

Abstract
Experiments show that evolutionary fitness landscapes can have a rich combinatorial structure due to epistasis. For some landscapes, this structure can produce a computational constraint that prevents evolution from finding local fitness optima—thus overturning the traditional assumption that local fitness peaks can always be reached quickly if no other evolutionary forces challenge natural selection. Here, I introduce a distinction between easy landscapes of traditional theory where local fitness peaks can be found in a moderate number of steps, and hard landscapes where finding local optima requires an infeasible amount of time. Hard examples exist even among landscapes with no reciprocal sign epistasis; on these semismooth fitness landscapes, strong selection weak mutation dynamics cannot find the unique peak in polynomial time. More generally, on hard rugged fitness landscapes that include reciprocal sign epistasis, no evolutionary dynamics—even ones that do not follow adaptive paths—can find a local fitness optimum quickly. Moreover, on hard landscapes, the fitness advantage of nearby mutants cannot drop off exponentially fast but has to follow a power-law that long-term evolution experiments have associated with unbounded growth in fitness. Thus, the constraint of computational complexity enables open-ended evolution on finite landscapes. Knowing this constraint allows us to use the tools of theoretical computer science and combinatorial optimization to characterize the fitness landscapes that we expect to see in nature. I present candidates for hard landscapes at scales from single genes, to microbes, to complex organisms with costly learning (Baldwin effect) or maintained cooperation (Hankshaw effect). Just how ubiquitous hard landscapes (and the corresponding ultimate constraint on evolution) are in nature becomes an open empirical question.
Keywords: computational complexity, evolutionary constraints, fitness landscapes, open-ended evolution, power law
GENOTYPE and fitness are two central concepts in evolutionary biology. Through its production of phenotypes, and those phenotypes’ interactions with the biotic and abiotic environment, a given genotype has a certain fitness. A fitness landscape summarizes this relationship between genotypes (or phenotypes) and fitness. Formally, fitness landscapes combine numeric fitnesses and a mutation-graph into a combinatorially structured space where each vertex is a possible genotype (or phenotype). The numeric structure is given by a function that maps each genotype to a fitness; typically represented as a non-negative real number and having different physical operationalizations in different experimental systems. A given genotype is more similar to some rather than other genotypes—giving us a notion of genetic distance or mutation-graph. The mutation-graph specifies which genotypes are similar, typically as edges between any two genotypes that differ in a single mutation. This provides the combinatorial structure. A genotype is a local fitness peak (or local fitness optimum) if no adjacent genotype in the mutation-graph has higher fitness.
We usually imagine fitness landscapes as hills or mountain ranges, and continue to assume—as Wright (1932) originally did—that on an arbitrary landscape “selection will easily carry the species to the nearest peak.” And we define a constraint as anything that keeps a population from reaching a local fitness peak. For those that view evolution as a sum of forces, with natural selection being only one of them, it is possible for other forces to act as a constraint when they overpower natural selection and keep the population away from a local fitness peak. Such cases are often associated with maladaptation (Crespi 2000), and are usually attributed to mechanisms like mutation meltdown, mutation bias, recombination, genetic constraints due to lack of variation, or explicit physical or developmental constraints of a particular physiology. I will refer to such situations, where nonselection forces (and/or aspects internal to the population) keep the population from reaching a local fitness peak, as proximal constraints on evolution. In contrast, I will refer to a constraint as ultimate if it is due exclusively to features of the fitness landscape, and is present in the absence of other forces or even holds regardless of the strength of other forces. All constraints are either proximal, ultimate, or a mix of the two. I introduce this terminology of proximal and ultimate constraints by analogy to Mayr’s distinction between proximal and ultimate causes in biology (Mayr 1961). Mayr considered as ultimate only those evolutionary causes that are due exclusively to the historic process of natural selection (Ariew 2003), so I consider as ultimate only those evolutionary constraints that are due exclusively to the fitness landscape structure of natural selection.
The distinction that I am making between proximal and ultimate constraints can be made clearer by reference to a distinction in computer science between algorithms and problems. I will consider the population structure, update rules, developmental processes, mutation operator, or bias, etc. as together specifying the algorithm that is evolution. In contrast, the families of fitness landscapes are like problems to be “solved” by evolution and specific fitness landscapes on which populations evolve are problem-instances. A proximal constraint is any feature of the evolutionary algorithm that prevents the population from finding a local fitness optimum in polynomial time. For a classic example, consider a population with an extreme lack of genetic variation that cannot proceed to an adjacent fitter genotype because the allele that it differs in is simply not available in the population. In this case, the proximal constraint of lack of variation due to the details of this particular population’s evolutionary algorithm prevents it from reaching a fitness peak. In contrast, an ultimate constraint is any feature of the problem (i.e., family of fitness landscapes) that prevents the population from finding a local fitness optimum in polynomial time. It is the goal of this paper to show a convincing example of such a constraint.
One candidate for an ultimate constraint on evolution—historicity or path-dependence—is already widely recognized. A local peak might not be the tallest in the mountain range, so reaching it can prevent us from walking uphill to the tallest peak. This constraint has directed much of the work on fitness landscapes toward how to avoid suboptimal peaks or how a population might move from one peak to another (Wright 1932; Obolski et al. 2018). Usually, these two questions are answered with appeals to the strength of other evolutionary forces, although sometimes the second question is sidestepped by postulating that local fitness peaks are part of the same fitness plateau in a holey adaptive landscape, and, thus, fitness valleys can be bypassed to move between different local optima in the plateau (Gavrilets and Gravner 1997; Gavrilets 2003). But both these types of questions implicitly assume that local peaks (or plateaus) are easy to reach and thus the norm for natural selection. When the constraint of historicity is active, being at one local optimum prevents the population from reaching other (higher) local optima. Thus, this candidate for an ultimate constraint is only partial: it prevents only certain—not all—local fitness optima from being found. In this case, it prevents evolution from finding the highest local peak: the global optimum. But, we seldom consider that even reaching any local optimum might be impossible in a reasonable amount of time.
Here, I show that computational complexity is an ultimate constraint on evolution: it can prevent evolution from finding any local fitness peak—even low fitness ones. A careful analysis—formal mathematical proofs for all statements are available in the supplemental appendix (SA; for a summary, see SA Table A1) and referenced throughout the text—shows that the combinatorial structure of fitness landscapes can prevent populations from reaching any local fitness peaks. This suggests an alternative metaphor for fitness landscapes: fitness landscapes as mazes with the local fitness optima as exits. Natural selection cannot see far in the maze, and must rely only on local information from the limited genetic variation of nearby mutants. In hard mazes, we can end up following exponentially long winding paths to the exit because we cannot spot the shortcuts. In such cases, even if natural selection is the only force acting on the population, a fitness optimum cannot be found. Worse yet, the hardest mazes might not have any shortcuts and even the most clever and farsighted navigator will not know how to reach an exit in a feasible amount of time. In other words, even if the other evolutionary forces “conspire to help” natural selection, a local fitness optimum cannot be found.
To establish these results, I will introduce into biology new techniques from theoretical computer science for managing the complexity of fitness landscapes. The best current techniques in biology come from the statistical mechanics of disordered systems and rely on “[t]he idea that unmanageable complexity can be replaced by randomness” (Hwang et al. 2018). This statistical approach uses randomness in two places: (1) the random mutations, birth-death events, and other physical and biological processes within the algorithm of evolution; and (2) the theoretical distributions of fitness landscapes themselves. For a computer scientist, the first use of randomness corresponds to the analysis of randomized algorithms—certainly a good decision when thinking about evolution. The second use of randomness corresponds to average-case analysis over problem instances. But when the real-world distribution of problem-instances in unknown or hard to characterize, computer scientists are hesitant to pick a specific simple distribution just to analyze the algorithm. Instead, computer scientists usually specify a formal, logically defined hypothesis class of conceivable problem-instances, and then analyze their algorithm for arbitrary distributions over these instances.
In this report, I embrace the randomness within the algorithm (i.e., the randomness of evolution). But instead of introducing a convenient-to-analyze distribution of possible fitness landscapes, I focus on worst-case analysis. In this way, this report can be seen as a contribution to the small but growing literature on population genetics and evolutionary biology through the algorithmic lens (Livnat et al. 2008; Valiant 2009; Wilf and Ewens 2010; Kanade 2012; Kaznatcheev 2013; Chatterjee et al. 2014; Livnat and Papadimitriou 2016; Heredia et al. 2017).
By focusing on worst-case analysis, I am constructing—sometimes implicitly—families of fitness landscapes that are consistent with the logical structure of our hypothesis class of conceivable fitness landscapes. I then show that, in these hard fitness landscapes, computational complexity is an ultimate constraint. But this should not be interpreted as a claim that hard landscapes are ubiquitous or that computational complexity is a major constraint. That would be an empirical question that depends on which fitness landscapes occur in nature. In this report, I suggest several candidates that I suspect correspond to hard landscapes, but the general empirical question of ubiquity is beyond the scope of this theoretical work.
Epistasis and Semismooth Landscapes
What makes some fitness landscapes difficult to navigate is that the effects of mutations at different loci interact with each other. Epistasis is a measure of the kind and amount of interlocus interactions. If the fitness effect of a mutation can have a different sign depending on the genetic background b or B of another locus, then these two loci are said to have sign epistasis (Figure 1b and SA Definition 5). If both mutations have one sign on their own, but the opposite sign together—either bad + bad = good or good + good = bad—then the landscape has reciprocal sign epistasis (Poelwijk et al. 2007, 2011; Crona et al. 2013; Figure 1c and SA Definition 6). A classic example of reciprocal sign epistasis is a lock-and-key; changing just one of the lock or the key breaks the mechanism, but changing both can be beneficial. Finally, magnitude epistasis (positive and negative; SA Definition 4) are interlocus interactions that deviate from additivity, but do not change the sign of fitness effects. This type of epistasis does not change the combinatorial structure of the landscape. As such, I treat it simply as a lack of sign-epistasis.
Figure 1.

Three different kinds of epistasis possible in fitness graphs: (a) no epistasis, (b) sign epistasis, and (c) reciprocal sign epistasis. Arrows are directed from lower fitness genotypes toward mutationally adjacent higher fitness genotypes. Genes and are labeled such that fitness . In the center of each graph is a marker for the type of epistasis, the marker’s various rotations and reflections cover the cases where does not have the highest fitness. For this more exhaustive classification and discussion see SA Figure A.1 and SA A.1.
