixed average noise variance, the asymptotic recovery of PCA for heteroscedastic data is always worse than that for homoscedastic data (i.e., for noise variances that are equal across samples). Hence, while average noise variance is often a practically convenient measure for the overall quality of data, it gives an overly optimistic estimate of the performance of PCA for heteroscedastic data.
Keywords: Asymptotic random matrix theory, Heteroscedasticity, High-dimensional data, Principal component analysis, Subspace estimation
1. Introduction
Principal Component Analysis (PCA) is a classical method for reducing the dimensionality of data by representing them in terms of a new set of variables, called principal components, where variation in the data is largely captured by the first few principal components [23]. This paper analyzes the asymptotic performance of PCA for data with heteroscedastic noise. In particular, we consider the classical and commonly employed unweighted form of PCA that treats all samples equally and remains a natural choice in applications where estimates of the noise variances are unavailable or one hopes the noise is “close enough” to being homoscedastic. Our analysis uncovers several practical new insights for this setting; the findings both broaden our understanding of PCA and also precisely characterize the impact of heteroscedasticity.
Given zero-mean sample vectors , the first k principal components and corresponding squared PCA amplitudes are the first k eigenvectors and eigenvalues, respectively, of the sample covariance matrix . The associated score vectors are standardized projections given, for each i ∈ {1,…,k}, by . The principal components , PCA amplitudes and score vectors are efficiently obtained from the data matrix as its left singular vectors, (scaled) singular values and (scaled) right singular vectors, respectively.
A natural setting for PCA is when data are noisy measurements of points drawn from a subspace. In this case, the first few principal components form an estimated basis for the underlying subspace; if they recover the underlying subspace accurately then the low-dimensional scores will largely capture the meaningful variation in the data. This paper analyzes how well the first k principal components , PCA amplitudes and score vectors recover their underlying counterparts when the data are heteroscedastic, that is, when the noise in the data has non-uniform variance across samples.
1.1. High-dimensional, heteroscedastic data
Dimensionality reduction is a fundamental task, so PCA has been applied in a broad variety of both traditional and modern settings. See [23] for a thorough review of PCA and some of its important traditional applications. A sample of modern application areas include medical imaging [2, 33], classification for cancer data 35], anomaly detection on computer networks [24], environmental monitoring [31, 39] and genetics [25], to name just a few.
It is common in modern applications in particular for the data to be high-dimensional (i.e., the number of variables measured is comparable with or larger than the number of samples), which has motivated the development of new techniques and theory for this regime [22]. It is also common for modern data sets to have heteroscedastic noise. For example, Cochran and Horne [11] apply a PCA variant to spectrophotometric data from the study of chemical reaction kinetics. The spectrophotometric data are absorptions at various wavelengths over time, and measurements are averaged over increasing windows of time causing the amount of noise to vary across time. Another example is given in [36], where data are astronomical measurements of stars taken at various times; here changing atmospheric effects cause the amount of noise to vary across time. More generally, in the era of big data where inference is made using numerous data samples drawn from a myriad of different sources, one can expect that both high-dimensionality and heteroscedasticity will be the norm. It is important to understand the performance of PCA in such settings.
1.2. Contributions of this paper
This paper provides simplified expressions for the performance of PCA from heteroscedastic data in the limit as both the number of samples and dimension tend to infinity. The expressions quantify the asymptotic recovery of an underlying subspace, subspace amplitudes and coefficients by the principal components, PCA amplitudes and scores, respectively. The asymptotic recoveries are functions of the samples per ambient dimension, the underlying subspace amplitudes and the distribution of noise variances. Forming the expressions involves first connecting several results from random matrix theory [3, 5] to obtain initial expressions for asymptotic recovery that are difficult to evaluate and analyze, and then exploiting a nontrivial structure in the expressions to obtain much simpler algebraic descriptions. These descriptions enable both easy and efficient calculation and reasoning about the asymptotic performance of PCA.
The impact of heteroscedastic noise, in particular, is not immediately obvious given results of prior literature. How much do a few noisy samples degrade the performance of PCA? Is heteroscedasticity ever beneficial for PCA? Our simplified expressions enable such questions to be answered. In particular, we use these expressions to show that, for a fixed average noise variance, the asymptotic subspace recovery, amplitude recovery and coefficient recovery are all worse for heteroscedastic data than for homoscedastic data (i.e., for noise variances that are equal across samples), confirming a conjecture in [18]. Hence, while average noise variance is often a practically convenient measure for the overall quality of data, it gives an overly optimistic estimate of PCA performance. This analysis provides a deeper understanding of how PCA performs in the presence of heteroscedastic noise.
1.3. Relationship to previous works
Homoscedastic noise has been well-studied, and there are many nice results characterizing PCA in this setting. Benaych-Georges and Nadakuditi [5] give an expression for asymptotic subspace recovery, also found in [21, 29, 32], in the limit as both the number of samples and ambient dimension tend to infinity. As argued in [21], the expression in [5] reveals that asymptotic subspace recovery is perfect only when the number of samples per ambient dimension tends to infinity, so PCA is not (asymptotically) consistent for high-dimensional data. Various alternatives [6, 15, 21] can regain consistency by exploiting sparsity in the covariance matrix or in the principal components. As discussed in [5, 29], the expression in [5] also exhibits a phase transition: the number of samples per ambient dimension must be sufficiently high to obtain non-zero subspace recovery (i.e., for any subspace recovery to occur). This paper generalizes the expression in [5] to heteroscedastic noise; homoscedastic noise is a special case and is discussed in Section 2.3. Once again, (asymptotic) consistency is obtained when the number of samples per ambient dimension tends to infinity, and there is a phase transition between zero recovery and non-zero recovery.
PCA is known to generally perform well in the presence of low to moderate homoscedastic noise and in the presence of missing data [10]. When the noise is standard normal, PCA gives the maximum likelihood (ML) estimate of the subspace [37]. In general, [37] proposes finding the ML estimate via expectation maximization. Conventional PCA is not an ML estimate of the subspace for heteroscedastic data, but it remains a natural choice in applications where we might expect noise to be heteroscedastic but hope it is “close enough” to being homoscedastic. Even for mostly homoscedastic data, however, PCA performs poorly when the heteroscedasticity is due to gross errors (i.e., outliers) [13, 19, 23], which has motivated the development and analysis of robust variants; see [8, 9, 12, 16, 17,26, 34, 40, 42] and their corresponding bibliographies. This paper provides expressions for asymptotic recovery that enable rigorous understanding of the impact of heteroscedasticity.
The generalized spiked covariance model, proposed and analyzed in [4] and [41], generalizes homoscedastic noise in an alternate way. It extends the Johnstone spiked covariance model [20, 21] (a particular homoscedastic setting) by using a population covariance that allows, among other things, non-uniform noise variances within each sample. Non-uniform noise variances within each sample may arise, for example, in applications where sample vectors are formed by concatenating the measurements of intrinsically different quantities. This paper considers data with non-uniform noise variances across samples instead; we model noise variances within each sample as uniform. Data with nonuniform noise variances across samples arise, for example, in applications where samples come from heterogeneous sources, some of which are better quality (i.e., lower noise) than others. See Section S1 of the Online Supplement for a more detailed discussion of connections to spiked covariance models.
