

Summary
In many biomedical applications, interest focuses on the occurrence of two or more consecutive failure events and the relationship between event times, such as age of disease onset and residual lifetime. Bivariate survival data with interval sampling arise frequently when disease registries or surveillance systems collect data based on disease incidence occurring within a specific calendar time interval. The initial event is then retrospectively confirmed and the subsequent failure event may be observed during follow-up. In life history studies, the initial and two consecutive failure events could correspond to birth, disease onset and death. The statistical features and bias of observed data in relation to interval sampling were discussed by Zhu & Wang (2012). Here we propose nonparametric estimation of the association between bivariate failure times based on Kendall’s tau for data collected with interval sampling. A nonparametric estimator is given, where the contribution of each comparable and orderable pair is weighted by the inverse of the associated selection probability. Analysis methods for bivariate survival data with interval sampling rely on the assumption of quasi-independence, i.e., that bivariate failure times and the time of the initial event are independent in the observable region. This paper develops a nonparametric test of quasi-independence based on a bivariate conditional Kendall’s tau for such data. Simulation studies demonstrate that the association estimator and testing procedure perform well with moderate sample sizes. Illustrations with two real datasets are provided.
Keywords: Bivariate survival data, Dependence, Interval sampling, Kendall’s tau, U-statistic
1. Introduction
In natural history studies of diseases, interest often lies in two or more consecutive failure events and the relationship between event times. For instance, in HIV progression through successive stages, birth is the initial event, and HIV infection and death are the consecutive bivariate failure events. Disease registries or surveillance systems commonly collect data with onset of disease constrained to lie within a specific calendar time interval. This type of sampling is referred to as interval sampling, where the initial event is retrospectively identified and the subsequent bivariate failure events are observed during follow-up. Interval sampling occurs because only individuals diagnosed with disease within a specific time interval can be included, and the data represent a nonrandomly screened subset of a population. For example, for individuals having a fixed date of birth, those with an early age of disease onset cannot be sampled. Therefore, methods of analysis must account for biased sampling.
Examples of such data are seen in a study of HIV seroconversion and subsequent death, and in a study of the natural history of ovarian cancer. In the first example, over 800 subjects aged 15–49 years were ascertained with HIV seroconversion between 1995 and 2003 (Lutalo et al., 2007). Investigators recorded the date of birth, date of HIV seroconversion and subsequent time of death or censoring. The second example involves a cohort of patients, from the Surveillance, Epidemiology and End Results database, diagnosed with ovarian cancer between 1995 and 2002 (Ries et al., 2005). The patients’ dates of birth were ascertained retrospectively, and dates of death were recorded prospectively until the end of 2002.
A common feature of data collected with interval sampling is that the study cohort under interval sampling is made up of subjects experiencing the first failure event within a specific calendar time interval [0, t0]. Let us denote the calendar time of the initial event by B, the time from the initial event to the first failure event by X, the time from the first event to the second event by Y, and the time from the initial event to the time of censoring by C, where C ⩽ t0 – B. The bivariate failure times of interest are (X, Y). Under interval sampling, a subject is included in the sample only if 0 ⩽ X + B ⩽ t0; that is, observation of the first failure time X is doubly truncated. The observation of the second failure time Y could be further complicated by right censoring. Conditional on 0 ⩽ X + B ⩽ t0, the observed data include independent and identically distributed copies of (B, X, , δ), where = min(Y, C – X) and δ = I (Y ⩽ C – X). The primary aim of this paper is to investigate the dependence structure of the triplet (B, X, Y).
The measurement of association has long been a major topic in bivariate survival analysis. For example, in HIV studies, the dependence between age at HIV infection and residual lifetime reveals useful information about HIV progression. However, analyses of such consecutive failure times, commonly termed gap times, are challenging because within-subject gap time associations induce dependent censoring for the second and subsequent failure times (Lin et al., 1999). It is appealing to develop methods with simple measures of association between gap times in life history processes in order to quantitatively describe the dependence between the two consecutive event times, taking into account disease virulence and possibly natural ageing. This suggests estimation of Kendall’s tau, a popular measure of association between two random variables which does not depend on the marginal distribution. Because of its rank-invariance, Kendall’s tau is suitable for measuring dependence in lifetime models. Lakhal-Chaieb et al. (2010), for example, discussed the analysis of the association between gap times based on Kendall’s tau for follow-up data from a randomized trial of patients with colon cancer (Moertel et al., 1990), with respect to the lifetime process from randomization to cancer recurrence to death. Alternatively, copulas have become an attractive tool for the semiparametric modelling of bivariate survival data. For bivariate right-censored data, Shih & Louis (1995) developed a semiparametric association estimator through a copula model-based two-stage procedure. This method was extended to bivariate survival data with interval sampling to study the association, and it was applied to the ovarian cancer data (Ries et al., 2005) for a joint analysis of age of cancer onset and residual lifetime (Zhu & Wang, 2012). For complete data, Kendall’s tau can be consistently estimated by an empirical estimator. For bivariate right-censored data, several nonparametric estimators have been developed (Oakes, 1982; Wang & Wells, 2000; Lakhal-Chaieb et al., 2010). Nevertheless, nonparametric estimation of Kendall’s tau in the presence of both censoring and truncation has not been systematically investigated. In this paper, we propose a nonparametric estimate of Kendall’s tau as a measure of association between bivariate failure times for data collected with interval sampling.