A landscape without sign epistasis—like the Escherichia coli β-lactamase fitness landscape measured by Chou et al. (2011) in Figure 2a—is called smooth (Weinreich et al. 2005; Crona et al. 2013; and SA B), so let us call a fitness landscape semismooth if it has no reciprocal sign epistasis. The fitness graphs (Crona et al. 2013; and SA A) of semismooth fitness landscapes are equivalent to acyclic unique sink orientations previously defined in a different context by Szabó and Welzl (2001) for the analysis of simplex algorithms (SA Definition 12 and Proposition 13). Since reciprocal sign epistasis is a necessary condition for multiple peaks (SA Corollary 11 and Poelwijk et al. (2011)), both smooth and semismooth fitness landscapes have a single peak . Further, there are short adaptive paths in both: from any genotype x there always exists some adaptive path to of length equal to the number of loci on which x and differ (SA Theorem 14). This means that an omniscient navigator that always picks the “right” adaptive point-mutation can be guaranteed to find a short adaptive path to the peak. But, unlike smooth landscapes, in a semismooth landscape not every shortest path is adaptive and not every adaptive path is short. And since evolution does not have the foresight of an omniscient navigator, it is important to check which adaptive path myopic evolutionary dynamics will follow.
Figure 2.

Two examples of empirical biallelic fitness landscapes on four loci. Arrows are directed from lower fitness genotypes to higher and fitness optima are circled. Examples of adaptive dynamics are highlighted with thick black arrows. (a) The E. coli β-lactamase data of Chou et al. (2011) predict a smooth landscape with no sign epistasis. Thus, it contains a single optimum (1111). (b) Prediction based on P. falciparum dihydrofolate reductase growth rate data in the absence of pyrimethamine (Lozovsky et al. 2009). It has two peaks (0011 and 1111) and both single sign (an example in yellow; 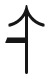 ) and reciprocal sign epistasis (example in red;
) and reciprocal sign epistasis (example in red; 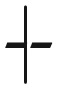 ). Based on Figure 1 in Szendro et al. (2013).
). Based on Figure 1 in Szendro et al. (2013).
When mutation is weak, we can assume that a population is always monomorphic except for a brief moment of transition as a new mutant fixes. Thus, we can represent the population as a single point on the fitness landscape with an evolutionary step corresponding to a selective sweep that moves the population to a neighboring genotype. When selection is strong, we can further assume that the evolutionary step takes us to a neighboring genotype of higher fitness. The rule for selecting which neighbor ends up fixing depends on the details of our mutation operator and model of evolution; i.e., this rule specifies the algorithm. I will refer to the set of algorithms corresponding to all such rules as strong-selection weak mutation (SSWM) dynamics. A number of rules (or algorithms) have been suggested for which fitter neighbor will take over the population (Orr 2005)—such rules correspond to different models of evolution. The two most common rules are to select a fitter mutant uniformly at random, or to select the fittest mutant. These rules capture the intuition of evolution proceeding solely by natural selection with other forces absent or negligible. All SSWM rules will quickly find the fitness optimum in a smooth fitness landscape. But there exist semismooth fitness landscapes such that when starting from a random initial genotype, an exponential number of evolutionary steps will be required for either the random fitter mutant (Matoušek and Szabó 2006; SA Theorem 15) or fittest mutant (SA Theorems 20 and 24) dynamics to find the unique fitness optimum. For a small example on six loci, see Figure 3: the black arrows trace the evolutionary path that a population would follow under fittest mutant SSWM dynamics. Although two step adaptive paths exist to the fitness peak (like ), the myopic navigator cannot notice these shortcuts, and ends up on a long winding path. In other words, even when there is a single peak and adaptive paths of minimal length to it, SSWM dynamics can take exponential time to find that peak.
Figure 3.

Fittest mutant adaptive path in a winding semismooth fitness landscape. An example on six loci of the winding semismooth fitness landscapes from SA C.2 on which the length of the path followed by fittest-mutant SSWM dynamics scales exponentially with the number of loci. Here, the black arrows are the fittest available mutation, and the adaptive path takes 14 steps to reach the fitness peak at 000011. For the generalization of this landscape to -loci, it would take steps for fittest mutant dynamics to reach the fitness peak at (SA Theorem 20). Inset is the selection coefficient (; SA D.2) vs. mutation step number (t) for the fittest mutant adaptive path.
These results show that the computational complexity of the combinatorial structure can be enough to stop evolution from reaching a fitness optimum within a reasonable timescale, even in the absence of suboptimal local peaks. Computer scientists have found it helpful to distinguish between processes that require a time that grows polynomially with the size of the input—generally called tractable—and those that require a time that increases faster than any polynomial (super-polynomial)—intractable. If the winding fitness landscapes of Figure 3 is generalized to loci instead of just 6 (SA C.2) then following fittest mutant SSWM dynamics to the peak is an intractable process since it scales exponentially, requiring mutational steps. Although evolutionary time is long, it is not reasonable to think of it as exponentially long. For example, the above winding process with a genotype on just 120 loci, and, with new set of point-mutants and selective sweep at a rate of one every second, would require more seconds than the time since the Big Bang.
To capture this infeasibility of superpolynomial scaling in time, I introduce a distinction between easy and hard families of fitness landscapes. If we can guarantee for any landscape in the family that a local fitness peak can be found by natural selection in a time the scales as a polynomial in the number of loci—as is the case for smooth fitness landscapes—then I will call that an easy family of landscapes. I will call a family of landscapes hard if we can show that the family contains landscapes where finding a local fitness optimum requires a superpolynomial amount of time—as I showed above for semismooth fitness landscapes. Given that even for moderately sized genomes such large times are not realizable even on cosmological timescales, I will use “impossible” as a shorthand for “requiring an infeasible amount of time.”
Given their exponential size, it is impossible to completely measure whole fitness landscapes on more than a few nucleotides. But with improvements in high-throughput second-generation DNA sequencing, there is hope to measure local fitness landscapes of a few mutations away from a wildtype. Puchta et al. (2016) estimated the fitness of 981 single-step mutations of a 333-nucleotide small nucleolar RNA (snoRNA) gene in yeast. They found no neighbors fitter than the wild-type gene; this suggests that this gene is already at a fitness peak, and, hence, that the snoRNA gene’s fitness landscape is easy. In contrast, Li et al. (2016) estimated the fitness of 207 single-step mutants of a 72-nucleotide transfer RNA (tRNA) gene, also in yeast, finding two neighbors that are significantly fitter than the wild type and a number that are fitter but only within experimental noise. Thus, the wild-type tRNA gene is apparently not at a local fitness peak, and suggests this system as a candidate for hard fitness landscapes. Both studies also looked at many 2- and 3-step mutants, and the landscape of the tRNA gene was measured to have >160 cases of significant sign epistasis (Li et al. 2016), with none in the snoRNA landscape (Puchta et al. 2016), mirroring the difference between hard semismooth fitness landscapes and easy smooth landscapes that I am proposing here.
Rugged Landscapes and Approximate Peaks
But there exist natural fitness landscapes that are even more complicated than semismooth ones. For example, we know that some landscapes can contain reciprocal sign epistasis like the Lozovsky et al. (2009) Plasmodium falciparum dihydrofolate reductase fitness landscape in Figure 2b. This is a rugged fitness landscape with two distinct fitness peaks at 0011 and 1111. Although there is not enough data to justify postulating probability distributions over large landscapes (for discussion, see SA D.3), the standard biological intuition is that natural landscapes are at least a bit rugged and have multiple peaks. The NK-model is a family of fitness landscapes (Kauffman and Levin 1987; Kauffman and Weinberger 1989) that was introduced to study this ruggedness. This model allows tuning the amount of epistasis: the fitness contribution of each of the n loci depends not only on its gene, but also on the genes at up to K other loci (SA Definition 25).
For , the NK-model can generate hard fitness landscapes where from some initial genotypes, any adaptive walk to any local peak is exponentially long (SA Corollary 28). On such landscapes, any adaptive evolutionary dynamic—including, but not limited to, all the SSWM dynamics we have considered so far—generally requires an exponential number of steps to reach a local fitness optimum. Even if an omniscient navigator could always choose the most clever adaptive single mutation to arise, the adaptive path would be unbounded over polynomial timescales.
To better integrate the numeric structure of fitness, let us consider a genotype x to be at an s-approximate peak (Orlin et al. 2004) if each of x’s mutational neighbors y have fitness (SA Definition 31). On the hard rough fitness landscapes described above, fittest mutant dynamics will encounter an s-approximate peak with moderately small s in a moderate number of mutational steps (polynomial in n and ; SA Theorem 33).
However, on hard fitness landscapes, it is not possible to find an s-approximate peak for very small s in a feasible amount of time (i.e., not possible in time polynomial in n and ; SA Theorem 35). This (un)reachability of s-approximate fitness peaks is especially important to consider in discussions of nearly neutral networks and approximate fitness plateaus (Ohta 1992; Gavrilets 2003). In an idealized, unstructured population, we can expect random drift to overcome selection when s drops below about where P is the number of individuals in the population. But certain structured populations can act as amplifiers of selection (Pavlogiannis et al. 2018) and prevent drift from dominating until s is significantly closer to zero.
Given that the quantity s in the definition of an s-approximate peak is defined in the same way as the selection coefficient of population genetics (Gillespie 2010), the above approximation results allow us to link the distinction between easy and hard fitness landscapes to the rich empirical literature on fitness traces and declining fitness gains in microbial evolution experiments (Couce and Tenaillon 2015). On the hard rugged fitness landscapes described above—and even on the winding semismooth landscape of Figure 3 and SA C.2—this selective coefficient drops off at the slow rate of for fittest mutant dynamics. In general, on any family of landscapes—even the hardest ones— can decay as fast as a power law. On easy landscapes, it can decay faster. But the power law decay in selection coefficient is the fastest decay possible on hard fitness landscapes. In particular, the selective coefficient, on hard landscapes, cannot decrease at the exponential rate (i.e., ; SA Corollary 36) that is typical of equilibration in nonbiological systems. This slow decay in selection coefficient is consistent with the rule of declining adaptability observed in various microbial long-term evolution experiments (Wiser et al. 2013; Couce and Tenaillon 2015; Lenski et al. 2015), suggesting that at least some naturally occurring microbial fitness landscapes might be hard. Thus, a natural candidate for hard landscapes might be the landscapes with unbounded growth in fitness observed in the E. coli long-term evolutionary experiment (Wiser et al. 2013). Whereas when one sees a power-law in allometry, one expects potential physical constraints; I propose that when one see a power-law in selection strength or fitness, one should look for a computational constraint.
The existence of hard landscapes allows us to explain open-ended evolution as a consequence of the ultimate constraints of computational complexity. I am certainly not the first to note that populations might undergo unbounded increases in fitness and open-ended evolution. In fact, there is an extensive literature on the rate of adaptation (Gillespie 1983, 1984, 1991; Orr 2002, 2003; Wiser et al. 2013; Couce and Tenaillon 2015) that seems to assume (at least implicitly) that a fitter mutation is always available. These models often directly built-in unbounded growth by treating mutations as iid random samples from a distribution of fitness effects that can always generate a higher fitness variant, albeit with low probability. This approach corresponds to the implicit construction of a fitness landscape as an infinite unbounded tree that lacks the second-order and higher combinatorial structure that mutation-graphs provide. These unbounded tree models are better suited to empirical operationalization than (the exponentially large but) finite fitness landscapes, and make good effective theories on shorter timescale (where time—measured in the number of fixations—is significantly less than the size of the genome). But these models assume (often by reference to recent environmental change) that a beneficial mutation is always possible, rather than explaining why such a mutation is always possible.