Our previous work [18] analyzed the subspace recovery of PCA for heteroscedastic noise but was limited to real-valued data coming from a random one-dimensional subspace where the number of samples exceeded the data dimension. This paper extends that analysis to the more general setting of real- or complex-valued data coming from a deterministic low-dimensional subspace where the number of samples no longer needs to exceed the data dimension. This paper also extends the analysis of [18] to include the recovery of the underlying subspace amplitudes and coefficients. In both works, we use the main results of [5] to obtain initial expressions relating asymptotic recovery to the limiting noise singular value distribution.
The main results of [29] provide non-asymptotic results (i.e., probabilistic approximation results for finite samples in finite dimension) for homoscedastic noise limited to the special case of one-dimensional subspaces. Signal-dependent noise was recently considered in [38], where they analyze the performance of PCA and propose a new generalization of PCA that performs better in certain regimes. A recent extension of [5] to linearly reduced data is presented in [14] and may be useful for analyzing weighted variants of PCA. Such analyses are beyond the scope of this paper, but are interesting avenues for further study.
1.4. Organization of the paper
Section 2 describes the model we consider and states the main results: simplified expressions for asymptotic PCA recovery and the fact that PCA performance is best (for a fixed average noise variance) when the noise is homoscedastic. Section 3 uses the main results to provide a qualitative analysis of how the model parameters (e.g., samples per ambient dimension and the distribution of noise variances) affect PCA performance under heteroscedastic noise. Section 4 compares the asymptotic recovery with non-asymptotic (i.e., finite) numerical simulations. The simulations demonstrate good agreement as the ambient dimension and number of samples grow large; when these values are small the asymptotic recovery and simulation differ but have the same general behavior. Sections 5 and 6 prove the main results. Finally, Section 7 discusses the findings and describes avenues for future work.
2. Main results
2.1. Model for heteroscedastic data
We model n heteroscedastic sample vectors from a k-dimensional subspace as
| (1) |
The following are deterministic: forms an orthonormal basis for the subspace, is a diagonal matrix of amplitudes, ηi ∈ {σ1,…,σL} are each one of L noise standard deviations σ1,…,σL, and we define n1 to be the number of samples with ηi = σ1, n2 to be the number of samples with ηi = σ2 and so on, where n1 + … + nL = n.
The following are random and independent: are iid sample coefficient vectors that have iid entries with mean E(zij) = 0, variance E∣zij∣2 = 1, and a distribution satisfying the log-Sobolev inequality [1], are unitarily invariant iid noise vectors that have iid entries with mean E(εij) = 0, variance E∣εij∣2 = 1 and bounded fourth moment E∣εij∣4 < ∞, and we define the k (component) coefficient vectors such that the ith entry of z(j) is , the complex conjugate of the jth entry of zi. Defining the coefficient vectors in this way is convenient for stating and proving the results that follow, as they more naturally correspond to right singular vectors of the data matrix formed by concatenating y1,…,yn as columns.
The model extends the Johnstone spiked covariance model [20, 21] by incorporating heteroscedasticity (see Section S1 of the Online Supplement for a detailed discussion). We also allow complex-valued data, as it is of interest in important signal processing applications such as medical imaging; for example, data obtained in magnetic resonance imaging are complex-valued.
Remark 1. By unitarily invariant, we mean that left multiplication of εi by any unitary matrix does not change the joint distribution of its entries. As in our previous work [18], this assumption can be dropped if instead the subspace U is randomly drawn according to either the “orthonormalized model” or “iid model” of [5]. Under these models, the subspace U is randomly chosen in an isotropic manner.
Remark 2. The above conditions are satisfied, for example, when the entries zij and εij are circularly symmetric complex normal or real-valued normal . Rademacher random variables (i.e., ±1 with equal probability) are another choice for coefficient entries zij; see Section 2.3.2 of [1] for discussion of the log-Sobolev inequality. We are unaware of non-Gaussian distributions satisfying all conditions for noise entries εij, but as noted in Remark 1, unitary invariance can be dropped if we assume the subspace is randomly drawn as in [5].
Remark 3. The assumption that noise entries εij are identically distributed with bounded fourth moment can be relaxed when they are real-valued as long as an aggregate of their tails still decays sufficiently quickly, i.e., as long as they satisfy Condition 1.3 from [30]. In this setting, the results of [30] replace those of [3] in the proof.
2.2. Simplified expressions for asymptotic recovery
The following theorem describes how well the PCA estimates , and recover the underlying subspace basis u1,…, uk, subspace amplitudes θ1,…, θk and coefficient vectors z(1),…, z(k), as a function of the sample-to-dimension ratio n/d → c > 0, the subspace amplitudes θ1,…, θk, the noise variances and corresponding proportions nℓ/n → pℓ for each ℓ ∈ {1,…, L}. One may generally expect performance to improve with increasing sample-to-dimension ratio and subspace amplitudes; Theorem 1 provides the precise dependence on these parameters as well as on the noise variances and their proportions.
Theorem 1 (Recovery of individual components). Suppose that the sample-to-dimension ratio n/d → c > 0 and the noise variance proportions nℓ/n → pℓ for ℓ ∈ {1,…, L} as n, d → ∞. Then the ith PCA amplitude is such that
| (2) |
where α and βi are, respectively, the largest real roots of
| (3) |
Furthermore, if A(βi) > 0, then the ith principal component is such that
| (4) |
the normalized score vector is such that
| (5) |
and
| (6) |
Section 5 presents the proof of Theorem 1. The expressions can be easily and efficiently computed. The hardest part is finding the largest roots of the univariate rational functions A(x) and Bi(x), but off-the-shelf solvers can do this efficiently. See [18] for an example of similar calculations.
The projection in Theorem 1 is the square cosine principal angle between the ith principal component and the span of the basis elements with subspace amplitudes equal to θi. When the subspace amplitudes are distinct, is the square cosine angle between and ui. This value is related by a constant to the squared error between the two (unit norm) vectors and is one among several natural performance metrics for subspace estimation. Similar observations hold for . Note that has unit norm.
The expressions (4), (5) and (6) apply only if A(βi) > 0. The following conjecture predicts a phase transition at A(βi) = 0 so that asymptotic recovery is zero for A(βi) ≤ 0.
Conjecture 1 (Phase transition). Suppose (as in Theorem 1) that the sample-to-dimension ratio n/d → c > 0 and the noise variance proportions nℓ/n → pℓ for ℓ ∈ {1,…, L} as n, d → ∞. If A(βi) ≤ 0, then the ith principal component and the normalized score vector are such that
This conjecture is true for a data model having Gaussian coefficients and homoscedastic Gaussian noise as shown in [32]. It is also true for a one-dimensional subspace (i.e., k = 1) as we showed in [18]. Proving it in general would involve showing that the singular values of the matrix whose columns are the noise vectors exhibit repulsion behavior; see Remark 2.13 of [5].