Most methods proposed in the literature on survival data under truncation (Tsui et al., 1988; Efron & Petrosian, 1999) make the key assumption of independence or a weaker assumption of quasi-independence, namely that the truncation time and failure time are independent, or independent in the observable region. Kendall’s tau serves as the basis of popular nonparametric tests of independence between two random variables. Most survival data are subject to censoring and/or truncation, so Kendall’s tau is not directly applicable. For survival data under truncation, several authors have proposed tests for quasi-independence between truncation and failure times via a conditional Kendall’s tau; see Martin & Betensky (2005) for a review. In analysing bivariate survival data with interval sampling, we have adopted a similar assumption of independence between B and (X, Y), which supposes that the disease process does not depend on when the initial event occurs. However, this independence assumption may be questionable when, for example, an improved screening strategy has been developed which potentially leads to earlier disease detection, or an effective treatment has become available during the observation interval. Further, since we only observe data in the region − B ⩽ X ⩽ t0 − B due to interval sampling, we cannot identify the relationship between B and (X, Y) outside the region, and so cannot determine whether they are independent. Quasi-independence between B and (X, Y) in the observable region implies that the joint density of (B, X, Y) factors into a product proportional to the density of B and the joint density of (X, Y) in the region − B ⩽ X ⩽ to − B. Methods for bivariate survival data with interval sampling still work under quasi-independence. The second purpose of this paper is to develop a procedure to test nonparametrically the assumption of quasi-independence based on a bivariate conditional Kendall’s tau which quantifies the association between B and (X, Y). The two major issues considered in this paper, association estimation and quasi-independence testing, centre on the dependence structure of the triplet (B, X, Y).
2. Nonparametric estimation of unconditional Kendall’s tau
Kendall’s tau (Kendall & Gibbons, 1990) quantifies any association between random variables X and Y. Let (X1, Y1) and (X2, Y2) be independent and identically distributed copies of (X, Y). Kendall’s tau is defined as
where sgn(u) is the sign of u. The pair (1, 2) is said to be concordant if (X1 − X2)(Y1 − Y2) > 0, and discordant if (X1 − X2)(Y1 − Y2) < 0. Clearly, −1 ⩽ τ ⩽ 1, and this association measure equals zero when X and Y are independent. For completely observed data {(Xi, Yi): i = 1,…, n}, τ can be consistently estimated by
which is an unbiased U-statistic (Randles & Wolfe, 1991) with the property that converges weakly to a normal distribution as n → ∞. For bivariate data under censoring, various estimates of τ have been developed. With censored observations, the concordance status can be established only for orderable pairs, making estimation of τ difficult. Oakes (1982) suggested an estimator using only orderable pairs, which is inconsistent when bivariate survival data are not independent and also ignores partial information provided by censored data. Lakhal-Chaieb et al. (2010) introduced a modification of Oakes’s estimator by a Horvitz–Thompson-type correction, where the contribution of each orderable pair is weighted by the inverse of the associated selection probability; this estimator enjoys consistency and asymptotic normality.
For bivariate survival data with interval sampling, Zhu & Wang (2012) considered semiparametric association estimation of bivariate failure times (X, Y) based on a copula model under the assumption that B is independent of (X, Y), although this independence assumption can be relaxed to quasi-independence. In the present paper, we focus on an unconditional Kendall’s tau, τXY = E[sgn{X1 − X2)(Y1 − Y2)} ], as a measure of association between X and Y. For bivariate survival data with interval sampling, to handle the selection bias from the truncation effect and the uncertainty of pair ranking from censoring, attention should be further restricted to pairs that are comparable in addition to orderable. Under quasi-independence, we adopt inverse-probability weighting to adjust for interval sampling bias, and propose a nonparametric estimate of τXY where the contribution of each comparable and orderable pair is weighted by the inverse selection probability. In fact, one can consider the comparable and orderable pairs as a sample selected from the population, and a common way to correct the bias in survey sampling is to weight each pair by the inverse of the estimated selection probability.