This is in stark contrast to the work I present here. To avoid building in the unbounded growth in fitness that I aim to explain, I consider families of finite fitness landscapes. I showed that these can be either easy or hard. In the hard families of landscapes, there is a computational constraint on evolution that ensures that beneficial mutations are available effectively for ever. Thus, this work can be read as an explanatory compliment to the unbounded tree models. Of course, given that I consider large but finite fitness landscapes, it is conceivable that a population will be found at a local fitness peak of a hard fitness landscape. This is conceivable in the same way as—according to the Poincare recurrence theorem—all the oxygen molecules in a large room will eventually return arbitrarily close to the corner they were released from. But just as the Poincare recurrence theorem does not invalidate the second law of thermodynamics (Boltzmann 1896), the existence of local peaks in finite static landscapes does not invalidate open-ended evolution on hard fitness landscapes.
Arbitrary Evolutionary Dynamics: Learning and Cooperation
As we move from single genes (Li et al. 2016; Puchta et al. 2016), to microbes (Wiser et al. 2013; Couce and Tenaillon 2015), and on to large organisms, a richer space of possible evolutionary dynamics opens up. To capture this rich space of possibilities, we need to abstract beyond adaptive dynamics by considering arbitrary mutation operators, demographies, population structures, and selection functions—even ones that can cross fitness valleys and distribute the population over many genotypes. From the perspective of constraints on evolution: I want to relax the selective constraint that confines populations to an adaptive path (Barton and Partridge 2000; SA Definition 1). By allowing nonadaptive changes, I want to highlight the power of the constraint of computational complexity, even in the absence of the selective constraint. From the perspective of evolutionary forces: we have to allow for strong forces that can potentially overpower or boost natural selection. To make sure that we have considered all possibilities, I will model arbitrary evolutionary dynamics as all polynomial-time algorithms. This takes us into the realm of the computational complexity class of polynomial local search (PLS; Johnson et al. 1988; Roughgarden 2010; and SA D). But even for these most permissive population-updating procedures, evolution will, in general, require an infeasible amount of time to find a local fitness peak in the NK-model with (SA Theorem 27 and Corollary 29), or to find an s-approximate peak for very small s (SA Theorem 35). Evolution will be trapped in the mazes of hard fitness landscapes and not reach anywhere near the “exit” of a local fitness optimum. No proximal cause can overpower the ultimate constraint of computational complexity.
If one is accustomed to seeing results only for particular evolutionary algorithms, then the generality of the above results might seem fantastical. But these are exactly the kind of general results that are typical in computational complexity theory.
The strength of this ultimate constraint allows us to reason rigorously from disequilibrium to establish positive results. For instance, that costly learning [Baldwin effect (Baldwin 1896; Simpson 1953)] can remain adaptive, or that hitchhiking can maintain cooperation [Hankshaw effect (Hammarlund et al. 2016)] effectively forever. In the case of costly learning, Simpson (1953) noted: “[c]haracters individually acquired by members of a group of organisms may eventually, under the influence of selection, be reinforced or replaced by similar hereditary character.” For Simpson (1953), this possibility constituted a paradox: if learning does not enhance individual fitness at a local peak, and would thus be replaced by simpler nonlearning strategies, then why do we observe the costly mechanism and associated errors of individual learning? A similar phenomenon is important for the maintenance of cooperation. Hammarlund et al. (2016) consider a metapopulation that is not sufficiently spatially structured to maintain cooperation. They augment the metapopulation with a number of genes with nonfrequency dependent fitness effects that constitute a static fitness landscape. If adaptive mutations are available, then cooperators are more likely to discover them due to the higher carrying capacity of cooperative clusters. This allows cooperation to be maintained by hitchhiking on the genes of the static fitness landscape. Hammarlund et al. (2016) call this hitchhiking the Hankshaw effect and, for them, it constitutes a transient: since cooperation does not enhance opportunities for adaptive mutations at the fitness peak, then cooperators will be outcompeted by defectors.
Currently, both the Baldwin and Hankshaw puzzles are resolved in the same way: just-in-time environmental change. Most resolutions of the Baldwin paradox focus on nonstatic fitness in rapidly fluctuating environments that are compatible with the speed of learning but not with evolutionary adaptation. Similarly, Hammarlund et al. (2016) suggest making their transient permanent by focusing on dynamically changing environments. But, these just-in-time dynamic changes in the fitness landscape are not necessary if we acknowledge the existence of hard static fitness landscapes. Individual costly learning and higher densities of cooperative clusters leading to more mutational opportunities are two very different evolutionary mechanisms for increased adaptability. But they are both just polynomial time algorithms. Regardless of how much these mechanisms speed-up, slow-down, guide, or hinder natural selection, the population will still not be able to find a local fitness optimum in hard fitness landscapes. Without arriving at a fitness optimum, the paradox of costly learning dissolves, and the Hankshaw effect can allow for perpetual cooperation. This suggests that, if we want a family of natural examples of evolution on hard fitness landscapes among more complex organisms, then good candidates might be populations with costly learning or persistent cooperation. More generally, the nonvanishing supply of beneficial mutations on hard landscapes can allow selection to act on various mechanisms for evolvability (Barton and Partridge 2000) by letting the evolvability modifier alleles hitchhike on the favorable alleles that they produce.
These examples can be seen as instances of a more general observation on adaptationism. It is standard to frame adaptationism as “the claim that natural selection is the only important cause of the evolution of most nonmolecular traits and that these traits are locally optimal” (Orzack and Sober 2001). Here, I showed that these are two independent claims. Even if we assume that (1) natural selection is the dominant cause of evolution then—on hard fitness landscapes—it does not follow that (2) traits will be locally optimal. Given the popularity of equilibrium assumptions in evolutionary biology, I expect that a number of other paradoxes and effects in addition to the Baldwin and Hankshaw could be eased by recognizing the independence of these two claims.
For those biologists who have moved on from debates about adaptationism and instead aim to explain the relative contribution of various evolutionary forces to natural patterns, I provide a new consideration: hard landscapes allow the force of natural selection on its own to explain patterns such as, for example, maladaptation. Prior accounts of maladaption rely on forces like deleterious mutation pressure, lack of genotypic variation, drift and inbreeding, and gene flow acting opposite natural selection resulting in a net zero force, and, thus, a maladaptive equilibrium away from a fitness peak (Crespi 2000). The ultimate constraint of computational complexity allows for perpetual maladaptive disequilibrium even in the absence of (or working against) these other forces.
Currently, finding a species away from a local fitness peak is taken as motivation for further questions on what mechanisms or nonselective evolutionary forces cause this discrepancy. In this context, my results provide a general answer: hard landscapes allow adaptationist accounts for the absence of evolutionary equilibrium and maladaptation even in experimental models with static environments—and/or the absence of strong evolutionary forces working against natural selection—like the tRNA gene in yeast (Li et al. 2016; Domingo et al. 2018) or the long-term evolutionary experiment in E. coli (Wiser et al. 2013). By treating evolution as an algorithm, we see that time can be a limiting resource even on evolutionary timescales. These hard landscapes can be finite and deceptively simple—having only limited local epistasis or not having reciprocal sign-epistasis—and yet allow for unbounded fitness growth.
In contrast, a system found at a local fitness peak—like the snoRNA gene in yeast (Puchta et al. 2016)—currently merits no further questions. The results in this report show that establishing evolutionary equilibrium should not be the end of the story. We need to also explain what features of the relevant fitness landscapes make them easy: i.e., explain why these fitness landscapes do not produce a computational constraint on evolution. For this, the tools of theoretical computer science can be used to refine our logical characterization of such fitness landscapes to guarantee that local peaks can be found in polynomial time. For example, we could consider limits on the topology of gene-interaction network (SA D.1), or the type of interaction possible between genes (Chapdelaine and Creignou 2005) to separate easy from hard landscapes. This opens new avenues for both empirical and theoretical work.
In this report, I provided mathematical constructions for hard fitness landscapes and suggested some empirical candidates. By doing this, I showed that computational complexity is an ultimate constraint on (our models of) evolution. But I did not establish that it is a major constraint in nature. Although given the empirical candidates that I suggested, I expect it to play a major role. However, after future empirical investigations, it could be that we find no naturally occurring hard fitness landscapes. This would not be a disappointment. If our models of fitness landscapes allow for ultimate constraints, but we do not see those ultimate constraints in nature, then we will know the direction in which to refine our models.
Given the limited—albeit growing (Orr 2005; Poelwijk et al. 2007; Kryazhimskiy et al. 2009; Lozovsky et al. 2009; Chou et al. 2011; Szendro et al. 2013; Bank et al. 2016; Li et al. 2016; Puchta et al. 2016; Domingo et al. 2018)—empirical data available on the distribution of natural fitness landscapes, it is tempting to turn to theoretical distributions of fitness landscapes. But we should be cautious here. The popular uniform distributions over gene-interaction networks and interaction components was introduced for ease of analysis rather than some foundational reason or empirical justification. With this distribution, I would expect hard instances to be scarce based on arguments similar to Tovey (1986) and Hwang et al. (2018). However, instead of choosing a distribution for ease of analysis, we could instead choose one by Occam’s razor: i.e., the Kolmogorov universal distribution (sampling landscapes with negative log probability proportional to their minimum description length). In the Occam case, I would expect the fraction of fitness landscapes that are hard to be significant based on results similar to Li and Vitányi (1992). I leave it as an open question for future work to determine what choices of distribution of fitness landscapes are most appropriate, and how average case analysis over those particular distributions compares to the distribution-free analysis that I presented here (see SA D.3 for more discussion).
On easy landscapes, it is reasonable to assume that evolution finds locally-well-adapted genotypes or phenotypes. We can continue to reason from fitness peaks, debate questions of crossing fitness valleys, and seek solutions to Wright (1932)’s problem of “a mechanism by which the species may continually find its way from lower to higher [local] peaks.” But with hard landscapes, it is better to think of evolution as open ended and unbounded. We will have to switch to a language of “adapting” rather than “adapted.” We will have to stop reasoning from equilibrium—as I did in the discussion of maintaining costly learning and cooperation. Finally, we will have to stop asking about the basins of attraction for local peaks and instead seek mechanisms that select which unbounded adaptive path evolution will follow. It is tempting to read this language of disequilibrium and negation of “locally adapted” as saying that organismal traits are not well honed to their environment. But we must resist this mistake, and we must not let better be the enemy of good. Finding local optima in the hardest landscapes is a hard problem for any algorithm, not just biological evolution. In particular, it is also hard for scientists: on hard landscapes we cannot find optimal solutions either, and so the adapting answers of evolution can still seem marvelously well honed to us. And although I have focused on biological evolution, we can also look for hard landscapes in other fields. For example, these results translate directly to areas like business operation and innovation theory, where the NK-model is used explicitly (Levinthal 1997; Rivkin and Siggelkow 2007). In physics, the correspondence between spin-glasses and the NK-model can let us look at energy minimization landscapes. In economics, classes of hard fixed-point problems similar to PLS are a lens on markets (Roughgarden 2010). In all these cases, theoretical computer science and combinatorial optimization offer us the tools to make rigorous the distinction between easy and hard landscapes. They allow us to imagine hard landscapes not as low-dimensional mountain ranges but as high-dimensional mazes that we can search effectively for ever.
