

Abstract
Many high-dimensional hypothesis tests aim to globally examine marginal or low-dimensional features of a high-dimensional joint distribution, such as testing of mean vectors, covariance matrices and regression coefficients. This paper constructs a family of U-statistics as unbiased estimators of the ℓp-norms of those features. We show that under the null hypothesis, the U-statistics of different finite orders are asymptotically independent and normally distributed. Moreover, they are also asymptotically independent with the maximum-type test statistic, whose limiting distribution is an extreme value distribution. Based on the asymptotic independence property, we propose an adaptive testing procedure which combines p-values computed from the U-statistics of different orders. We further establish power analysis results and show that the proposed adaptive procedure maintains high power against various alternatives.
Keywords: High-dimensional hypothesis test, U-statistics, adaptive testing
MSC2020 subject classifications: 62F03, 62F05
1. Introduction.
Motivation.
Analysis of high-dimensional data, whose dimension p could be much larger than the sample size n, has emerged as an important and active research area (e.g., [19, 21, 23, 63]). In many large-scale inference problems, one is often interested in globally testing some overall patterns of low-dimensional features of the high-dimensional random observations. One example is genome-wide association studies (GWAS), whose primary goal is to identify single nucleotide polymorphisms (SNPs) associated with certain complex diseases of interest. A popular approach in GWAS is to perform univariate tests, which examine each SNP one by one. This, however, may lead to low statistical power due to the weak effect size of each SNP [47] and the small statistical significance threshold (~ 10−8) chosen to control the multiple-comparison type I error [40]. Researchers therefore have proposed to globally test a genetic marker set with many SNPs [40, 64] in order to achieve higher statistical power and to better understand the underlying genetic mechanisms.
In this paper, we focus on a family of global testing problems in the high-dimensional setting, including testing of mean vectors, covariance matrices and regression coefficients in generalized linear models. These problems can be formulated as , where 0 is an all zero vector, is a parameter vector with being the index set, and el’s being the corresponding parameters of interest, for example, elements in mean vectors, covariance matrices or coefficients in generalized linear models. For the global testing problem versus , two different types of methods are often used in the literature. One is sum-of-squares-type statistics. They are usually powerful against “dense” alternatives, where has a high proportion of nonzero elements with a large or its weighted variants. See examples in mean testing (e.g., [4, 11, 12, 25, 26, 60, 62]) and covariance testing (e.g., [3, 13, 42, 45]). The other is maximum-type statistics. They are usually powerful against “sparse” alternatives, where has few nonzero elements with a large (e.g., [6, 8, 9, 27, 36, 46, 58]). More recently, [20, 70] also proposed to combine these two kinds of test statistics. However, for denser or only moderately dense alternatives, neither of these two types of statistics may be powerful, as will be further illustrated in this paper both theoretically and numerically. Importantly, in real applications, the underlying truth is usually unknown, which could be either sparse, dense or in-between. As global testing could be highly underpowered if an inappropriate testing method is used (e.g., [15]), it is desired in practice to have a testing procedure with high statistical power against a variety of alternatives.
A family of asymptotically independent U-statistics.
To address these issues, we propose a U-statistics framework and introduce its applications to adaptive high-dimensional testing. The U-statistics framework constructs unbiased and asymptotically independent estimators of for different (positive) integers a, where a = 2 corresponds to a sum-of-squares-type statistic, and an even integer a → ∞ yields a maximum-type statistic. The adaptive testing then combines the information from different ’s, and our power analysis shows that it is powerful against a wide range of alternatives, from highly sparse, moderately sparse to dense, to highly dense.
To illustrate our idea, suppose z1, … , zn are n independent and identically distributed (i.i.d.) copies of a random vector z. We consider the setting where each parameter el has an unbiased kernel function estimator Kl(zi1, … , ziγl), and γl is the smallest integer such that for any 1 ≤ i1 ≠ ⋯ ≠ iγl ≤ n, E[Kl(zi1, … , ziγl)] = el. This includes many testing problems on moments of low orders, such as entries in mean vectors, covariance matrices and score vectors of generalized linear models, which shall be discussed in detail. The family of U-statistics can be constructed generally as follows. For integers a ≥ 1 and 1 ≤ i1 ≠ ⋯ ≠ iγl ≠ ⋯ ≠ i(a−1)×γl+1 ⋯ ≠ ia×γl ≤ n, since the z’s are i.i.d., we have . Therefore, we can construct an unbiased estimator of the parameters of augmented powers with different a. Then has an unbiased estimator
| (1.1) |
where denotes the number of k-permutations of n. We call a the order of the U-statistic . If a > b, we say is of higher order than and vice versa.
This construction procedure can be applied to many testing problems. We give three common examples below for illustration and more detailed case studies will be discussed in Sections 2 and 4.
Example 1. Consider one-sample mean testing of H0 : μ = 0, where is the mean vector of a p-dimensional random vector x. Suppose x1, … , xn are n i.i.d. copies of x. For each i = 1, … , n, j = 1, … , p, xi,j is a simple unbiased estimator of μj, then we can take the kernel function Kj(xi) = xi,j. Following (1.1), we know the U-statistic
is an unbiased estimator of . Please see Section 4.1 for the two-sample mean testing example and related theoretical properties.