The challenge is to identify the comparable and orderable pairs and to compute the associated probability. The concept of a comparable pair was first introduced by Bhattacharya et al. (1983). In our setting, the pair (i, j) is comparable if , owing to the dual double truncation on B and X, where , , , and . In the presence of censoring, the order of (Yi, Yj) and the concordance or discordance status of the pair (i, j) may not be clear. Following Oakes (1982), the pair (i, j) is orderable if , where . Let λij denote the indicator of comparability and orderability. For ease of exposition, we assume that the censoring time and bivariate failure times are conditionally independent given the calendar time of the initial event and the observable region, written as C ⫫ (X, Y) ∣ (B, − B ⩽ X ⩽ t0 − B), and that the calendar time of the initial event B and the censoring time C are independent. For such a comparable and orderable pair, is observed, so the conditional probability of a pair being comparable and orderable is
Denote the distribution function of B by G(·), and denote the survival function of C by K(·). Then pij can be expressed as
which can be estimated by replacing G and K with estimators. Since the overall follow-up process is assumed to be under independent censoring, K(·),the survival function of C, can be estimated by the Kaplan–Meier estimator based on .
We now discuss estimation of G(·), the distribution function of B, which is essentially dual to estimation of the distribution function of the failure time X, because B is also doubly truncated with the constraint − X ⩽ B ⩽ t0 − X. For doubly truncated data, Shen (2010) provided an algorithm to jointly compute the nonparametric maximum likelihood estimators for the distribution functions of truncation and failure time variables. Under the assumption of quasi-independence, the full likelihood of the (Bi, Xi) can be expressed as
where g = (g1, …, gn) and f = (f1,…, fn) are probability masses assigning probability gi to Bi and fi to Xi, respectively, and for i = 1, …, n. Here L1(g) refers to the conditional likelihood of the Bi given the Xi, and L 2(g, f) is the marginal likelihood of the Xi. Interchanging the roles of the Bi and Xi, the full likelihood can also be decomposed into a product of the conditional likelihood of the Xi given the Bi and the marginal likelihood of the Bi. An iterative algorithm can be used to compute the nonparametric maximum likelihood estimators and by maximizing L1(g) and , and the corresponding nonparametric estimator of G(·) is denoted by . Although and have no explicit form and must be computed iteratively, the estimation procedure has been implemented in an R (R Development Core Team, 2014) package DTDA (Moreira et al., 2010). Alternatively, if parametric information about the distribution of B is available, we may consider a joint model of (B, X) and parameterize the distribution of B by G(·, θ). Under quasi-independence, the joint sampling density of (B, X) can be expressed as
where g(·) and fX(·) are the population densities of B and X, respectively, and pX(·) is the sampling density of X. Then the conditional likelihood function of the Bi given the Xi eliminates fX(·) by conditioning, and involves only the parameter θ:
Maximizing Lc(θ) leads to an estimator of θ, and the corresponding parametric estimator of G(·) is .
Therefore, with G(·) being either nonparametrically estimated by or parametrically estimated by , and with K(·) estimated by the Kaplan–Meier estimator , an estimator of Pij is . The unconditional Kendall’s tau is estimated by
Define an un-rescaled estimator as
The parameter τXY is defined on the domain {(x, y) : x + y ⩽ t0 − b−}, where b− = inf{b : G(b) > 0}. In the Appendix it is shown that under suitable regularity conditions, is asymptotically equivalent to a zero-mean U-statistic of order 2 as n →∞, and a similar result holds for . Consistency and asymptotic normality follow the lines of van der Vaart (1998) and are summarized in Theorem 1, whose proof is given in the Appendix.
Theorem 1. As n → ∞, is a consistent estimator of τXY, and converges weakly to a normal distribution with mean zero and variance .
While the asymptotic variance may be estimated by its empirical version, the computation is rather complicated. Since the asymptotic normality has been established, it is more convenient to use the bootstrap. The performance of the proposed estimator is evaluated in § 4.
3. Test of quasi-independence via conditional Kendall’s tau
Analysis methods for bivariate survival data with interval sampling rely on the assumption of independence between B and (X, Y). Using the Surveillance, Epidemiology and End-Results ovarian cancer data as an illustrative example, independence implies that the age of cancer diagnosis and the residual lifetime are both independent of the birth cohort. In a nonparametric model, the independence between B and (X, Y) cannot be identified due to the incompleteness of observed data. Nevertheless, quasi-independence between B and (X, Y) in the observable region −B ⩽ X ⩽ t0 − B, expressedas B ⫫ Q (X, Y), can be tested. A test is then developed for hypothesis testing based on the fact that violation of quasi-independence implies dependence. Kendall’s tau is not directly applicable to survival data subject to censoring and truncation effects, and a consistent estimate of an unconditional Kendall’s tau cannot be obtained without adjustment. As an extension, a conditional Kendall’s tau has been widely used for tests of quasi-independence for survival data under truncation (Tsai, 1990; Martin & Betensky, 2005), based on comparability of truncated data. Since both B and X are doubly truncated, we adapt this method to the context of interval sampling and define a bivariate conditional Kendall’s tau to test the association between B and (X, Y). Additionally, the second failure time Y is subject to right censoring and may not be observed exactly, so we consider the testing of quasi-independence under censoring rather than testing for independence.