Acknowledgments
I am grateful to Julian Xue for introducing me to the NK-model and many helpful discussions; and to Peter Jeavons for extensive feedback and encouragement. This paper benefited from comments by Eric Bolo, Frederic Guichard, Marc Harper, Sergey Kryazhimskiy, Andriy Marusyk, Daniel Nichol, Prakash Panangaden, Joshua Plotkin, Jacob Scott, participants of the 2014 Computational Theories of Evolution workshop at the Simons Institute for the Theory of Computing, and the reviewers. This work was started while I was at the School of Computer Science, McGill University, Montreal, Canada.
Appendices
In the main text, I focused on the biological importance, interpretation, and implication of these results. In these appendices, I provide the formal proof of the results. Below, I formally define the concepts introduced within the body of the report, and prove the theorems on which the conclusions are based. Some of this was first presented in the Kaznatcheev (2013) preprint. The structure of the appendices is below:
A Formal definitions of fitness functions, fitness landscapes, fitness graphs, and adaptive paths. I focus specific attention on epistasis (A.1) because it can be used to define broad families of landscapes, such as:
B Smooth fitness landscapes: these are the source of a lot of intuition and early models of fitness landscapes. So, I briefly remind the reader of important properties of smooth landscapes.
C Semismooth fitness landscapes: these share many properties in common with smooth fitness landscapes, and I prove a characterization, Theorem 14, that is structured in a similar way to smooth landscapes. However, computationally, semismooth landscapes, unlike smooth ones, can be hard. In subsection C.1, I use the equivalence of semismooth fitness landscapes and acyclic unique-sink orientations of hyper-cubes to adapt hardness results from the analysis of simplex algorithms. This provides hard landscapes for fitter mutant SSWM dynamics. In the subsequent subsections, I show how to construct hard fitness landscapes for fittest mutant SSWM dynamics from specific start position (C.2) and random start position (C.3).
D NK-model of fitness landscapes: this is a tunable rugged fitness landscape model that—unlike the previous two—can have many peaks. To analyze this model of landscapes, I review the complexity class PLS, show that the NK-model is PLS complete for , and discuss the generality of the results. In subsection D.1, I focus on easy instances of the NK-model, and, in subsection D.3, provide an intuition for why the assumption of simple distributions of fitness landscapes in prior work might have made the existence of hard families more difficult to spot earlier. In subsection D.2, I discuss nearly neutral networks and the hardness of s-approximate peaks (Definition 31).
To recap, I argue that local fitness optima may not be reachable in a reasonable amount of time even when allowing progressively more general and abstract evolutionary dynamics. For this generality, we pay with increasing complication in the corresponding fitness landscapes. This progression of results is summarized in Table A1 (which also serves as a guide for navigating the appendix). If we restrict our evolutionary dynamics to fitter or fittest mutant SSWM, then just sign epistasis is sufficient to ensure the existence of hard landscapes. If we allow any adaptive evolutionary dynamics, then reciprocal sign epistasis in the NK model with is sufficient for hard landscapes. If we want to show that arbitrary evolutionary dynamics cannot find local fitness optima, then we need and the standard conjecture from computational complexity that .
A. Fitness Landscapes, Graphs, and Adaptive Paths
In 1932, Wright introduced the metaphor of a fitness landscape (Wright 1932). The landscape is a genetic space where each vertex is a possible genotype, and an edge exists between two vertices if a single mutation transforms the genotype of one vertex into the other. In the case of a biallelic system, we have n loci (positions), at each of which it is possible to have one of two alleles, thus our space is the n-bit binary strings . We could also look at spaces over larger alphabets; for example, 4 letters for sequence space of DNA, or 20 letters for amino acids; but the biallelic system is sufficiently general for us. A mutation can flip any locus from one allele to the other, thus two strings are adjacent if they differ in exactly one bit. Thus, the landscape is an n-dimensional hypercube with genotypes as vertices. The last ingredient, fitness, is given by a function that maps each string to a non-negative real number. For the majority of this report—with the exception of subsection D.2—the exact fitness values or their physical interpretations do not matter. Only their rank-ordering matters.
Individual organisms can be thought of as inhabiting the vertices of the landscape corresponding to their genotype. And we imagine evolution as generally trying to “climb uphill” on the landscape by moving to vertices of higher fitness.
Definition 1. In a fitness landscape with fitness f, a path is called adaptive if each differs from by one bit and .
These are sometimes also called accessible paths, but I will avoid this terminology because for the most general evolutionary dynamics, the paths taken do not have to be strictly increasing in fitness; i.e. they do not have to necessarily be adaptive. In other words, for arbitrary evolutionary dynamics, evolution can follow (or access) nonadaptive paths. So, nonadaptive paths are accessible to arbitrary evolutionary dynamics; it would be awkward to say that nonaccessible paths are accessible to arbitrary evolutionary dynamics. If some particular evolutionary dynamic produces only adaptive paths, though, then it is called an adaptive dynamic. In general, adaptive paths can continue until they reach a local fitness optimum.
Definition 2. A genotype u is a local fitness optimum (sometimes also called a (local) fitness peak) if for all adjacent genotypes v, we have .
Note the above definition of a genotype as a local fitness optimum allows for adjacent genotypes of equal (or lesser) fitness. In particular, this means that points within a fitness plateau can be local fitness optima. At times, I will assume for simplicity that no two adjacent genotypes have exactly the same fitness to avoid considering fitness plateaus; but this is not an important restriction and all the hardness results can be reproved without it. A local fitness optimum is a global fitness optimum if all other genotypes in the whole of the genetic space (not just neighbors) have the same or lower fitness; i.e. if no other local fitness optimum in the whole of the genetic space has a higher fitness.
Sometimes it is useful to represent a fitness landscape as a fitness graph by replacing the fitness function by a flow: for adjacent genotypes in the mutation-graph, direct the edges from the lower to the higher fitness genotype. This results in a characterization of fitness landscapes of a biallelic system as directed acyclic graphs on . Fitness peaks would correspond to sinks, and adaptive paths would correspond to paths that follow the edge directions of the DAG. I will consider a population at evolutionary equilibrium if it finds a local peak in the fitness landscape; i.e. a sink in the fitness graph. Crona et al. (2013) introduced this representation into theoretical biology, but fitness graphs have been used implicitly in earlier empirical studies of fitness landscapes (de Visser et al. 2009; Franke et al. 2011; Goulart et al. 2013; Szendro et al. 2013). Using fitness graphs is particularly useful empirically because it is difficult to quantitatively compare fitnesses across experiments. However, if pairwise competitions are used to build an empirical fitness graph, it is important to verify that the graph is transitive (acyclic) (de Visser and Lenski 2002). In theoretical work, the fitness graph approach has made the proofs of some classical theorems relating local structure to global properties easier and shifts our attention to global algorithmic properties of evolution instead of specific numeric properties.
Throughout the report and these appendices, I consider individual genotypes or phenotypes as the domain of the fitness landscapes. Thus, I am focusing on microevolutionary processes. Given the extremely long time scales that I am considering in this report, it is also natural to consider generalizations where the vertices in the fitness landscape are interpreted as whole species and mutations as speciation events. For simplicity, I will not explicitly discuss such macroevolutionary processes.
A.1 Epistasis
Epistasis is a measure of the kind and amount of interlocus interactions. Consider two loci with the first having alleles a or A, and the second b or B. Assume that the uppercase combination is more fit: i.e. .
Definition 3. Two alleles are noninteracting if the fitness effects are additive and independent of background: , .
In magnitude epistasis this additivity is broken, but the signs remain: and . The difference between noninteracting alleles and magnitude epistasis is not invariant under rank-order preserving transformation of the fitness function, thus I will not distinguish between the two types. Throughout the paper, I will use “no epistasis” to mean both noninteracting alleles and magnitude epistasis, as the following definition makes explicit.
Definition 4. If and then we will say that there is no epistasis between those alleles.
A system has sign epistasis if it violates one of the two conditions for magnitude epistasis. For example, if the second locus is b then the mutation from a to A is not adaptive, but if the second locus is B then the mutation from a to A is adaptive.
Definition 5. Given two loci, if then there is sign epistasis at the first locus.
Finally, a system has reciprocal sign epistasis if both conditions of magnitude epistasis are broken, or if we have sign epistasis on both loci (Poelwijk et al. 2007, 2011; Crona et al. 2013).
Definition 6. Given two loci, if but and then there is reciprocal sign epistasis between those two loci.
Figure A.1 visualizes all the fitness graphs on two loci and categorizes the type of epistasis present.
B. Smooth Fitness Landscapes
If a fitness landscape has no sign epistasis then it is a smooth landscape and has a single peak (Weinreich et al. 2005; Crona et al. 2013). Every shortest path from an arbitrary x to in the mutation-graph is an adaptive path—a flow in the fitness graph—and every adaptive path in the fitness graph is a shortest path in the mutation graph (Crona et al. 2013). Thus, evolution can quickly find the global optimum in a smooth fitness landscape, with an adaptive path taking at most n steps: that is, all smooth fitness landscapes are easy landscapes. For an example, see the smooth Escherichia coli β-lactamase fitness landscape measured by Chou et al. (2011) in Figure 2a.
Proposition 7 (Weinreich et al. 2005; Crona et al. 2013). If there is no sign epistasis in a fitness landscape, then it is called a smooth landscape and has a single peak . Every shortest path (ignoring edge directions) from an arbitrary genotype x to is an adaptive path, and every adaptive path from x to is a shortest path (ignoring edge directions).
Where by “shortest path (ignoring edge directions),” I mean any shortest path in the mutation-graph, irrespective of if the fitness along the edges of that path increases (“up arrow”) or decreases (“down arrow”). In other words, an arbitrary shortest path between x and corresponds to an arbitrary swapping of genes at the loci on which x and from the value they have in x to the value in . This means, for example, that if x and differ on d loci, then there are many shortest paths between them, and, by Proposition 7, those are also the adaptive paths between them.
C. Semismooth Fitness Landscapes
Since a smooth landscape is always easy, let us introduce the minimal amount of epistasis: sign epistasis, without any reciprocal sign epistasis.
Definition 8. A semismooth fitness landscape on with fitness function f is a fitness landscape that has no reciprocal sign epistasis. Such a fitness function f is also called semismooth.
For some of the following proofs, it will be useful to define sublandscapes.
Definition 9. Given a landscape on n bits, a sublandscape spanned by is a landscape on where the alleles at the loci (indices) in S can vary but the indices in are fixed according to some string .