2.3. Homoscedastic noise as a special case
For homoscedastic noise with variance σ2, A(x) = 1 – cσ4/(x – σ2)2 and . The largest real roots of these functions are, respectively, and . Thus the asymptotic PCA amplitude (2) becomes
| (7) |
Further, if , then the non-zero portions of asymptotic subspace recovery (4) and coefficient recovery (5) simplify to
| (8) |
These limits agree with the homoscedastic results in [5, 7, 21, 29, 32]. As noted in Section 2.2, Conjecture 1 is known to be true when the coefficients are Gaussian and the noise is both homoscedastic and Gaussian, in which case (8) becomes
See Section 2 of [21] Section and 2.3 of [32] for a discussion of this result.
2.4. Bias of the PCA amplitudes
The simplified expression in (2) enables us to immediately make two observations about the recovery of the subspace amplitudes θ1,…,θk by the PCA amplitudes
Remark 4 (Positive bias in PCA amplitudes). The largest real root βi of Bi(x) is greater than . Thus for ℓ ∈ {1,…, L} and so evaluating (3) at βi yields
As a result, , so the asymptotic PCA amplitude (2) exceeds the subspace amplitude, i.e., is positively biased and is thus an inconsistent estimate of θi. This is a general phenomenon for noisy data and motivates asymptotically optimal shrinkage in [27].
Remark 5 (Alternate formula for amplitude bias). If A(βi) ≥ 0, then βi ≥ α because A(x) and Bi(x) are both increasing functions for . Thus, the asymptotic amplitude bias is
| (9) |
where we have applied (2), divided the summand with respect to , used the facts that p1 +…+ pL = 1 and Bi(βi) = 0, and finally factored. The expression (9) shows that the positive bias is an increasing function of βi when A(βi) ≥ 0.
2.5. Overall subspace and signal recovery
Overall subspace recovery is more useful than individual component recovery when subspace amplitudes are equal and so individual basis elements are not identifiable. It is also more relevant when we are most interested in recovering or denoising low-dimensional signals in a subspace. Overall recovery of the low-dimensional signal, quantified here by mean square error, is useful for understanding how well PCA “denoises” the data taken as a whole.
Corollary 1 (Overall recovery). Suppose (as in Theorem 1) that the sample-to-dimension ratio n/d → c > 0 and the noise variance proportions nℓ/n → pℓ for ℓ ∈ {1,…, L} as n, d → ∞. If A(β1),…, A(βk) > 0, then the subspace estimate from PCA is such that
| (10) |
and the mean square error is
| (11) |
where A(x), Bi(x) and βi are as in Theorem 1, and is the vector of score entries for the ith sample. Proof of Corollary 1. The subspace recovery can be decomposed as
where the columns of Uj:θj=θi are the basis elements uj with subspace amplitude θj equal to θi, and the remaining basis elements are the columns of Uj:θj≠θi. Asymptotic overall subspace recovery (10) follows by noting that these terms are exactly the square cosine principal angles in (4) of Theorem 1.
The mean square error can also be decomposed as
| (12) |
where , and denotes the real part of its argument. The first term of (1212) has almost sure limit 1 by the law of large numbers. The almost sure limit of the second term is obtained from (9). We can disregard the summands in the inner sum for which θj ≠ θi; by (4) and (5) these terms have an almost sure limit of zero (the inner products both vanish). The rest of the inner sum
has the same almost sure limit as in (6) because . Combining these almost sure limits and simplifying yields (11).
2.6. Importance of homoscedasticity
How important is homoscedasticity for PCA? Does having some low noise data outweigh the cost of introducing heteroscedasticity? Consider the following three settings:
- All samples have noise variance 1 (i.e., data are homoscedastic).
- 99% of samples have noise variance 1.01 but 1% have noise variance 0.01.
- 99% of samples have noise variance 0.01 but 1% have noise variance 99.01.
In all three settings, the average noise variance is 1. We might expect PCA to perform well in Setting 1 because it has the smallest maximum noise variance. However, Setting 2 may seem favorable because we obtain samples with very small noise, and suffer only a slight increase in noise for the rest. Setting 3 may seem favorable because most of the samples have very small noise. However, we might also expect PCA to perform poorly because 1% of samples have very large noise and will likely produce gross errors (i.e., outliers). Between all three, it is not initially obvious what setting PCA will perform best in. The following theorem shows that PCA performs best when the noise is homoscedastic, as in Setting 1.
Theorem 2. Homoscedastic noise produces the best asymptotic PCA amplitude (2), subspace recovery (4) and coefficient recovery (5) in Theorem 1 for a given average noise variance over all distributions of noise variances for which A(βi) > 0. Namely, homoscedastic noise minimizes (2) (and hence the positive bias) and it maximizes (4) and (5).
Concretely, suppose we had c = 10 samples per dimension and a subspace amplitude of θi = 1. Then the asymptotic subspace recoveries (4) given in Theorem 1 evaluate to 0.818 in Setting 1, 0.817 in Setting 2 and 0 in Setting 3; asymptotic recovery is best in Setting 1 as predicted by Theorem 2. Recovery is entirely lost in Setting 3, consistent with the observation that PCA is not robust to gross errors. In Setting 2, only using the 1% of samples with noise variance 0.01 (resulting in 0.1 samples per dimension) yields an asymptotic subspace recovery of 0.908 and so we may hope that recovery with all data could be better. Theorem 2 rigorously shows that PCA does not fully exploit these high quality samples and instead performs worse in Setting 2 than in Setting 1, if only slightly.
Section 6 presents the proof of Theorem 2. It is notable that Theorem 2 holds for all proportions p, sample-to-dimension ratios c and subspace amplitudes θi; there are no settings where PCA benefits from heteroscedastic noise over homoscedastic noise with the same average variance. The following corollary is equivalent and provides an alternate way of viewing the result.
Corollary 2 (Bounds on asymptotic recovery). If A(βi) ≥ 0 then the asymptotic PCA amplitude (2) is bounded as
| (13) |
the asymptotic subspace recovery (4) is bounded as
| (14) |
and the asymptotic coefficient recovery (5) is bounded as
| (15) |
where is the average noise variance and the bounds are met with equality if and only if . Proof of Corollary 2. The bounds (13), (14) and (15) follow immediately from Theorem 2 and the expressions for homoscedastic noise (7) and (8) in Section 2.3.
Corollary 2 highlights that while average noise variance may be a practically convenient measure for the overall quality of data, it can lead to an overly optimistic estimate of the performance of PCA for heteroscedastic data. The expressions (2), (4) and (5) in Theorem 1 are more accurate.
Remark 6 (Average inverse noise variance). Average inverse noise variance is another natural measure for the overall quality of data. In particular, it is the (scaled) Fisher information for heteroscedastic Gaussian measurements of a fixed scalar. Theorem 2 implies that homoscedastic noise also produces the best asymptotic PCA performance for a given average inverse noise variance; note that homoscedastic noise minimizes the average noise variance in this case. Thus, average inverse noise variance can also lead to an overly optimistic estimate of the performance of PCA for heteroscedastic data.