We construct a test statistic from comparable and orderable paired observations. As discussed in § 2, the pair (1, 2) is comparable if , where , , , and . The pair (1, 2) is orderable if , where . To test quasi-independence between B and (X, Y) under censoring, we assume that the censoring time and bivariate failure times are conditionally independent given the calendar time of the initial event and the observable region, i.e., C ⫫ (X, Y) ∣ (B, − B ⩽ X ⩽ t0 − B), which is a weaker condition than C ⫫ (X, Y). The parameter of interest is a bivariate conditional Kendall’s tau for the association between B and (X, Y),
where (B1, X1, Y1, C1) and (B2, X2, Y2, C2) are observations from the distribution of (B, X, Y, C) ∣ (−B ⩽ X ⩽ t0 − B), Ω12 denotes the event that the pair (1, 2) is comparable in the observable region of (B, X), i.e.,
and Λ12 denotes the event that the pair (1, 2) is both comparable and orderable in the observable region of (B, Y), i.e.,
We give the proof of the following theorem in the Appendix.
Theorem 2. Under the hypothesis of quasi-independence, H0: B ⫫ Q(X, Y), and the assumption that C ⫫ (X, Y) ∣ (B, −B ⩽ X ⩽ t0 − B), the bivariate conditional Kendall’s tau satisfies .
A consistent estimator of τc based on the observed data {(Bi, Xi, , δi) : i = 1, … , n} is
where Uc = (U1, U2)T is a vector of U-statistics, Nω is the number of comparable pairs for (B, X), and NΛ is the number of comparable and orderable pairs for (B, Y). The expected values of UΩ, UΛ and Uc = (U1, U2)T are pr(Ωij) = μΩ, pr(Λij) = μΛ and . Following a theorem on the joint distribution of U-statistics, n1/2{Uc − E(Uc)} is asymptotically N(0, 4η), where the elements of the matrix η are
provided that η11 and η22 are positive as n → ∞. Similarly, is asymptotically N(0, 4D−1ηD−1) as n → ∞, where D is a diagonal matrix with [μΩ, μΛ] on the diagonal. A consistent estimator of the matrix η is obtained by averaging over all possible observations of (B, X, Y), and its exact form is given in the Appendix. Estimating η, μΩ and μΛ based on the data, the statistic is asymptotically distributed as a distribution as n → ∞, under H0 : B ⫫ Q(X, Y).
4. Simulations
The first simulation was conducted to examine the performance of the estimation method proposed in § 2 with moderate sample sizes. In measuring the association between X and Y, we compare the proposed nonparametric estimator with the copula model-based semiparametric estimator . A set of data {(B1, X1, Y1), …, (Bn, Xn, Yn)} is generated with interval sampling, where B = 9 − 13 W with W ~ Un(0, 1) and correlated pairs (X, Y) are generated from three Archimedean copula models: the Clayton (1978), Gumbel (1960) and Frank (1979) copulas. For each, we use unit exponential margins and choose three values of τXY to accommodate different levels of dependence between X and Y. An observation (Bi, Xi, Yi) is included in the dataset if and only if − Bi ⩽ Xi ⩽ −Bi + 10, and is censored if Xi + Yi ⩾ −Bi + 10. The censoring fraction is around 20–25%. For each value of τXY, 1000 simulated samples are generated with n = 400. Table 1 shows the empirical bias, standard error, average bootstrap standard error and 95% coverage probability for and , based on asymptotic normality, in which the standard error is computed using 500 bootstrap resamples. The empirical 95% coverage probability is based on the 1000 confidence intervals. Under all the simulation scenarios, the nonparametric estimator works well, with the bias of being comparable to that of . The variance of is much smaller, which demonstrates the inefficiency of the two-stage estimation procedure for . The empirical standard error of is very close to the average bootstrap standard error, and the empirical coverage probabilities of are close to 95%, which may imply that the nonparametric inference about τXY is reasonably good, and that the bootstrap estimator of the variance provides an appropriate measure of the variability of .
Table 1.