Note that the whole landscape is a sublandscape of itself (taking ). For any , there are many sublandscapes on S corresponding to the possible . Reciprocal sign epistasis between bits i and j corresponds to a sublandscape on that has two distinct peaks.
Now, I can note a couple of important properties of semismooth landscapes:
Proposition 10. If a fitness landscape on has some sublandscape with >1 distinct peak, then it has reciprocal sign epistasis.
The proof will show that a minimal multipeak sublandscape must have size 2. I will do this by considering longest walks in a sublandscape. The proposition is similar to the one proved by Poelwijk et al. (2011), although my proof is distinct.
Proof. Let us consider a minimal sublandscape L that has more than one distinct peak: that means that if this sublandscape is spanned by S (i.e. ) then no sublandscape spanned by has multiple peaks.
Since L is minimal, its peaks must differ from each other on each bit in S, for if there was a bit on which two peaks agreed, then that bit could be fixed to that value and eliminated from S to make a smaller sublandscape spanned by with two peaks. Thus, the minimal multipeak sublandscape has precisely two peaks. Call these peaks and .
Claim: In a minimal multipeak sublandscape, from each nonpeak vertex, there must be a path to each peak.
Let us prove the claim by contradiction: Consider an arbitrary nonpeak vertex x, and suppose it has no path to the peak. Since any path from x in L must terminate at some peak, take the longest path from x to the peak that it reaches, and let y be the last step in that path before the peak. Notice that y must only have one beneficial mutation (on bit i), the one to the peak. For if it had more than one beneficial mutation, it could take the nonpeak step to and then proceed from to ( is not an option by assumption, and there are only two peaks in L) and thus provide a longer path to the peak. Now consider the landscape on , with the ith bit fixed to . Since is the same as (both are opposite of ), is still a peak over , but so is y (since its only beneficial mutation was eliminated by fixing i to ). But this contradicts minimality, so no such x exists.
Now that we know that we can reach each peak from any vertex x, let us again consider the longest path from x to with y as the last step in that path before the peak, and i as the position of the last beneficial mutation. Since all nonpeak vertices must reach both peaks, there must be some other beneficial mutation j from y to that eventually leads to . But if is not a peak then it must also have a way to reach , but then we could make a longer path, contradicting the construction of y. Thus must be the peak
This means that and differ in only the two bits i and j. But, in a minimal multipeaked sublandscape, they must differ in all bits, so ; i.e. this sublandscape is an example of reciprocal sign epistasis.□
Corollary 11. A fitness landscape without reciprocal sign epistasis has a unique single peak.
Proof. This follows from the contrapositive of Proposition 10, since the whole landscape is a sublandscape of itself.□
The above results can also be restated in the terminology used to analyze simplex algorithms(Szabó and Welzl 2001; Matoušek and Szabó 2006).
Definition 12. A directed acyclic orientation of a hypercube is called an acyclic unique sink orientation (AUSO) if every subcube (face; including the whole cube) has a unique sink.
This makes the contrapositive of Proposition 10 into the following proposition:
Proposition 13. A semismooth fitness landscape is an AUSO.
Now, if we let mean XOR between x and y, and let mean the number of 1s in z, then we can state the main theorem about semismooth fitness landscapes:
Theorem 14. A semismooth fitness landscape has a unique fitness peak and, for any vertex x in the landscape, there exists a path of length (Hamming distance to peak) from x to the peak.
Proof. The unique peak is just a restatement of Corollary 11. To show that there is always a path of Hamming distance to the peak, I will show that, given an arbitrary x, we can always pick a mutation k that decreases the Hamming distance to by 1.
Let S be the set of indices that x and disagree on, . Consider the sublandscape on S with the other bits fixed to what x and agree on. In this sublandscape, is a peak, thus, by Proposition 10, x is not a peak and must have some beneficial mutation . This is the k we were looking for.□
Note that this proof specifies an algorithm for constructing a short adaptive walk to the fitness peak . However, this algorithm requires knowing ahead of time – i.e. seeing the peak in the distance. But evolution does not know ahead of time where peaks are, and so cannot carry out this algorithm. Even though a short path to the peak always exists, evolutionary dynamics might not follow it.
C.1. Hard landscapes for random fitter SSWM
The simplest evolutionary rule to consider is picking a mutation uniformly at random among ones that increase fitness. This can be restated as picking and following one of the out-edges in the fitness graph at random; i.e. this is equivalent to the random-edge simplex pivot rule (Matoušek and Szabó 2006). Proposition 13 allows me to use the hard AUSOs constructed by Matoušek and Szabó (2006) as a family of hard semismooth landscapes.
Theorem 15 (Matoušek and Szabó 2006 in biological terminology). There exist semismooth fitness landscapes on such that random fitter mutant SSWM dynamics starting from a random vertex, with probability at least follows an adaptive path of at least steps to evolutionary equilibrium.
In other words, multiple peaks—or even reciprocal sign-epistasis—are not required to make a complex fitness landscape. In fact, AUSOs were developed to capture the idea of a linear function on a polytope (although AUSOs are a slightly bigger class). It is not surprising to find the simplex algorithm in the context of semismooth landscapes, since we can regard it as a local search algorithm for linear programming where local optimality coincides with global optimality. Linear fitness functions are usually considered to be some of the simplest landscapes by theoretical biologists; showing that adaptation is hard on these landscapes (or ones like them) is a surprising result.
C.2 Construction of hard semismooth landscapes for fittest SSWM
One might object to taking random fitter mutants because sometimes the selected mutations are only marginally fitter than the wildtype. It might seem natural to speed-up evolution by always selecting the fittest possible mutant. Here, I show that, in general, this does not help.
Consider a fitness landscape on with semismooth fitness function f that if started at will take k steps to reach its evolutionary equilibrium at . I will show how to grow this into a fitness landscape on with semismooth fitness function that, if started at will take steps to reach its evolutionary equilibrium at .
For simplicity of analysis, let us define the following functions and variables for all points in that are not an evolutionary equilibrium under f; i.e. all except . Let
| (1) |
and
| (2) |
where are the neighbors of x in the mutation graphs; i.e. genotypes that differ from x in one bit.
Now, overload these into constants, as follows: define and . Suppose that f is such that ; otherwise set [do this also, if is empty for some nonequilibrium x].
Let mean the XOR between x and y. Consider the “reflected” function . I call this function reflected because we could visualize as the same function as , except it is mirrored (swapping the fitness effects of the 0 and 1 allele) along each locus i where . Note that if is semismooth then so is , since it just relabels the directions of some dimensions. The reflected function preserves all the important structure. In particular, if under it took k steps to go from to then, under it will take k steps to from to .
Now define as:
| (3) |
Basically, the subcube is the original landscape, the and subcubes serve as “buffers” to make sure that the walk does not leave the first subcube before reaching , and the is the original landscape reflected around that takes us from to .
Notice that has the same and as f.
Now we just need to establish some properties:
Proposition 16. Fittest mutant SSWM dynamics will not leave the subcube until reaching .
Proof. By definition, the fittest mutant (i.e. neighbor over ) from each genotype that is not in f, has a fitness advantage of or higher. Hence, adding two extra edges from to and , each with fitness advantage will not change the edge that fittest-mutant SSWM picks.□
Proposition 17. SSWM dynamics will not leave the subcube after entering it.
Proof. This is because has strictly greater fitness on the subcube than on the other three subcubes. Confirming this, note that, for every :
| (4) |
| (5) |
| (6) |
| (7) |
| (8) |
□
Proposition 18. If f on has no reciprocal sign-epistasis, then on has no reciprocal sign-epistasis.
Proof. Consider any pair of genes . Among these first m genes, depending the last two bits, we are looking at landscapes on , , , or , with the fitness given by ,,, or (respectively). All these landscapes have isomorphic combinatorial structure to f, and, thus, the same kinds of epistasis. Since f has no reciprocal sign-epistasis, all these subcubes lack it, too.
Now, let us look at the case of where the gene pair goes outside the first m genes. Consider an arbitrary gene , let , be arbitrary. Label such that Look at the subcube :
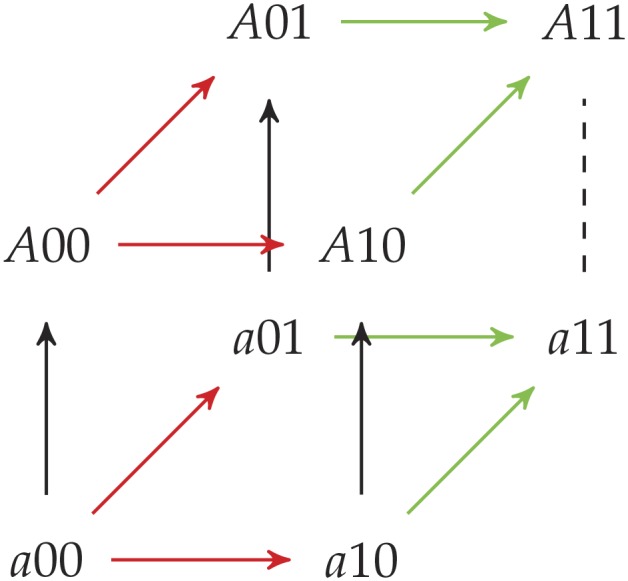
The solid black edges have their directions from the definition of a and A. The red edges have their direction because . The green edges have their direction because of Proposition 17. The direction of the dotted black edge will depend on if contains 0 (point up) or 1 (point down) at position i, but, regardless of the direction, no reciprocal sign epistasis is introduced.□
Corollary 19. Given on , the fittest mutant SSWM dynamics starting at will take steps to reach its unique fitness peak at .
Proof. By Proposition 16, the walk will first proceed to taking k steps. From , there are only two adaptive mutations or , and the first is fitter. From there is only a single adaptive mutation (to ), taking us to steps. From , by Proposition 17, it will take us k more steps to reach ; totaling steps.□
Theorem 20. There exist semismooth fitness landscapes on loci that take fittest mutant steps to reach their unique fitness peak at when starting from .
Proof. We will build the family of landscapes inductively using our construction, starting from an initial landscape:
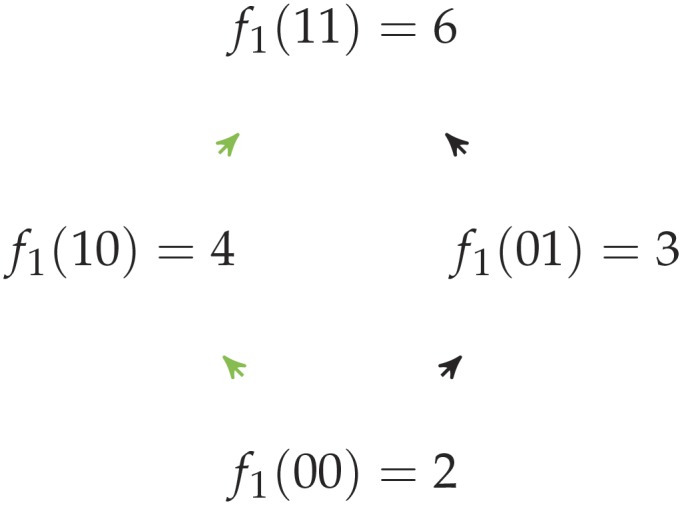
The resulting path length will be given by the recurrence equation: with . This recurrence is solved by .□
Call the landscapes constructed as in the above proof, a winding landscapes. A visual example of the winding landscape construction on six loci ( in Theorem 20) is given in Figure 3. The winding landscapes construction is similar to Horn et al. (1994)’s Root2path construction, except their approach introduced reciprocal sign epistasis despite having a single peak.