3. Impact of parameters
The simplified expressions in Theorem 1 for the asymptotic performance of PCA provide insight into the impact of the model parameters: sample-to-dimension ratio c, subspace amplitudes θ1,…, θk, proportions p1,…, pL and noise variances . For brevity, we focus on the asymptotic subspace recovery (4) of the ith component; similar phenomena occur for the asymptotic PCA amplitudes (2) and coefficient recovery (5) as we show in Section S3 of the Online Supplement.
3.1. Impact of sample-to-dimension ratio c and subspace amplitude θi
Suppose first that there is only one noise variance fixed at while we vary the sample-to-dimension ratio c and subspace amplitude θi. This is the homoscedastic setting described in Section 2.3. Figure 1a illustrates the expected behavior: decreasing the subspace amplitude θi degrades asymptotic subspace recovery (4) but the lost performance could be regained by increasing the number of samples. Figure 1a also illustrates a phase transition: a sufficient number of samples with a sufficiently large subspace amplitude is necessary to have an asymptotic recovery greater than zero. Note that in all such figures, we label the axis to indicate the asymptotic recovery on the right hand side of (4).
Figure 1:

Asymptotic subspace recovery (4) of the ith component as a function of sample-to-dimension ratio c and subspace amplitude θi with average noise variance equal to one. Contours are overlaid in black and the region where A(βi) ≤ 0 is shown as zero (the prediction of Conjecture 1). The phase transition in (b) is further right than in (a); more samples are needed to recover the same strength signal.
Now suppose that there are two noise variances and occurring in proportions p1 = 80% and p2 = 20%. The average noise variance is still 1, and Figure 1b illustrates similar overall features to the homoscedastic case. Decreasing subspace amplitude θi once again degrades asymptotic subspace recovery (4) and the lost performance could be regained by increasing the number of samples. However, the phase transition is further up and to the right compared to the homoscedastic case. This is consistent with Theorem 2; PCA performs worse on heteroscedastic data than it does on homoscedastic data of the same average noise variance, and thus more samples or a larger subspace amplitude are needed to recover the subspace basis element.
3.2. Impact of proportions p1,…, pL
Suppose that there are two noise variances and occurring in proportions p1 = 1 – p2 and p2, where the sample-to-dimension ratio is c = 10 and the subspace amplitude is θi = 1. Figure 2 shows the−asymptotic subspace recovery (4) as a function of the proportion p2. Since is significantly larger, it is natural to think of p2 as a fraction of contaminated samples. As expected, performance generally degrades as p2 increases and low noise samples with noise variance are traded for high noise samples with noise variance . The performance is best when p2 = 0 and all the samples have the smaller noise variance (i.e., there is no contamination).
Figure 2:
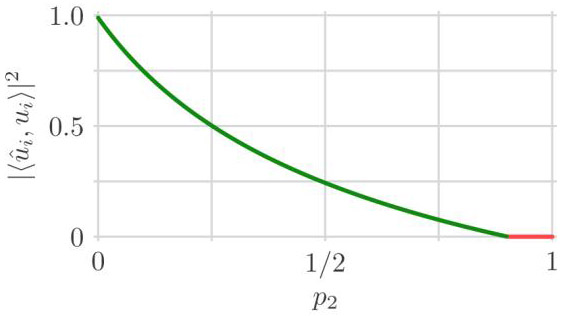
Asymptotic subspace recovery (4) of the ith component as a function of the contamination fraction p2, the proportion of samples with noise variance , where the other noise variance occurs in proportion p1 = 1 – p2. The sample-to-dimension ratio is c = 10 and the subspace amplitude is θi = 1. The region where A(βi) ≤ 0 is the red horizontal segment with value zero (the prediction of Conjecture 1).
It is interesting that the asymptotic subspace recovery in Figure 2 has a steeper slope initially for p2 close to zero and then a shallower slope for p2 close to one. Thus the benefit of reducing the contamination fraction varies across the range.
3.3. Impact of noise variances
Suppose that there are two noise variances and occurring in proportions p1 = 70% and p2 = 30%, where the sample-to-dimension ratio is c = 10 and the subspace amplitude is θi = 1. Figure 3 shows the asymptotic subspace recovery (4) as a function of the noise variances and . As expected, performance typically degrades with increasing noise variances. However, there is a curious regime around and where increasing slightly from zero improves asymptotic performance; the contour lines point slightly up and to the right. We have also observed this phenomenon in finite-dimensional simulations, so this effect is not simply an asymptotic artifact. This surprising phenomenon is an interesting avenue for future exploration.
Figure 3:
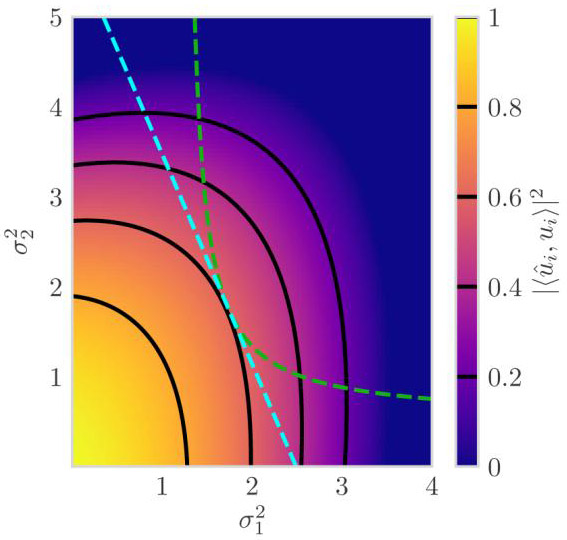
Asymptotic subspace recovery (4) of the ith component as a function of noise variances and occurring in proportions p1 = 70% and p2 = 30%, where the sample-to-dimension ratio is c = 10 and the subspace amplitude is θi = 1. Contours are overlaid in black and the region where A(βi) ≤ 0 is shown as zero (the prediction of Conjecture 1). Along the dashed cyan line, the average noise variance is and the best performance occurs when . Along the dashed green curve, the average inverse noise variance is and the best performance again occurs when .
The contours in Figure 3 are generally horizontal for small and vertical for small . This indicates that when the gap between the two largest noise variances is “sufficiently” wide, the asymptotic subspace recovery (4) is roughly determined by the largest noise variance. While initially unexpected, this property can be intuitively understood by recalling that βi is the largest value of x satisfying
| (16) |
When the gap between the two largest noise variances is wide, the largest noise variance is significantly larger than the rest and it dominates the sum in (16) for , i.e., where βi occurs. Thus βi, and similarly, A(βi) and are roughly determined by the largest noise variance.
The precise relative impact of each noise variance depends on its corresponding proportion pℓ, as shown by the asymmetry of Figure 3 around the line . Nevertheless, very large noise variances can drown out the impact of small noise variances, regardless of their relative proportions. This behavior provides a rough explanation for the sensitivity of PCA to even a few gross errors (i.e., outliers); even in small proportions, sufficiently large errors dominate the performance of PCA.