Nonparametric and semiparametric estimators of τXY for bivariate survival data with interval sampling
| τXY | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Clayton | 0·2 | 1·6 | 4·5 | 4·4 | 95·2 | 1·5 | 14·4 | 14·2 | 96·1 |
| 0·5 | 2·8 | 3·6 | 3·6 | 94·4 | 1·7 | 9·9 | 9·7 | 96·3 | |
| 0·8 | 1·8 | 1·6 | 1·7 | 95·5 | 1·2 | 4·2 | 4·0 | 96·6 | |
| Gumbel | 0·2 | 0·6 | 4·4 | 4·1 | 94·3 | 2·4 | 14·3 | 13·9 | 94·5 |
| 0·5 | 0·9 | 3·6 | 3·4 | 94·6 | −0·3 | 10·2 | 9·8 | 94·9 | |
| 0·8 | 1·1 | 1·5 | 1·3 | 94·8 | −0·8 | 4·5 | 4·1 | 95·2 | |
| Frank | 0·2 | 0·7 | 4·4 | 4·2 | 95·3 | −1·8 | 15·6 | 15·3 | 95·7 |
| −0·1 | −0·3 | 4·6 | 4·3 | 95·6 | 1·4 | 17·9 | 17·5 | 96·0 | |
| −0·2 | −1·0 | 4·6 | 4·4 | 95·4 | 2·0 | 15·7 | 15·3 | 96·3 |
, nonparametric estimator; , copula model-based semiparametric estimator; Bias, empirical bias (× 102); SEe, empirical standard error (× 102); SEb, average bootstrap standard error (× 102); CP, coverage probability.
The second simulation was carried out to evaluate the test of quasi-independence between B and (X, Y) described in § 3. The power is calculated from 500 replications. For each replication, we generate a dataset of size n = 400 under interval sampling, assuming a trivariate normal distribution of a random vector (B, X, Y) with E{(B, X, Y)} = (1, 0, 0), and vary the population correlation (ρBX, ρBY) to yield different values of the parameter of interest, . The population correlation between X and Y, ρXY, is a nuisance parameter corresponding to the parameter , which is a conditional Kendall’s tau for the association between X and Y. An observation (Bi, Xi, Yi) is included in the dataset if and only if −Bi ⩽ Xi ⩽ −Bi + 2, and is censored if Xi + Yi ⩾ −Bi + 2. Figure 1 displays contour plots of test power. For each panel, the contours are based on a linear interpolation of the estimated probability, with interpolation neighbours determined by a Delaunay triangulation of the points in the plane. The orientation of the power surface with respect to and reflects the association between X and Y. For positive ρXY, the power to detect quasi-dependence is greatest when and have opposite signs; for negative ρXY, the power to detect quasi-dependence is greatest when and have the same sign.
Fig. 1.
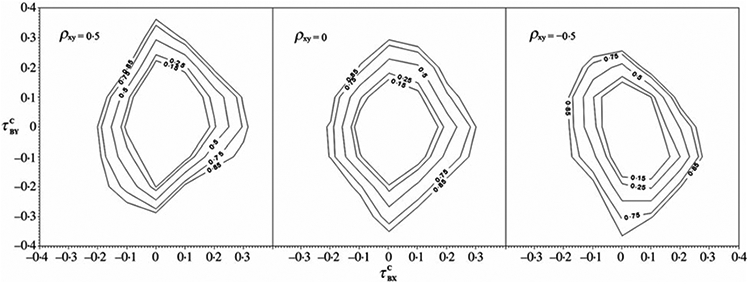
Contour plots of quasi-independence test power versus on the horizontal axis and on the vertical axis. The values of the nuisance parameter ρXY are 0·5, 0 and −0·5 from left to right. The power contours are 0·15, 0·25, 0·50, 0·75 and 0·85 from innermost to outermost.
5. Illustrative examples
The proposed nonparametric methods are applied to two sets of real data to test quasi-independence and study the relationships for bivariate survival data with interval sampling. The first dataset is from the Rakai AIDS study of HIV seroconverted subjects (Lutalo et al., 2007). The study cohort consists of 837 subjects with a documented date of HIV seroconversion between 1995 and 2003, and followed until their death or the end of 2003. Among these subjects, 120 died and others were censored by outmigration or administrative censoring at the end of 2003. Clearly, the observed data could be biased due to interval sampling. Estimation or analytical methods that do not consider this fact could yield biased results. Information on the date of birth, date of death, sex, place of residence and HIV subtype is available. In the analysis, the calendar time of birth is denoted by B, and the bivariate failure times are age at HIV infection X and residual lifetime Y; the times are measured in years. Under interval sampling, X is doubly truncated with the constraint −B ⩽ X ⩽ −B + 9, and Y is dependently right censored. Here the null hypothesis of quasi-independence corresponds to HIV progression not depending on birth time in the observable region, i.e., that B is independent of (X, Y) in the region of −B ⩽ X ⩽ −B + 9, written as B ⫫ Q(X, Y).