Of course, this is an arbitrary initial fitness landscape and any semismooth landscape can be used as a starting point; the walk would still scale exponentially, but there would be a different initial condition. Further, this winding product construction I showed above is just one example for building families. Many more could be considered.
In particular, if we are interested in larger mutation operators, like k-point mutations instead of just 1-point mutations, then it is relatively straightforward to modify the winding landscape construction. As written, Equation 3 uses a buffer of 2 bits in to transition from to its reflection . In the more general setting, we would pad the buffer to be bits: define where with a smooth landscape on the y portion of the input taking us from to its reflection, which leaves most of the above arguments unchanged, modifying only Theorem 20 to have the landscape to be on loci and the recurrence relation at the end of the proof to be .
C.3 Hard landscapes from random start
Unfortunately, one might not be impressed by a result that requires starting from a specific genotype like and ask for the expected length of the walk starting from a random vertex. Of course, if a genotype on this long walk is chosen as a starting point then the walk will still be long in most cases. However, there are only vertices in the walk, among vertices total, so the probability of landing on the walk is exponentially small. Instead, I will rely on direct sums of landscapes and Proposition 16 to get long expected walks.
Proposition 21. With probability , a winding landscape on loci will take or more fittest mutant steps to reach the fitness peak from a starting genotype sampled uniformly at random.
Proof. With probability , the randomly sampled starting vertex has the form (i.e. its last two bits are 0s). By Proposition 16, the walk cannot leave the landscape until reaching its peak at . This might happen quickly, or it might even already be at that peak. But afterwards, it has to follow the two steps to and then, due to Proposition 17, it will have to follow the normal long path, taking more steps.□
Because of the constant probability of an exponentially long walk, we can get a big lower bound on the expected walk time:
Corollary 22. Fittest mutant dynamics starting from a uniformly random genotype will have an expected walk length > on a -loci winding landscape.
Proof. With probability , the walk takes or more steps, and with probability it takes 0 or more steps. Thus, the expected walk length is ≥.□
However, of the time, we cannot make a guarantee of long dynamics. We can overcome this limitation by taking direct sums of landscapes.
Definition 23. Given two fitness landscapes, one with fitness on and the other with fitness on , the direct sum is a landscape with fitness f on where .
Now, for any probability of failure , let (where is base 2).
Theorem 24. There exist semismooth fitness landscapes on loci that with probability , take or more fittest mutant steps to reach their fitness peak from a starting genotype sampled uniformly at random.
Proof. Consider a landscape that is the direct sum of separate -loci winding landscapes. Since each constituent is semismooth, and, since sums do not introduce epistasis, the resulting “tensor sum” landscape is also semismooth. Further, to reach its single peak, the walk has to reach the peak of each of the independent winding sublandscapes. But as long as at least one sublandscape has a long walk, we are happy. By Proposition 21, we know that, for each sublandscape, we will have a short-walk starting genotype with probability <. The probability that none of them get a long walk then is <.□
D. NK Model with is PLS-Complete
Definition 25 (Kauffman and Levin 1987; Kauffman and Weinberger 1989; Kauffman 1993). The model is a fitness landscape on . The n loci are arranged in a gene-interaction network where each locus is linked to K other loci and has an associated fitness contribution function Given a vertex , we define the fitness .
By varying K we can control the amount of epistasis in the landscape. The model also provides an upper bound of on the number of gene pairs that have epistatic interactions. Typically in the biology and statistical physics literature, the fitness contributions and sometimes the gene-interaction network are chosen uniformly at random from some convenient probability distribution. In contrast, the approach of theoretical computer scientists is to consider arbitrary rather than random choices for each and sometimes the gene-interaction network. This is an important cultural difference in methodology between statistical physics and computer science that I discuss in more detail in subsection D.3.
Weinberger (1996) showed that checking if the global optimum in an model is greater than some input value V is -complete for . Although this implies that finding a global optimum is difficult, it says nothing about local optima. As such, it has generated little interest among biologists, although it spurred interest as a model in the evolutionary algorithms literature, leading to a refined proof of -completeness for (Wright et al. 2000).
To understand the difficulty of finding items with some local property like being an equilibrium, Johnson et al. (1988) defined the complexity class of polynomial local search (PLS). A problem is in PLS if it can be specified by three polynomial time algorithms (Roughgarden 2010):
1. An algorithm I that accepts an instance (like a description of a fitness landscape) and outputs a first candidate to consider (the initial genotype).
2. An algorithm F that accepts an instance and a candidate and returns a objective function value (i.e., computes the fitness).
3. An algorithm M that accepts an instance and a candidate and returns an output with a strictly higher objective function value, or says that the candidate is a local maximum.
We consider a PLS problem solved if an algorithm can output a locally optimal solution for every instance. This algorithm does not necessarily have to use I, F, or M or follow adaptive paths. For instance, it can try to uncover hidden structure from the description of the landscape. A classical example would be the ellipsoid method for linear programming. The hardest problems in PLS, i.e. ones for which a polynomial time solution could be converted to a solution for any other PLS problem, are called PLS-complete. It is believed that PLS-complete problems are not solvable in polynomial time (i.e. ; where stands for the set of function problems solvable in polynomial time), but, much like the famous question, this conjecture remains open. Note that finding local optima on fitness landscapes is an example of a PLS problem, where I is your method for choosing the initial genotype, F is the fitness function, and M computes an individual adaptive step.
Definition 26 (Weighted 2SAT). Consider n variables and m clauses and associated positive integer weights . Each clause contains two literals (a literal is a variable or its negation ), and contributes to the fitness if at least one of the literals is satisfied, and nothing if neither literal is satisfied. The total fitness is the sum of the individual contributions of the m clauses. Two assignments x and are adjacent if there is exactly one index i such that . We want to maximize fitness.
The Weighted 2SAT problem is PLS-complete (Schäffer and Yannakakis 1991). To show that the model is also PLS-complete, I will show how to reduce any instance of Weighted 2SAT to an instance of the model.
Theorem 27. Finding a local optimum in the NK fitness landscape with is PLS-complete.
Proof. Consider an instance of Weighted 2SAT with variables , clauses and positive integer costs . We will build a landscape with loci, with the first m labeled and the next n labeled . Each will correspond to a clause that uses the variables and (i.e., the first literal is either or and the second is or ; set to avoid ambiguity). Define the corresponding fitness effect of the locus as:
| (9) |
| (10) |
Link the arbitrarily (say to and , or to nothing at all) with a fitness effect of zero, regardless of the values.
In any local maximum , we have and . On the subcube with Weighted 2SAT and this NK model have the same exact fitness graph structure, and so there is a bijection between their local maxima.□
Assuming—as most computer scientists do—that there exists some problem in PLS not solvable in polynomial time (i.e. ), then Theorem 27 implies that, no matter what mechanistic rule evolution follows (even ones we have not discovered, yet), be it as simple as SSWM or as complicated as any polynomial time algorithm, there will be NK landscapes with such that evolution will not be able to find a fitness peak efficiently. But if we focus only on rules that follow adaptive paths then we can strengthen the result:
Corollary 28. There is a constant such that, for infinitely many n, there are instances of models (with ) on and initial genotype v such that any adaptive path from v will have to take at least steps before finding a fitness peak.
Proof. If the initial vertex has then there is a bijection between adaptive paths in the fitness landscape and any weight-increasing path for optimizing the weighted 2SAT problem. Thus, Schäffer and Yannakakis (1991)’s Theorem 5.15 applies.□
This result holds independent of any complexity theoretic assumptions about the relationship between polynomial-time and PLS. Hence, there are some landscapes and initial genotypes, such that any rule we use for adaptation that only considers fitter single-gene mutants will take an exponential number of steps to find the local optimum.
If we turn to larger mutational neighborhoods than singe-gene mutants then—due to the large class of possible adaptive dynamics—a variant of Corollary 28 will have to be reproved (often using a buffer padding argument similar to the end of section C.2) but Theorem 27 is unaffected:
Corollary 29. For any definition of local equilibrium with respect to a mutation neighborhood that contains point-mutations as a subset (i.e. if ), the NK model with is PLS-hard.
Proof. Any mutation operator that is a superset of point-mutations will only decrease the number of evolutionary equilibria without introducing new ones. Thus, it will only make the task of finding that equilibrium (just as, or) more difficult. However, since the algorithms studied by PLS do not have to use the mutation operator during their execution, changing it does not give them any more computational resources.□
Finally, it is important to see the NK-model as an example model, albeit a simple and natural one. If we consider more complex models of fitness landscapes—say dynamic fitness landscapes—it is often the case that there is some parameter or limit that produces the special case of a static fitness landscape like the NK-model. In particular, static landscapes are often a submodel of dynamic fitness landscapes, and, thus, solving dynamic fitness landscapes can only be more difficult that static ones.
Table A1. Summary of main results.
| Landscape type | Max allowed epistasis type | Hardness of reaching local optima | Proved in... |
|---|---|---|---|
| Smooth | magnitude () | Easy for all strong-selection weak-mutation (SSWM) dynamics | Section B |
| Semismooth | sign (,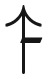 ) ) |
Hard for SSWM with random fitter mutant | Theorems 15, |
| or fittest mutant dynamics | 20, and 24 | ||
| Rugged | reciprocal sign () |
Hard for all SSWM dynamics: initial genotypes with all adaptive paths of exponential length | Corollary 28 |
| Hard for all evolutionary dynamics (if FP ≠ PLS) | Theorem 27 | ||
| Easy for finding approximate local peaks with moderate optimality gap: selection coefficients can drop-off as power law | Theorem 33 | ||
| Hard for approximate local peaks with small optimality gap: | Theorem 35 | ||
| selection coefficient cannot drop-off exponentially | Corollary 36 |
Each landscape type (column 1) is characterized by the most complicated permitted type of epistasis (column 2; see A.1). Based on this, there are families of this landscape type that are easy or hard under progressively more general dynamics (column 3), which is proved in the corresponding part of the appendix (column 4).
D.1 Easy instances of NK-model
Note that this does not mean that all instances of the NK-model are hard. In fact, there are natural subfamilies of the NK-model that are easy.
The simplest easy family is . In that case, the genes are noninteracting and we have a smooth fitness landscapes. And all smooth landscapes are easy. For , Wright et al. (2000) presented a dynamic programming approach that can find the global fitness peak in polynomial time. Since we could use this as our algorithm I to pick the initial genotype, this means the model cannot be PLS-complete for (unless PLS = P, in which case all local search problems are easy). This means that Theorem 27 is as tight as possible in terms of K.