Along the dashed cyan line in Figure 3, the average noise variance is and the best performance occurs when , as predicted by Theorem 2. Along the dashed green curve, the average inverse noise variance is and the best performance again occurs when , as predicted in Remark 6. Note, in particular, that the dashed line and curve are both tangent to the contour at exactly . The observation that larger noise variances have “more impact” provides a rough explanation for this phenomenon; homoscedasticity minimizes the largest noise variance for both the line and the curve. In some sense, as discussed in Section 2.6, the degradation from samples with larger noise is greater than the benefit of having samples with correspondingly smaller noise.
3.4. Impact of adding data
Consider adding data with noise variance and sample-to-dimension ratio c2 to an existing dataset that has noise variance , sample-to-dimension ratio c1 = 10 and subspace amplitude θi = 1 for the ith component. The combined dataset has a sample-to-dimension ratio of c = c1+c2 and is potentially heteroscedastic with noise variances and appearing in proportions p1 = c1/c and p2 = c2/c. Figure 4 shows the asymptotic subspace recovery (4) of the ith component for this combined dataset as a function of the sample-to-dimension ratio c2 of the added data for a variety of noise variances . The orange curve, showing the recovery when , illustrates the benefit we would expect for homoscedastic data: increasing the samples per dimension improves recovery. The red curve shows the recovery when . For a small number of added samples, the harm of introducing noisier data outweighs the benefit of having more samples. For sufficiently many samples, however, the tradeoff reverses and recovery for the combined dataset exceeds that for the original dataset; the break even point can be calculated using expression (4). Finally, the green curve shows the performance when . As before, the added samples are noisier than the original samples and so we might expect performance to initially decline again. In this case, however, the performance improves for any number of added samples. In all three cases, the added samples dominate in the limit c2 → ∞ and PCA approaches perfect subspace recovery as one may expect. However, perfect recovery in the limit does not typically happen for PCA amplitudes (2) and coefficient recovery (5); see Section S3.4 of the Online Supplement for more details.
Figure 4:

Asymptotic subspace recovery (4) of the ith component for samples added with noise variance and samples-per-dimension c2 to an existing dataset with noise variance , sample-to-dimension ratio c1 = 10 and subspace amplitude θi = 1.
Note that it is equivalent to think about removing noisy samples from a dataset by thinking of the combined dataset as the original full dataset. The green curve in Figure 4 then suggests that slightly noisier samples should not be removed; it would be best if the full data was homoscedastic but removing slightly noisier data (and reducing the dataset size) does more harm than good. The red curve in Figure 4 suggests that much noisier samples should be removed unless they are numerous enough to outweigh the cost of adding them. Once again, expression (4) can be used to calculate the break even point.
4. Numerical simulation
This section simulates data generated by the model described in Section 2.1 to illustrate the main result, Theorem 1, and to demonstrate that the asymptotic results provided are meaningful for practical settings with finitely many samples in a finite-dimensional space. As in Section 3, we show results only for the asymptotic subspace recovery (4) for brevity; the same phenomena occur for the asymptotic PCA amplitudes (2) and coefficient recovery (5) as we show in Section S4 of the Online Supplement. Consider data from a two-dimensional subspace with subspace amplitudes θ1 = 1 and θ2 = 0.8, two noise variances and , and a sample-to-dimension ratio of c = 10. We sweep the proportion of high noise samples p2 from zero to one, setting p1 = 1 – p2 as in Section 3.2. The first simulation considers n = 103 samples in a d = 102 dimensional ambient space (104 trials). The second increases these to n = 104 samples in a d = 103 dimensional ambient space (103 trials). Both simulations generate data from the standard normal distribution, i.e., . Note that sweeping over p2 covers homoscedastic settings at the extremes (p2 = 0, 1) and evenly split heteroscedastic data in the middle (p2 = 1/2).
Figure 5 plots the recovery of subspace components for both simulations with the mean (blue curve) and interquartile interval (light blue ribbon) shown with the asymptotic recovery (4) of Theorem 1 (green curve). The region where A(βi) ≤ 0 is the red horizontal segment with value zero (the prediction of Conjecture 1). Figure 5a illustrates general agreement between the mean and the asymptotic recovery, especially far away from the non-differentiable points where the recovery becomes zero and Conjecture 1 predicts a phase transition. This is a general phenomenon we observed: near the phase transition the smooth simulation mean deviates from the non-smooth asymptotic recovery. Intuitively, an asymptotic recovery of zero corresponds to PCA components that are like isotropically random vectors and so have vanishing square inner product with the true components as the dimension grows. In finite dimension, however, there is a chance of alignment that results in a positive square inner product.
Figure 5:

Simulated subspace recovery (4) as a function of the contamination fraction p2, the proportion of samples with noise variance , where the other noise variance occurs in proportion p1 = 1 – p2. The sample-to-dimension ratio is c = 10 and the subspace amplitudes are θ1 = 1 and θ2 = 0.8. Simulation mean (blue curve) and interquartile interval (light blue ribbon) are shown with the asymptotic recovery (4) of Theorem 1 (green curve). The region where A(βi) ≤ 0 is the red horizontal segment with value zero (the prediction of Conjecture 1). Increasing data size from (a) to (b) results in smaller interquartile intervals, indicating concentration to the mean, which is itself converging to the asymptotic recovery.
Figure 5b shows what happens when the number of samples and ambient dimension are increased to n = 104 and d = 103. The interquartile intervals are roughly half the size of those in Figure 5a, indicating concentration of the recovery of each component (a random quantity) around its mean. Furthermore, there is better agreement between the mean and the asymptotic recovery, with the maximum deviation between simulation and asymptotic prediction still occurring nearby the phase transition. In particular for p2 < 0.75 the largest deviation for is around 0.03. For p2 ∉ (0.1, 0.35), the largest deviation for is around 0.02. To summarize, the numerical simulations indicate that the subspace recovery concentrates to its mean and that the mean approaches the asymptotic recovery. Furthermore, good agreement with Conjecture 1 provides further evidence that there is indeed a phase transition below which the subspace is not recovered. These findings are similar to those in [18] for a one-dimensional subspace with two noise variances.
5. Proof of Theorem 1
The proof has six main parts. Section 5.1 connects several results from random matrix theory to obtain an initial expression for asymptotic recovery. This expression is difficult to evaluate and analyze because it involves an integral transform of the (nontrivial) limiting singular value distribution for a random (noise) matrix as well as the corresponding limiting largest singular value. However, we have discovered a nontrivial structure in this expression that enables us to derive a much simpler form in Sections 5.2-5.6.
5.1. Obtain an initial expression
Rewriting the model in (1) in matrix form yields
| (17) |
where is the coefficient matrix, is the (unscaled) noise matrix, is a diagonal matrix of noise standard deviations.
The first k principal components , PCA amplitudes and (normalized) scores defined in Section 1 are exactly the first k left singular vectors, singular values and right singular vectors, respectively, of the scaled data matrix .
To match the model of [5], we introduce the random unitary matrix
where the random matrix is the Gram-Schmidt orthonormalization of a d × k random matrix that has iid (mean zero, variance one) circularly symmetric complex normal entries. We use the superscript ⊥ to denote a matrix of orthonormal basis elements for the orthogonal complement; the columns of U⊥ form an orthonormal basis for the orthogonal complement of the column span of U.