We first perform a test of quasi-independence for the HIV seroconversion data. The bivariate conditional Kendall’s tau for testing the association between B and (X, Y) is estimated as . The quasi-independence test statistic and the p-value of 0·340 indicate that there is insufficient evidence to reject quasi-independence between B and (X, Y), which suggests the stability of HIV infection for those diagnosed incidences occurring between 1995 and 2003. Next, given quasi-independence, we quantify the association between X and Y in terms of the unconditional Kendall’s tau, τXY, estimated by the inverse-probability weighting method. Studies suggest that progression of HIV infection is affected by HIV subtype (Kaleebu et al., 2001). Therefore, to illustrate the method, we focus on the entire cohort and three subgroups of patients with infection of A subtype, non-A subtype, and unknown subtype. A preliminary Cox regression analysis of residual lifetime conditional on age at HIV infection suggests a significant negative association, but this does not account for interval sampling bias, nor does it give an explicit measure of the association. We compute the nonparametric estimate together with the semiparametric estimate by fitting the Frank copula model. Table 2 shows a negative overall association; interestingly, there is a comparable negative association for non-A and unknown subtypes but a positive association for the A subtype, although the associations are not significant. The results suggest that the HIV epidemic is likely to have a predominance of non-A subtype infection, and subtype A appears to be a very different virus subtype from the others in terms of HIV progression, which is consistent with conclusions from other studies (Kaleebu et al., 2001).
Table 2.
Association estimations of τXY for HIV seroconversion data
| Cohort | Group size | ||||||
|---|---|---|---|---|---|---|---|
| All | 837 | −0·018 | 0·047 | (−0·110, 0·074) | −0·022 | 0·053 | (−0·126, 0·082) |
| A | 64 | 0·297 | 0·156 | (−0·011, 0·603) | 0·303 | 0·153 | (−0·063, 0·538) |
| Non-A | 349 | −0·038 | 0·057 | (−0·150, 0·074) | −0·041 | 0·071 | (−0·179, 0·101) |
| Unknown | 424 | −0·034 | 0·040 | (−0·112, 0·044) | −0·039 | 0·046 | (−0·129, 0·053) |
, nonparametric estimator; , copula model-based semiparametric estimator; SEb, bootstrap standard error; CI, 95% confidence interval.
The second dataset is from the Surveillance, Epidemiology and End-Results database. The study cohort consists of 1814 nonwhite ovarian cancer patients diagnosed between 1995 and 2002, who were followed until 2002 (Ries et al., 2005). Their dates of birth were ascertained retrospectively, and their dates of death were recorded prospectively. By the end of 2002, 1018 patients had died and the others were right censored. As women tend to have relatively short residual lifetime after diagnosis of ovarian cancer, the competing cause of death due to other risks is relatively small or ignorable. The birth time is denoted by B, and the bivariate failure times of interest are age at cancer onset X and residual lifetime Y. For the quasi-independence test, the bivariate conditional Kendall’s tau is estimated as , the test statistic is , and the p-value is 0·857, which indicates no evidence to reject quasi-independence. The association between X and Y is assessed by τXY, and a significant negative association between the age of cancer onset and residual lifetime is detected by both the nonparametric and the semiparametric methods. Specifically, with confidence interval (−0·313, −0·218) and with confidence interval (−0·434, −0·302). Our analyses show that, compared with the semiparametric estimate , the nonparametric estimate generally suggests slightly smaller negative associations. Further, the semiparametric method depends on a specific copula, the Frank model; thus it is less robust and possibly subject to model misspecification.
6. Discussion
This paper establishes nonparametric inference on bivariate survival data with interval sampling through Kendall’s tau and an extension of it. There is growing interest in assessing the relationship between bivariate failure times, but conditional Kendall’s tau can be a poor measure of dependence. Moreover, frailty models for bivariate survival data suggest that the conditional Kendall’s tau depends on the marginal distribution of each failure time, as well as the copula governing their dependence.
To quantify the dependence between bivariate failure times based on the observed data with interval sampling, we focus on an unconditional Kendall’s tau as a measure of association. Further, since the association parameters in copula models are closely related to Kendall’s tau, the copula association parameter can then be identified via tau. Potentially, the nonparametric estimate of tau may be used to develop a model selection procedure or a goodness-of-fit test of copulas, which could increase the practical utility of copula models. In addition, for bivariate failure times, we can derive estimators for the joint survival function and conditional survival function of the second failure time based on a standard copula formulation, where the copula association parameter is estimated by inverting the proposed estimator of tau. Generally, the proposed methods can be used to help understand the time course of life history processes with an initial event and first and second failure events where transitions between these events represent a progression, for which data are collected with the first event occurring within a time interval and the second event observed subject to right censoring.
Acknowledgement
We thank the editor, associate editor and referees for their constructive comments, which have substantially improved the paper. Zhu was partly supported by a Cancer Center Support Grant from the National Cancer Institute awarded to the Harold C. Simmons Cancer Center at the University of Texas Southwestern Medical Center.