Alternatively, instead of restricting K, we can restrict how the gene-interaction network is connected. It will come in useful to visualize these gene-interaction networks by drawing an edge directed from a focal locus to the K loci that affect its fitness contribution. For example, if the genes can be arranged in a circle and a focal gene can interact with only the next K genes in the circle, then there is a polynomial time dynamic programming algorithm to find an evolutionary equilibrium (Wright et al. 2000). Thus, this restricted model cannot be PLS complete for any constant K.
It is an open question if SSWM dynamics—or some other reasonable evolutionary dynamics—is sufficient in the cases of and circular arrangements. I conjecture that adaptive dynamics are sufficient in these cases, but proof of this is left for future work.
Some of the most common kinds of easy instances of the NK-model come from “simplifying” restrictions put in place by the modeler. In particular, restriction on the range of the fitness function.
Proposition 30. If the number of distinct fitness values that fitness functions map to is bounded by a polynomial then the corresponding fitness landscapes are easy.
Proof. Any adaptive step increases the fitness value, and by transitivity, a fitness value is never repeated in an adaptive path. Thus, all adaptive paths are at most polynomially long: more specifically, bounded by one less than the number of distinct fitness values in the range of the fitness function.□
Note that the above theorem does not put any constraints on what those fitness values are and thus depends only on the rank ordering (i.e. on the existence of very large rank equivalence classes). For variants that looks at the exact numeric values, see SA D.2 and Proposition 32.
The most notable application of Proposition 30 might be to the original Gavrilets and Gravner (1997) formulation of holey adaptive landscapes. Gavrilets and Gravner (1997) decided to divide the range of fitness values into just two components: 1 for viable and 0 for nonviable. An adaptive path in such a landscape can be at most one step long: if you start at a nonviable point right next to a viable one. Thus, all viability landscapes (like the original holey ones) are easy. Note that this does not mean fitness plateaus or neutral networks are easy to reach. If we remove the modeling restriction of just 0 or 1 fitness values and allow a large range of values then that does not eliminate the possibility of large fitness plateaus. In other words, fitness landscapes could have large plateaus of fitness but still be hard: i.e. it will be difficult to reach the plateau. Of course, more work should be done in the future on the topic of hardness of large neutral networks.
D.2 Approximate peaks
If we are to discuss neutral plateaus or networks then it is also important to consider nearly-neutral networks. For this, we need to use the whole numeric structure of the fitness function f, and not just the rank-ordering that was sufficient until this point. Thus, let us consider relaxations of equilibrium, and being “close” to a peak instead of exactly at one. The following definitions and proofs are based on combinatorial optimization results by Orlin et al. (2004).
Definition 31. A genotype x is at an s-approximate peak if .
The question becomes how big does s have to be for evolution to find an s-approximate peak. But, since there is no absolute units of fitness, we will need to define and .
First, it is important to note that all landscapes where is not small compared to are easy.
Proposition 32. If for some constant k then an exact peak can be found in a polynomial in n number of mutations by any adaptive dynamic.
Proof. Since each adaptive step increases fitness by at least then, after t adaptive steps, we have . Combine this with to get that .□
So, we need to focus on bigger gaps between and . If the gap is exponential, then we can find approximate peak for moderate sized s on any landscape.
Theorem 33. If then fittest mutant SSWM dynamics can find a local s-approximate peak in time polynomial in n and .
Proof. Let be the initial genotype, if it is an exact peak then we are done. Otherwise, let be the next adaptive step, by definition of , we have that . Now, consider an adaptive path that has not encountered an s-approximate peak; i.e. a mutation was always available such that . Thus, we have that and that . Putting these two together:
| (11) |
| (12) |
| (13) |
Where I used in the last step. Combining with the conditions on , we get: .
But for very small s, finding an approximate peak is as hard as finding an exact peak.□
Proposition 34. If then any s-approximate peak is a (exact) local peak.
Proof. If an s-approximate peak at x is not an exact peak then there exists a such that but . Combining this with , we get that .□
Thus, it is not possible to find an s-approximate peak for very small s on hard fitness landscapes:
Theorem 35. If and then (for NK-model with ) a local s-approximate peak cannot be found in time polynomial in n and .
Proof. If such an algorithm existed then we would run it with and—by Proposition 34—the approximate peak it finds would be exact. Further, in this case and, thus, the runtime would be polynomial in n. This is not possible for the NK-model with by Theorem 27 (unless ).□
This also means that the selective coefficient of the fittest mutant cannot decay exponentially quickly.
Corollary 36. If then there are no evolutionary dynamics such that for all instances of the NK-model with .
Contrast this with the always achievable power-law decrease in .
D.3 Distributions and random fitness landscapes
The model is frequently studied through simulation, or statistical mechanics approaches. In a typical biological treatment, the gene-interaction network is assumed to be something simple like a generalized cycle (where is linked to ) or a random K-regular graph. The fitness contributions are usually sampled from some choice of distribution. As such, we can think of biologists as doing average case analysis of these fitness landscapes. Given that randomly sampling landscapes can introduce structure like short paths (Tovey 1986), I suspect that the structure of this simple sampling led prior research to miss the possibility of exponentially long walks. The independent sampling of fitness components from the same distributions is especially apt to realize the conditions of Proposition 32, since it makes it unlikely to create an exponential gap between the smallest positive fitness gap and the maximum achievable fitness . Future work could provide a more careful analysis of this conjecture.
Given a historical disconnect between theory and data (Orr 2005; Kryazhimskiy et al. 2009), the choice for distributions was usually made out of analytic convenience or (occasionally) out of the belief that a uniform distribution is akin to no assumption Since there is no strong empirical or theoretically sound justification for the choice of particular distributions of large fitness landscapes, I avoid relying on a simple generating distribution and instead reason from only the logical description of the model. This can be thought of as worst-case analysis, or as analysis for arbitrary distributions of landscapes. By following this approach, we know that our results are features of the logic that characterizes a particular family of fitness landscapes and not artifacts of a particular simple sampling distribution. This is a standard method in theoretical computer science, but it is not as common in statistical physics or biology.
Figure A.1.

Three different kinds of epistasis possible in fitness graphs: no epistasis (), sign epistasis (, ), and reciprocal sign epistasis (). Arrows in the fitness graph are directed from lower fitness genotypes toward mutationally adjacent higher fitness genotypes. In the middle of each fitness graph is a symbol showing the kind (and orientation) of epistasis. Note that the bottom left () and top right () fitness graphs violate transitivity.
Although there is evidence for simple distributions on small fitness landscapes [on up to eight genes; see Franke et al. (2011) and Szendro et al. (2013)], there is little to no data on the distribution of large (i.e. on many loci) fitness landscapes in nature. And, as discussed in the main text, given the exponential size of fitness landscapes, it is unlikely that such data could be collected. However, if a single sampling distribution is required, then it is tempting to turn to Occam’s razor and consider simpler landscapes as more likely. This can be done by sampling landscapes with negative log probability proportional to their minimum description length, i.e. according to the Kolmogorov universal distribution. If landscapes are sampled in this way, then I would expect all the orders of magnitude for hardness results established herein to hold (Li and Vitányi 1992). However, I leave it as an open question for future work to prove this formally, and to contrast the ubiquity of hardness in fitness landscapes sampled under different theoretical distributions. As outlined above, it would be especially interesting to analyze the uniform distribution (that is popular in statistical physics) vs. the Kolmogorov universal distribution (that is used in theoretical computer science).
Footnotes
Communicating editor: N. Barton
Literature Cited
- Ariew A., 2003. Ernst Mayr’s ‘ultimate/proximate’ distinction reconsidered and reconstructed. Biol. Philos. 18: 553–565. 10.1023/A:1025565119032 [DOI] [Google Scholar]
- Baldwin J. M., 1896. A new factor in evolution. Am. Nat. 30: 441–451. 10.1086/276408 [DOI] [Google Scholar]
- Bank C., Matuszewski S., Hietpas R. T., Jensen J. D., 2016. On the (un)predictability of a large intragenic fitness landscape. Proc. Natl. Acad. Sci. USA 113: 14085–14090. 10.1073/pnas.1612676113 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Barton N., Partridge L., 2000. Limits to natural selection. BioEssays 22: 1075–1084. [DOI] [PubMed] [Google Scholar]
- Boltzmann L., 1896. Entgegnung auf die wärmetheoretischen Betrachtungen des Hrn. E. Zermelo. Ann. Phys. 293: 773–784. 10.1002/andp.18962930414 [DOI] [Google Scholar]
- Chapdelaine P., Creignou N., 2005. The complexity of Boolean constraint satisfaction local search problems. Ann. Math. Artif. Intell. 43: 51–63. 10.1007/s10472-005-0419-3 [DOI] [Google Scholar]
- Chatterjee K., Pavlogiannis A., Adlam B., Nowak M. A., 2014. The time scale of evolutionary innovation. PLoS Comput. Biol. 10: e1003818 10.1371/journal.pcbi.1003818 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Chou H. H., Chiu H. C., Delaney N. F., Segrè D., Marx C. J., 2011. Diminishing returns epistasis among beneficial mutations decelerates adaptation. Science 332: 1190–1192. 10.1126/science.1203799 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Couce A., Tenaillon O. A., 2015. The rule of declining adaptability in microbial evolution experiments. Front. Genet. 6: 99 10.3389/fgene.2015.00099 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Crespi B. J., 2000. The evolution of maladaptation. Heredity 84: 623 10.1046/j.1365-2540.2000.00746.x [DOI] [PubMed] [Google Scholar]