Left multiplying (17) by yields that , and are the first k left singular vectors, singular values and right singular vectors, respectively, of the scaled and rotated data matrix
The matrix matches the low rank (i.e., rank k) perturbation of a random matrix model considered in [5] because
where
Here P is generated according to the “orthonormalized model” in [5] for the vectors and the “iid model” for the vectors z(i) and P satisfies Assumption 2.4 of [5]; the latter considers and z(i) to be generated according to the same model, but its proof extends to this case. Furthermore RE has iid entries with zero mean, unit variance and bounded fourth moment (by the assumption that εi are unitarily invariant), and H is a non-random diagonal positive definite matrix with bounded spectral norm and limiting eigenvalue distribution , where is the Dirac delta distribution centered at . Under these conditions, Theorem 4.3 and Corollary 6.6 of [3] state that X has a non-random compactly supported limiting singular value distribution μX and the largest singular value of X converges almost surely to the supremum of the support of μX. Thus Assumptions 2.1 and 2.3 of [5] are also satisfied.
Furthermore, for all i, j ∈ {1,…, k} so
and hence Theorem 2.10 from [5] implies that, for each i ∈ {1,…, k},
| (18) |
and that if , then
| (19) |
and
| (20) |
where , , for z > b, φ(z) = ∫ z/z2 – t2) dμx (t), b is the supremum of the support of μX and μX is the limiting singular value distribution of X (compactly supported by Assumption 2.1 of [5]). We use the notation f (b+) = limz→b+ f (z) as convenient shorthand for the limit from above of a function f (z).
Theorem 2.10 from [5] is presented therein for d ≤ n (i.e., c ≥ 1) to simplify their proofs. However, it also holds without modification for d > n if the limiting singular value distribution μX is always taken to be the limit of the empirical distribution of the d largest singular values (d – n of which will be zero). Thus we proceed without the condition that c > 1.
Furthermore, even though it is not explicitly stated as a main result in [5], the proof of Theorem 2.10 in [5] implies that
| (21) |
as was also noted in [27] for the special case of distinct subspace amplitudes.
Evaluating the expressions (18), (19) and (21) would consist of evaluating the intermediates listed above from last to first. These steps are challenging because they involve an integral transform of the limiting singular value distribution μX for the random (noise) matrix X as well as the corresponding limiting largest singular value b, both of which depend nontrivially on the model parameters. Our analysis uncovers a nontrivial structure that we exploit to derive simpler expressions.
Before proceeding, observe that the almost sure limit in (21) is just the geometric mean of the two almost sure limits in (19). Hence, we proceed to derive simplified expressions for (18) and (19); (6) follows as the geometric mean of the simplified expressions obtained for the almost sure limits in (19).
5.2. Perform a change of variables
We introduce the function defined, for z > b, by
| (22) |
because it turns out to have several nice properties that simplify all of the following analysis. Rewriting (19) using ψ(z) instead of φ(z) and factoring appropriately yields that if then
| (23) |
where now
| (24) |
for z > b and we have used the fact that
5.3. Find useful properties of ψ(z)
Establishing some properties of ψ(z) aids simplification significantly.
Property 1. We show that ψ(z) satisfies a certain rational equation for all z > b and derive its inverse function ψ−1(x). Observe that the square singular values of the noise matrix X are exactly the eigenvalues of cXXH, divided by c. Thus we first consider the limiting eigenvalue distribution μcXXH of cXXH and then relate its Stieltjes transform μ to ψ(z).
Theorem 4.3 in [3] establishes that the random matrix cXXH = (1/d)EH2EH has a limiting eigenvalue distribution μcXXH whose Stieltjes transform is given, for μ, by
| (25) |
and satisfies the condition
| (26) |
where μ is the set of all complex numbers with positive imaginary part.
Since the d square singular values of X are exactly the d eigenvalues of cXXH divided by c, we have for all z > b
| (27) |
For all z and μ and so combining (25)–(27) yields that for all z > b
Rearranging yields
| (28) |
for all z > b, where the last term is
because p1 + … + pL = 1. Substituting back into (28) yields 0 = Q{ψ (z), z} for all z > b, where
| (29) |
Thus ψ(z) is an algebraic function (the associated polynomial can be formed by clearing the denominator of Q). Solving (29) for z > b yields the inverse
| (30) |
Property 2. We show that for z > b. For z > b, one can show from (22) that ψ(y) increases continuously and monotonically from ψ(z) to infinity as y increases from z to infinity, and hence ψ−1(x) must increase continuously and monotonically from z to infinity as x increases from ψ(z) to infinity. However, ψ−1(x) is discontinuous at because ψ−1(x) → ∞ as from the right, and so it follows that . Thus for all ℓ ∈ {1,…,L} and so
Property 3. We show that 0 < ψ(b+) < ∞ and ψ′ (b+) = ∞. Property 2 in the limit z = b+ implies that
Taking the total derivative of 0 = Q{ψ(z), z} with respect to z and solving for ψ′ (z) yields
| (31) |
As observed in [28], the non-pole boundary points of compactly supported distributions like μcXXH occur where the polynomial defining their Stieltjes transform has multiple roots. Thus ψ(b+) is a multiple root of Q(·, b) and so
Thus ψ′ (b+) = ∞, where the sign is positive because ψ(z) is an increasing function on z > b.
Summarizing, we have shown that
0 = Q{ψ (z), z} for all z > b where Q is defined in (29), and the inverse function ψ−1(x) is given in (30),
,
0 < ψ(b+) < ∞ and ψ′ (b+) = ∞.
We now use these properties to aid simplification.
5.4. Express D(z) and D′(z)/z in terms of only ψ(z)
We can rewrite (24) as
| (32) |
because 0 = Q{ψ (z), z} by Property 1 of Section 5.3. differentiating (32) with respect to z yields
and so we need to find ψ′ (z) in terms of ψ(z). Substituting the expressions for the partial derivatives ∂Q{ψ (z), z}/∂z and ∂Q{ψ (z), z}/∂s into (31) and simplifying we obtain ψ′ (z) = 2cz/γ(z), where the denominator is
Note that
because 0 = Q{ψ (z), z} for z > b. Substituting into γ(z) and forming a common denominator, then dividing with respect to ψ(z) yields
where A(x) was defined in (3). Thus
| (33) |
and
| (34) |
where is the derivative of Bi(x) defined in (3).
5.5. Express the asymptotic recoveries in terms of only ψ(b+) and ψ(ρi)
Evaluating (32) in the limit z = b+ and recalling that yields
| (35) |
where Bi(x) was defined in (3). Evaluating the inverse function (30) both for ψ(ρi) and in the limit ψ(b+) then substituting into (18) yields
| (36) |
Evaluating (34) for z = ρi and substituting into (23) yields
| (37) |
if Bi{ψ (b+)} < 0.