Appendix
Proof of Theorem 1
First, we develop asymptotic results for . For convenience of discussion, let us write , where aij = 2I(Xi − Xj > 0) − 1 and , with and being two observed bivariate failure times. We have
| (A1) |
For comparable and orderable pairs, is observed and . The first term in (A1) is a U-statistic of order 2, and
Similarly to the discussion in Lakhal-Chaieb et al. (2010), we can show that the concordance or discordance status is conditionally independent of the comparability and orderability event. Once Xi, Xj and are fixed, by the formula for the conditional probability pij of the comparability and orderability event, described in § 2, the comparability and orderability event depends only on the initial event time B and the censoring time C. The concordance or discordance status depends only on the original pairs, so these events are conditionally independent, and
Then E{∑i<j (λijaijbij/pij − τXY)} = 0, so the first term in (A1) is a zero-mean U-statistic of order 2. By the standard theory of U-statistics, the asymptotic variance of the first term in (A1) is equal to
The variation in the second term of (A1) is due to the estimation of pij, the conditional probability that a pair is comparable and orderable. We have , where , , ,, and . To be specific, is either the nonparametric maximum likelihood estimator (·) (Shen, 2010) or the parametric estimator from the conditional likelihood, and is the Kaplan–Meier estimator. Note that and – K can be approximated by a sum of independent and identically distributed zero-mean terms. Therefore,
where E{ψ1 (Bk, Xk, b)} = 0 and E{ψ2 (Xk, , δk, s)} = 0. Then we have
where
Therefore, the second term in (A1) can be expressed as
where and , and it is a sum of independent and identically distributed zero-mean terms. Thus is asymptotically equivalent to a zero-mean U-statistic of order 2.
Next, we derive the asymptotic properties of . We have
| (A2) |
The first term in (A2) has been shown to be asymptotically equivalent to a zero-mean U-statistic of order 2. The second term in (A2) is a sum of n independent and identically distributed zero-mean terms. Similar to the derivation of asymptotic results for the second term in (A1), the third term in (A2) is also asymptotically equivalent to a sum of independent and identically distributed zero-mean terms. These three terms together imply that converges weakly to a normal distribution with mean zero and variance as n → ∞.
Proof of Theorem 2
Under (i) the null hypothesis of quasi-independence, H0 : B ⫫ Q(X, Y), and (ii) the assumption of independence between the censoring time and bivariate failure times conditional on the time of the initial event and the observable region, i.e., C ⫫ (X, Y) ∣ (B, −B ⩽ X ⩽ −B + t0), we show that . First, we consider . Notice that
| (A3) |
Given (i) H0 : B ⫫ Q(X, Y), the joint density of (X, B) in the observable region −B ⩽ X ⩽ −B + t0 can be expressed as fX(x)g*(t) for −b ⩽ x ⩽ −b + t0, where fX is the population marginal density of X and g* is proportional to the density of B ∣ (−B ⩽ X ⩽ −B + t0). Each probability in (A3) equals
where SX is the marginal survival function of X. Therefore under (i).
Next, we focus on . Suppose that (B1, X1, Y1, C1) and (B2, X2, Y2, C2) are observations from the distribution (B, X, Y, C) ∣ (−B ⩽ X ⩽ −B + t0) where pr(−B < C) = 1. Let (X,, , δi, Ti) and (Xj, , δj, Tj), where and δ = I(Y ⩽ C − X), denote two observations with interval sampling. We have
| (A4) |
Given (i) H0 : B ⫫ Q(X, Y), and (ii) C ⫫ (X, Y) ∣ (B, −B ⩽ X ⩽ −B + t0), the joint density of (B, X, Y, C) in the observable region −B ⩽ X ⩽ −B + t0 can be expressed as fXY(x, y)q (b, c) for −b ⩽ x ⩽ −b + t0, −b < c, where fXY is the population joint density of (X, Y) and q is proportional to the joint density of (B, C) ∣ (−B ⩽ X ⩽ −B + t0). Then, each probability in (A4) equals
where SXY is the joint survival function of (X, Y) and . Therefore, under (i) and (ii). In summary, we have proved that under quasi-independence and the assumption (ii).
Estimation of asymptotic variance and covariance in matrix η
The estimators of the asymptotic variance and covariance in matrix η derived in § 3 are of the form , where , , , and n is the sample size. For example, in § 3, the estimator of the covariance term η12 is obtained by using βij = sgn{(Xi − Xj)(Bi − Bj)}I(Ωij) and γij = sgn{(Yi − Yj)(Bi − Bj)}I(Λij).
Contributor Information
HONG ZHU, Division of Biostatistics, Department of Clinical Sciences, University of Texas Southwestern Medical Center, 5323 Harry Hines Blvd, Dallas, Texas 75390, U.S.A..
MEI-CHENG WANG, Department of Biostatistics, Bloomberg School of Public Health, Johns Hopkins University, 615 N. Wolfe St, Baltimore, Maryland 21205, U.S.A..