- Crona K., Greene D., Barlow M., 2013. The peaks and geometry of fitness landscapes. J. Theor. Biol. 317: 1–10. 10.1016/j.jtbi.2012.09.028 [DOI] [PMC free article] [PubMed] [Google Scholar]
- de Visser J. A., Park S. C., Krug J., 2009. Exploring the effect of sex on empirical fitness landscapes. Am. Nat. 174: S15–S30. 10.1086/599081 [DOI] [PubMed] [Google Scholar]
- de Visser J. A. G. M., Lenski R. E., 2002. Long-term experimental evolution in Escherichia coli. XI. Rejection of non-transitive interactions as cause of declining rate of adaptation. BMC Evol. Biol. 2: 19 10.1186/1471-2148-2-19 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Domingo J., Diss G., Lehner B., 2018. Pairwise and higher-order genetic interactions during the evolution of a tRNA. Nature 558: 117–121. 10.1038/s41586-018-0170-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Franke J., Klözer A., de Visser J., Krug J., 2011. Evolutionary accessibility of mutational pathways. PLoS Comput. Biol. 7: e1002134 10.1371/journal.pcbi.1002134 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Gavrilets S., 2003. Evolution and speciation in a hyperspace: the roles of neutrality, selection, mutation, and random drift, pp. 135–162 in Evolutionary Dynamics: Exploring the Interplay of Selection, Accident, Neutrality, and Function, edited by Crutchfield J. P., Schuster P. Oxford University Press, Oxford. [Google Scholar]
- Gavrilets S., Gravner J., 1997. Percolation on the fitness hypercube and the evolution of reproductive isolation. J. Theor. Biol. 184: 51–64. 10.1006/jtbi.1996.0242 [DOI] [PubMed] [Google Scholar]
- Gillespie J., 1983. A simple stochastic gene substitution model. Theor. Popul. Biol. 23: 202–215. 10.1016/0040-5809(83)90014-X [DOI] [PubMed] [Google Scholar]
- Gillespie J., 1984. Molecular evolution over the mutational landscape. Evolution 38: 1116–1129. 10.1111/j.1558-5646.1984.tb00380.x [DOI] [PubMed] [Google Scholar]
- Gillespie J., 1991. The Causes of Molecular Evolution. Oxford University Press, Oxford. [Google Scholar]
- Gillespie J. H., 2010. Population Genetics: A Concise Guide. John Hopkins University Press, Baltimore. [Google Scholar]
- Goulart C., Mentar M., Crona K., Jacobs S., Kallmann M., et al. , 2013. Designing antibiotic cycling strategies by determining and understanding local adaptive landscapes. PLoS One 8: e56040 10.1371/journal.pone.0056040 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Hammarlund S. P., Connelly B. D., Dickinson K. J., Kerr B., 2016. The evolution of cooperation by the Hankshaw effect. Evolution 70: 1376–1385. 10.1111/evo.12928 [DOI] [PubMed] [Google Scholar]
- Heredia J. P., Trubenová B., Sudholt D., Paixão T., 2017. Selection limits to adaptive walks on correlated landscapes. Genetics 205: 803–825. 10.1534/genetics.116.189340 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Horn J., Goldberg D. E., Deb K., 1994. Long path problems, pp. 149–158 in International Conference on Parallel Problem Solving from Nature Springer, Berlin, Heidelberg: 10.1007/3-540-58484-6_259 [DOI] [Google Scholar]
- Hwang S., Schmiegelt B., Ferretti L., Krug J., 2018. Universality classes of interaction structures for NK fitness landscapes. J. Stat. Phys. 172: 226–278. 10.1007/s10955-018-1979-z [DOI] [Google Scholar]
- Johnson D., Papadimitriou C., Yannakakis M., 1988. How easy is local search? J. Comput. Syst. Sci. 37: 79–100. 10.1016/0022-0000(88)90046-3 [DOI] [Google Scholar]
- Kanade, V., 2012 Computational questions in evolution. Ph.D. Thesis, Harvard University, Cambridge, MA. [Google Scholar]
- Kauffman S., 1993. The Origins of Order: Self-Organization and Selection in Evolution. Oxford University Press, Oxford. [Google Scholar]
- Kauffman S., Levin S., 1987. Towards a general theory of adaptive walks on rugged landscapes. J. Theor. Biol. 128: 11–45. 10.1016/S0022-5193(87)80029-2 [DOI] [PubMed] [Google Scholar]
- Kauffman S., Weinberger E., 1989. The NK model of rugged fitness landscapes and its application to maturation of the immune response. J. Theor. Biol. 141: 211–245. 10.1016/S0022-5193(89)80019-0 [DOI] [PubMed] [Google Scholar]
- Kaznatcheev A., 2013. Complexity of evolutionary equilibria in static fitness landscapes. arXiv: 1308.5094v1.
- Kryazhimskiy S., Tkacik G., Plotkin J., 2009. The dynamics of adaptation on correlated fitness landscapes. Proc. Natl. Acad. Sci. USA 106: 18638–18643. 10.1073/pnas.0905497106 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lenski R. E., Wiser M. J., Ribeck N., Blount Z. D., Nahum J. R., et al. , 2015. Sustained fitness gains and variability in fitness trajectories in the long-term evolution experiment with Escherichia coli. Proc. Bio. Sci. 282: 20152292 10.1098/rspb.2015.2292 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Levinthal D. A., 1997. Adaptation on rugged landscapes. Manage. Sci. 43: 934–950. 10.1287/mnsc.43.7.934 [DOI] [Google Scholar]
- Li C., Qian W., Maclean C. J., Zhang J., 2016. The fitness landscape of a tRNA gene. Science 352: 837–840. 10.1126/science.aae0568 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Li M., Vitányi P. M., 1992. Average case complexity under the universal distribution equals worst-case complexity. Inf. Process. Lett. 42: 145–149. 10.1016/0020-0190(92)90138-L [DOI] [Google Scholar]
- Livnat A., Papadimitriou C., 2016. Sex as an algorithm: the theory of evolution under the lens of computation. Commun. ACM 59: 84–93. 10.1145/2934662 [DOI] [Google Scholar]
- Livnat A., Papadimitriou C., Dushoff J., Feldman M. W., 2008. A mixability theory for the role of sex in evolution. Proc. Natl. Acad. Sci. USA 105: 19803–19808. 10.1073/pnas.0803596105 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lozovsky E. R., Chookajorn T., Brown K. M., Imwong M., Shaw P. J., et al. , 2009. Stepwise acquisition of pyrimethamine resistance in the malaria parasite. Proc. Natl. Acad. Sci. USA 106: 12025–12030. 10.1073/pnas.0905922106 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Matoušek J., Szabó T., 2006. RANDOM EDGE can be exponential on abstract cubes. Adv. Math. 204: 262–277. 10.1016/j.aim.2005.05.021 [DOI] [Google Scholar]
- Mayr E., 1961. Cause and effect in biology. Science 134: 1501–1506. 10.1126/science.134.3489.1501 [DOI] [PubMed] [Google Scholar]
- Obolski U., Ram Y., Hadany L., 2018. Key issues review: evolution on rugged adaptive landscapes. Rep. Prog. Phys. 81: 012602 10.1088/1361-6633/aa94d4 [DOI] [PubMed] [Google Scholar]
- Ohta T., 1992. The nearly neutral theory of molecular evolution. Annu. Rev. Ecol. Syst. 23: 263–286. 10.1146/annurev.es.23.110192.001403 [DOI] [Google Scholar]
- Orlin J., Punnen A., Schulz A., 2004. Approximate local search in combinatorial optimization. SIAM J. Comput. 33: 1201–1214. 10.1137/S0097539703431007 [DOI] [Google Scholar]
- Orr H. A., 2002. The population genetics of adaptation: the adaptation of DNA sequences. Evolution 56: 1317–1330. 10.1111/j.0014-3820.2002.tb01446.x [DOI] [PubMed] [Google Scholar]
- Orr H. A., 2003. The distribution of fitness effects among beneficial mutations. Genetics 163: 1519–1526. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Orr H. A., 2005. The genetic theory of adaptation: a brief history. Nat. Rev. Genet. 6: 119–127. 10.1038/nrg1523 [DOI] [PubMed] [Google Scholar]
- Orzack S. H., Sober E. (Editors), 2001. Adaptationism and Optimality. Cambridge University Press, Cambridge, UK: 10.1017/CBO9780511609084 [DOI] [Google Scholar]
- Pavlogiannis A., Tkadlec J., Chatterjee K., Nowak M. A., 2018. Construction of arbitrarily strong amplifiers of natural selection using evolutionary graph theory. Commun. Biol. 1: 71 10.1038/s42003-018-0078-7 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Poelwijk F., Kiviet D., Weinreich D., Tans S., 2007. Empirical fitness landscapes reveal accessible evolutionary paths. Nature 445: 383–386. 10.1038/nature05451 [DOI] [PubMed] [Google Scholar]
- Poelwijk F., Sorin T.-N., Kiviet D., Tans S., 2011. Reciprocal sign epistasis is a necessary condition for multi-peaked fitness landscapes. J. Theor. Biol. 272: 141–144. 10.1016/j.jtbi.2010.12.015 [DOI] [PubMed] [Google Scholar]
- Puchta O., Cseke B., Czaja H., Tollervey D., Sanguinetti G., et al. , 2016. Network of epistatic interactions within a yeast snoRNA. Science 352: 840–844. 10.1126/science.aaf0965 [DOI] [PMC free article] [PubMed] [Google Scholar]
- Rivkin J. W., Siggelkow N., 2007. Patterned interactions in complex systems: implications for exploration. Manage. Sci. 53: 1068–1085. 10.1287/mnsc.1060.0626 [DOI] [Google Scholar]
- Roughgarden T., 2010. Computing equilibria: a computational complexity perspective. Econ. Theory 42: 193–236. 10.1007/s00199-009-0448-y [DOI] [Google Scholar]
- Schäffer A., Yannakakis M., 1991. Simple local search problems that are hard to solve. SIAM J. Comput. 20: 56–87. 10.1137/0220004 [DOI] [Google Scholar]
- Simpson G. G., 1953. The Baldwin effect. Evolution 7: 110–117. 10.1111/j.1558-5646.1953.tb00069.x [DOI] [Google Scholar]
- Szabó T., Welzl E., 2001. Unique sink orientations of cubes, pp. 547–555 in Proceedings of the 42nd IEEE Symposium on Foundations of Computer Science IEEE, Piscataway, NJ. 10.1109/SFCS.2001.959931 [DOI] [Google Scholar]
- Szendro I. G., Schenk M. F., Franke J., Krug J., de Visser J. A. G. M., 2013. Quantitative analyses of empirical fitness landscapes. J. Stat. Mech. 2013: P01005 10.1088/1742-5468/2013/01/P01005 [DOI] [Google Scholar]
- Tovey C. A., 1986. Low order polynomial bounds on the expected performance of local improvement algorithms. Math. Program. 35: 193–224. 10.1007/BF01580647 [DOI] [Google Scholar]
- Valiant L., 2009. Evolvability. J. Assoc. Comput. Mach. 56: article no. 3. 10.1145/1462153.1462156 [DOI] [Google Scholar]
- Weinberger, E., 1996. “NP completeness of Kauffman’s N-k model, a tunably rugged fitness landscape.” Santa Fe Institute working paper: 1996–02–003.
- Weinreich D., Watson R., Chan L., 2005. Sign epistasis and genetic constraint on evolutionary trajectories. Evolution 59: 1165–1174. [PubMed] [Google Scholar]
- Wilf H. S., Ewens W. J., 2010. There’s plenty of time for evolution. Proc. Natl. Acad. Sci. USA 107: 22454–22456. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Wiser M. J., Ribeck N., Lenski R. E., 2013. Long-term dynamics of adaptation in asexual populations. Science 342: 1364–1367. 10.1126/science.1243357 [DOI] [PubMed] [Google Scholar]
- Wright A. H., Thompson R. K., Zhang J., 2000. The computational complexity of N-K fitness functions. IEEE Trans. Evol. Comput. 4: 373–379. 10.1109/4235.887236 [DOI] [Google Scholar]
- Wright S., 1932. The roles of mutation, inbreeding, crossbreeding, and selection in evolution, pp. 356–366 in Proceedings of the Sixth International Congress of Genetics Brooklyn Botanic Garden, Ithaca, NY. [Google Scholar]