5.6. Obtain algebraic descriptions
This subsection obtains algebraic descriptions of (35), (36) and (37) by showing that ψ(b+) is the largest real root of A(x) and that ψ(ρi) is the largest real root of Bi(x) when . Evaluating (33) in the limit z = b+ yields
| (38) |
because ψ′ (b+) = ∞ by Property 3 of Section 5.3. If then and so
| (39) |
(38) shows that ψ(b+) is a real root of A(x), and (39) shows that ψ(ρi) is a real root of Bi(x).
Recall that ψ(b+), by Property 2 of Section 5.3, and note that both A(x) and Bi(x) monotonically increase for . Thus each has exactly one real root larger than , i.e., its largest real root, and so ψ(b+) = α and ψ(ρi) = βi when , where α and βi are the largest real roots of A(x) and Bi(x), respectively.
A subtle point is that A(x) and Bi(x) always have largest real roots α and β even though ψ(ρi) is defined only when . Furthermore, α and β are always larger than and both A(x) and Bi(x) are monotonically increasing in this regime and so we have the equivalence
| (40) |
Writing (35), (36) and (37) in terms of α and β, then applying the equivalence (40) and combining with (20) yields the main results (2), (4) and (5).
6. Proof of Theorem 2
If A(βi) ≥ 0 then (4) and (5) increase with A(βi) and decrease with βi and B′(βi). Similarly, (2) increases with βi, as illustrated by (9). As a result, Theorem 2 follows immediately from the following bounds, all of which are met with equality if and only if :
| (41) |
The bounds (41) are shown by exploiting convexity to appropriately bound the rational functions Bi(x), and A(x). We bound βi by noting that
because and f(v) = 1/(βi – v) is a strictly convex function over v < βi. Thus . We bound by noting that
because the quadratic function z2 is strictly convex. Similarly
because the quadratic function z2 is strictly convex and
All of the above bounds are met with equality if and only if because the convexity in all cases is strict. As a result, homoscedastic noise minimizes (2), and it maximizes (4) and (5). See Section S2 of the Online Supplement for some interesting additional properties in this context.
7. Discussion and extensions
This paper provided simplified expressions (Theorem 1) for the asymptotic recovery of a low-dimensional subspace, the corresponding subspace amplitudes and the corresponding coefficients by the principal components, PCA amplitudes and scores, respectively, obtained from applying PCA to noisy high-dimensional heteroscedastic data. The simplified expressions provide generalizations of previous results for the special case of homoscedastic data. They were derived by first connecting several recent results from random matrix theory [3, 5] to obtain initial expressions for asymptotic recovery that are difficult to evaluate and analyze, and then exploiting a nontrivial structure in the expressions to find the much simpler algebraic descriptions of Theorem 1.
These descriptions enable both easy and efficient calculation as well as reasoning about the asymptotic performance of PCA. In particular, we use the simplified expressions to show that, for a fixed average noise variance, asymptotic subspace recovery, amplitude recovery and coefficient recovery are all worse when the noise is heteroscedastic as opposed to homoscedastic (Theorem 2). Hence, while average noise variance is often a practically convenient measure for the overall quality of data, it gives an overly optimistic estimate of PCA performance. Our expressions (2), (4) and (5) in Theorem 1 are more accurate.
We also investigated examples to gain insight into how the asymptotic performance of PCA depends on the model parameters: sample-to-dimension ratio c, subspace amplitudes θ1,…, θk, proportions p1,…, pL and noise variances . We found that performance depends in expected ways on
sample-to-dimension ratio: performance improves with more samples;
subspace amplitudes: performance improves with larger amplitudes;
proportions: performance improves when more samples have low noise.
We also learned that when the gap between the two largest noise variances is “sufficiently wide”, the performance is dominated by the largest noise variance. This result provides insight into why PCA performs poorly in the presence of gross errors and why heteroscedasticity degrades performance in the sense of Theorem 2. Nevertheless, adding “slightly” noisier samples to an existing dataset can still improve PCA performance; even adding significantly noisier samples can be beneficial if they are sufficiently numerous.
Finally, we presented numerical simulations that demonstrated concentration of subspace recovery to the asymptotic prediction (4) with good agreement for practical problem sizes. The same agreement occurs for the PCA amplitudes and coefficient recovery. The simulations also showed good agreement with the conjectured phase transition (Conjecture 1).
There are many exciting avenues for extensions and further work. An area of ongoing work is the extension of our analysis to a weighted version of PCA, where the samples are first weighted to reduce the impact of noisier points. Such a method may be natural when the noise variances are known or can be estimated well. Data formed in this way do not match the model of [5], and so the analysis involves first extending the results of [5] to handle this more general case. Preliminary findings suggest that whitening the noise with inverse noise variance weights is not optimal.
Another natural direction is to consider a general distribution of noise variances v, where we suppose that the empirical noise distribution . We conjecture that if η1,…, ηn are bounded for all n and , then the almost sure limits in this paper hold but with
where τmax is the supremum of the support of v. The proofs of Theorem 1 and Theorem 2 both generalize straight-forwardly for the most part; the main trickiness comes in carefully arguing that limits pass through integrals in Section 5.3.
Proving that there is indeed a phase transition in the asymptotic subspace recovery and coefficient recovery, as conjectured in Conjecture 1, is another area of future work. That proof may be of greater interest in the context of a weighted PCA method. Another area of future work is explaining the puzzling phenomenon described in Section 3.3, where, in some regimes, performance improves by increasing the noise variance. More detailed analysis of the general impacts of the model parameters could also be interesting. A final direction of future work is deriving finite sample results for heteroscedastic noise as was done for homoscedastic noise in [29].
Supplementary Material
Acknowledgments
The authors thank Raj Rao Nadakuditi and Raj Tejas Suryaprakash for many helpful discussions regarding the singular values and vectors of low rank perturbations of large random matrices. The authors also thank Edgar Dobriban for his feedback on a draft and for pointing them to the generalized spiked covariance model. The authors also thank Rina Foygel Barber for suggesting average inverse noise variance be considered and for pointing out that Theorem 2 implies an analogous statement for this measure. Finally, the authors thank the editors and referees for their many helpful comments and suggestions that significantly improved the strength, clarity and style of the paper.
Footnotes
Publisher's Disclaimer: This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final citable form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain.