References
- Bhattacharya PK, Herman C & Yang SS (1983). Nonparametric estimation of the slope of a truncated regression. Ann. Statist 11, 505–14. [Google Scholar]
- Clayton DG (1978). A model for association in bivariate life tables and its application in epidemiological studies of familial tendency in chronic disease incidence. Biometrika 65, 141–51. [Google Scholar]
- Efron B & Petrosian V (1999). Nonparametric methods for doubly truncated data. J. Am. Statist. Assoc 94, 824–34. [Google Scholar]
- Frank MJ (1979). On the simultaneous associativity of F(x, y) and x + y − F(x, y). Aequationes Math. 19, 194–226. [Google Scholar]
- Gumbel EJ (1960). Bivariate exponential distributions. J. Am. Statist. Assoc 55, 698–707. [Google Scholar]
- Kaleebu P, Ross A, Morgan D, Yirrel D, Oram J, Rutebemberwa A, Lyagoba F, Hamilton L, Biryahwaho B & Whitworth J (2001). Relationship between HIV-1 Env subtypes A and D and disease progression in a rural Ugandan cohort. AIDS 15, 293–9. [DOI] [PubMed] [Google Scholar]
- Kendall M & Gibbons JD (1990). Rank Correlation Methods, 5th edition. London: Edward Arnold. [Google Scholar]
- Lakhal-Chaieb L Cook R & Lin X (2010). Inverse probability of censoring weighted estimates of Kendall’s τ for gap time analyses. Biometrics 66, 1145–52. [DOI] [PMC free article] [PubMed] [Google Scholar]
- Lin D-Y, Sun W & Ying Z (1999). Nonparametric estimation of gap time distributions for serial events with censored data. Biometrika 86, 59–70. [Google Scholar]
- Lutalo T, Gray RH, Wawer M, Sewankambo N, Serwadda D, Laeyendecker O, Kiwanuka N, Nalugoda F, Kigozi G, Ndyanabo A, Bwanika JB, Reynolds SJ, Ouinn T & Opendi P (2007). Survival of HIV-infected treatment-naive individuals with documented dates of seroconversion in Rakai, Uganda. AIDS 21 (Suppl. 6), S15–9. [DOI] [PubMed] [Google Scholar]
- Martin EC & Betensky RA (2005). Testing quasi-independence of failure and truncation times via conditional Kendall’s tau. J. Am. Statist. Assoc 100, 484–92. [Google Scholar]
- Moertel CG, Fleming TR, McDonald JS, Haller DG, Laurie JA, Goodman PJ, Ungerleider JS, Emerson WA, Tormey DC & Glick JH (1990). Levamisole and uorouracil for adjuvant therapy of resected colon carcinoma. New Engl. J. Med 322, 352–8. [DOI] [PubMed] [Google Scholar]
- Moreira C, de Una-Alvarez J & Crujeiras R (2010). DTDA: An R Package to analyze randomly truncated data. J. Statist. Software 37, 1–20. [Google Scholar]
- Oakes D (1982). A concordance test for independence in the presence of censoring. Biometrics 38, 451–5. [PubMed] [Google Scholar]
- R Development Core Team (2014). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria: ISBN 3–900051-07–0. http://www.R-project.org. [Google Scholar]
- Randles RH & Wolfe DA (1991). Introduction to the Theory of Nonparametric Statistics. Malabar, Florida: Krieger. [Google Scholar]
- Ries LAG Eisner MP Kosary CL Hankey BF Miller BA Clegg L Mariotto A Feuer EJ & Edwards BK (eds) (2005). SEER Cancer Statistics Review, 1975–2002. Bethesda, Maryland: National Cancer Institute. [Google Scholar]
- Shen P-S (2010). Nonparametric analysis of doubly truncated data. Ann. Inst. Statist. Math. 62, 835–53. [Google Scholar]
- Shih JH & Louis TA (1995). Inferences on the association parameters in copula models for bivariate survival data. Biometrics 51, 1384–99. [PubMed] [Google Scholar]
- Tsai W-Y (1990). Testing the assumption of independence of truncation time and failure time. Biometrika 77, 169–77. [Google Scholar]
- Tsui K-L, Jewell NP & Wu CFJ (1988). A nonparametric approach to the truncated regression problem. J. Am. Statist. Assoc 83, 785–92. [Google Scholar]
- van der Vaart AW (1998). Asymptotic Statistics. Cambridge: Cambridge University Press. [Google Scholar]
- Wang W-J & Wells MT (2000). Estimation of Kendall’s tau under censoring. Statist. Sinica 10, 1199–215. [Google Scholar]
- Zhu H & Wang M-C (2012). Analysing bivariate survival data with interval sampling and application to cancer epidemiology. Biometrika 99, 345–61. [DOI] [PMC free article] [PubMed] [Google Scholar]