References
- [1].Anderson G, Guionnet A, Zeitouni O, An Introduction to Random Matrices, Cambridge University Press, Cambridge, UK, 2009. [Google Scholar]
- [2].Ardekani BA, Kershaw J, Kashikura K, Kanno I, Activation detection in functional MRI using subspace modeling and maximum likelihood estimation, IEEE Transactions on Medical Imaging 18 (1999) 101–114. [DOI] [PubMed] [Google Scholar]
- [3].Bai Z, Silverstein JW, Spectral Analysis of Large Dimensional Random Matrices, Springer; New York: 2010. [Google Scholar]
- [4].Bai Z, Yao J, On sample eigenvalues in a generalized spiked population model, J. Multivariate Anal 106 (2012)167–177. [Google Scholar]
- [5].Nadakuditi F. Benaych-Georges RR, The singular values and vectors of low rank perturbations of large rectangular random matrices, J. Multivariate Anal 111 (2012) 120–135. [Google Scholar]
- [6].Bickel PJ, Levina E, Covariance regularization by thresholding, Ann. Statist 36 (2008) 2577–2604. [Google Scholar]
- [7].Biehl M, Mietzner A, Statistical mechanics of unsupervised structure recognition, J. Phys A 27 (1994) 1885–1897. [Google Scholar]
- [8].Candès EJ, Li X, Ma Y, Wright J, Robust principal component analysis? J. Assoc. Comput. Machinery 58 (2011) 1–37. [Google Scholar]
- [9].Chandrasekaran V, Sanghavi S, Parrilo PA, Willsky AS, Rank-sparsity incoherence for matrix decomposition, SIAM J. Optim 21 (2011) 572–596. [Google Scholar]
- [10].Chatterjee S, Matrix estimation by universal singular value thresholding, Ann. Statist 43 (2015) 177–214. [Google Scholar]
- [11].Cochran RN, Horne FH, Statistically weighted principal component analysis of rapid scanning wavelength kinetics experiments, Anal. Chem 49 (1977) 846–853. [Google Scholar]
- [12].Croux C, Ruiz-Gazen A, High breakdown estimators for principal components: The projection-pursuit approach revisited, J. Multivariate Anal 95 (2005) 206–226. [Google Scholar]
- [13].Devlin SJ, Gnandesikan R, Kettenring JR, Robust estimation of dispersion matrices and principal components, J. Amer. Statist. Assoc 76 (1981) 354–362. [Google Scholar]
- [14].Dobriban E, Leeb W, Singer A, PCA from noisy, linearly reduced data: The diagonal case, ArXiv e-prints. [Google Scholar]
- [15].El Karoui N, Operator norm consistent estimation of large-dimensional sparse covariance matrices, Ann. Statist 36 (2008) 2717–2756. [Google Scholar]
- [16].He J, Balzano L, Szlam A, Incremental gradient on the Grassmannian for online foreground and background separation in subsampled video, In: Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on, pp. 1568–1575, 2012. [Google Scholar]
- [17].He J, Balzano L, Szlam A, Online robust background modeling via alternating Grassmannian optimization, In: Background Modeling and Foreground Detection for Video Surveillance, Chapman and Hall/CRC, London, Chapter 16, pp. 1–26, 2014. [Google Scholar]
- [18].Hong D, Balzano L, Fessler JA, Towards a Theoretical Analysis of PCA for Heteroscedastic Data, In: 2016 54th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Forthcoming, 2016. [Google Scholar]
- [19].Huber P, Robust Statistics, Wiley, New York, 1981. [Google Scholar]
- [20].Johnstone IM, On the distribution of the largest eigenvalue in principal components analysis, Ann. Statist 29 (2001) 295–327. [Google Scholar]
- [21].Johnstone IM, Lu AY, On consistency and sparsity for principal components analysis in high dimensions, J. Amer. Statist. Assoc 104 (2009) 682–693. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [22].Johnstone IM, Titterington DM, Statistical challenges of high-dimensional data, Philos. Trans. A Math. Phys. Eng. Sci 367 (2009) 4237– 4253. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [23].Jolliffe I, Principal Component Analysis, Springer, New York, 1986. [Google Scholar]
- [24].Lakhina A, Crovella M, Diot C, Diagnosing network-wide traffic anomalies, In: Proceedings of the 2004 Conference on Applications, Technologies, Architectures, and Protocols for Computer Communications, SIGCOMM ’04, pp. 219–230, 2004. [Google Scholar]
- [25].Leek JT, Asymptotic conditional singular value decomposition for high-dimensional genomic data, Biometrics 67 (2011) 344–352. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [26].Lerman G, McCoy MB, Tropp JA, Zhang T, Robust computation of linear models by convex relaxation, Found. Comput. Math 15 (2015) 363–410. [Google Scholar]
- [27].Nadakuditi RR, OptShrink: An algorithm for improved low-rank signal matrix denoising by optimal, data-driven singular value shrinkage, IEEE Trans. Inform.Theory 60 (2014) 3002–3018. [Google Scholar]
- [28].Nadakuditi RR, Edelman A, The polynomial method for random matrices, Found. Comput. Math 8 (2008) 649–702. [Google Scholar]
- [29].Nadler B, Finite sample approximation results for principal component analysis: A matrix perturbation approach, Ann. Statist 36 (2008) 2791–2817. [Google Scholar]
- [30].Pan G, Strong convergence of the empirical distribution of eigenvalues of sample covariance matrices with a perturbation matrix, J. Multivariate Anal 101 (2010) 1330–1338. [Google Scholar]
- [31].Papadimitriou S, Sun J, Faloutsos C, Streaming pattern discovery in multiple time-series, In: Proceedings of the 31st International Conference on Very Large Data Bases, VLDB ’05, pp. 697–708, 2005. [Google Scholar]
- [32].Paul D, Asymptotics of sample eigenstructure for a large dimensional spiked covariance model, Statist. Sinica 17 (2007) 1617–1642. [Google Scholar]
- [33].Pedersen H, Kozerke S, Ringgaard S, Nehrke K, Kim WY, k-t PCA: Temporally constrained k-t BLAST reconstruction using principal component analysis, Magn. Reson. Med 62 (2009) 706–716. [DOI] [PubMed] [Google Scholar]
- [34].Qiu C, Vaswani N, Lois B, Hogben L, Recursive robust PCA or recursive sparse recovery in large but structured noise, IEEE Trans. Information Theory 60 (2014) 5007–5039. [Google Scholar]
- [35].Sharma N, Saroha K, A novel dimensionality reduction method for cancer dataset using PCA and feature ranking, In: Advances in Computing, Communications and Informatics (ICACCI), 2015 International Conference on, 2261–2264, 2015. [Google Scholar]
- [36].Tamuz O, Mazeh T, Zucker S, Correcting systematic effects in a large set of photometric light curves, Mon. Notices Royal Astron. Soc 356 (2005) 1466–1470. [Google Scholar]
- [37].Tipping ME, Bishop CM, Probabilistic principal component analysis, J. R. Stat. Soc. Ser. B 61 (1999) 611–622. [Google Scholar]
- [38].Vaswani N, Guo H, Correlated-PCA: Principal components’ analysis when data and noise are correlated, In: Advances in Neural Information Processing Systems 29 (NIPS 2016) pre-proceedings, 2016. [Google Scholar]
- [39].Wagner GS, Owens TJ, Signal detection using multi-channel seismic data, Bull. Seismol. Soc. Am 86 (1996) 221–231. [Google Scholar]
- [40].Xu H, Caramanis C, Sanghavi S, Robust PCA via Outlier Pursuit, IEEE Trans. Inform. Theory 58 (2012) 3047–3064. [Google Scholar]
- [41].Yao J, Zheng S, Bai Z, Large Sample Covariance Matrices and High-Dimensional Data Analysis, Cambridge Series in Statistical and Probabilistic Mathematics, Cambridge University Press, Cambridge, UK, 2015. [Google Scholar]
- [42].Zhan J, Lois B, Vaswani N, Online (and offline) robust PCA: Novel algorithms and performance guarantees, International Conference on Artificial Intelligence and Statistics (2016) pp. 1–52. [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.