Example 2. Suppose x1, … , xn are n i.i.d. copies of a random vector x with mean vector μ = 0 and covariance matrix Σ = {σj1,j2}p×p. For covariance testing H0 : σj1,j2} = 0 for any 1 ≤ j1 ≠ j2 ≤ p, we have with . Since xi,j1xi,j2 is a simple unbiased estimator of σj1,j2, then for each pair , we can take the kernel function Kl(xi) = xi,j1xi,j2. Following (1.1), the U-statistic
is an unbiased estimator of . Please see Section 2 for one-sample covariance testing with unknown μ, and Section 4.2 for two-sample covariance testing.
Example 3. Consider a response variable y and its covariates following a generalized linear model: E(y∣x) = g−1(x⊤β), where g is the canonical link function and are the regression coefficients. Suppose that (xi, yi), i = 1, … , n, are i.i.d. copies of (x, y). For testing H0 : β = β0, the score vectors (Si,j = (yi − μ0,i)xi,j : j = 1, … , p)⊤ are often used in the literature, where . Note that E(Si,j) = 0 under H0. Thus to test H0, we can take and use the U-statistic
which is an unbiased estimator of . Please see Section 4.3.
Related literature.
For high-dimensional testing, some other adaptive testing procedures have recently been proposed in [52, 65, 67]. These works combine the p-values of a family of sum-of-powered statistics that are powerful against different ’s. However, in these existing works, to evaluate the p-value of the adaptive test statistic, the joint asymptotic distribution of the statistics is difficult to obtain or calculate. Accordingly, computationally expensive resampling methods are often used in practice [40, 52, 69]. For some special cases such as testing means and the coefficients of generalized linear models, [67] and [65] derived the limiting distributions of the test statistics under the framework of a family of von Mises V-statistics. However, the constructed V-statistics are usually correlated and biased estimators of the target . It follows that in [67] and [65], numerical approximations are still needed to calculate the tail probabilities of the adaptive test statistics; see Remark 4.1 and Section 4.3. In addition, these existing adaptive testing works mainly focus on the first-order moments, and their results do not directly apply to testing second-order moments, such as covariance matrices.
To overcome these issues, this paper considers the proposed family of unbiased U-statistics. There are some other recent works providing important results on high-dimensional U-statistics (e.g., [14, 43, 72]). For instance, [72] considered testing the regression coefficients in linear models using the fourth-order U-statistic; [43] studied the limiting distributions of rank-based U-statistics; and [14] studied bootstrap approximation of the second-order U-statistics. However, these results do not directly apply to the high-order U-statistics considered in this paper.
Our contributions.
We establish the theoretical properties of the U-statistics in various high dimensional testing problems, including testing mean vectors, regression coefficients of generalized linear models, and covariance matrices. Our contributions are summarized as follows.
Under the null hypothesis, we show that the normalized U-statistics of different finite orders are jointly normally distributed. The result applies generally for any asymptotic regime with n → ∞ and p → ∞. In addition, we prove that all the finite-order U-statistics are asymptotically independent with each other under the null hypothesis. Moreover, we prove that U-statistics of finite orders are also asymptotically independent of the maximum-type test statistic with a limiting extreme value distribution.
Under the alternative hypothesis, we further analyze the asymptotic power for U-statistics of different orders. We show that when has denser nonzero entries, ’s of lower orders tend to be more powerful; and when has sparser nonzero entries, ’s of higher orders tend to be more powerful. More interestingly, we show that in the boundary case of “moderate” sparsity levels, with a finite a > 2 gives the highest power among the family of U-statistics, clearly indicating the inadequacy of both the sum-of-squares- and the maximum-type statistics.
An important application of the independence property among ’s is to construct adaptive testing procedures by combining the information of different ’s, whose univariate distributions or p-values can be easily combined to form a joint distribution to calculate the p-value of an adaptive test statistic. Compared with other existing works (e.g., [65, 67]), numerical approximations of tail probabilities are no longer needed. As shown in the power analysis, an adaptive integration of information across different tests leads to a powerful testing procedure.
The rest of the paper is organized as follows. In Sections 2 and 3, we illustrate the framework by a covariance testing problem. Particularly, in Section 2.1, we study the U-statistics under null hypothesis; in Section 2.2, we analyze the power of the U-statistics; in Section 2.3, we develop an adaptive testing procedure. In Sections 3.1 and 3.2, we report simulations and a real dataset analysis. In Section 4, we study other high-dimensional testing problems, including testing means, regression coefficients, and two-sample covariances. In Section 5, we discuss several extensions of the proposed framework. We give proofs and other stimulations in Supplementary Material [28].
2. Motivating example: One-sample covariance testing.
The constructed family of U-statistics and adaptive testing procedure can be applied to various high-dimensional testing problems. In this section, we illustrate the framework with a motivating example of one-sample covariance testing. Analogous results for other high-dimensional testing problems in Section 4 can be obtained following similar analyses. We showcase the study of one-sample covariance testing problem since this is more challenging than mean testing due to the two-way dependency structure and the one-sample problem can be used as the building block for more general cases.
Specifically, we focus on testing
| (2.1) |
where Σ = {σj1,j2 : 1 ≤ j1, j2 ≤ p} is the covariance matrix of a p-dimensional real-valued random vector x = (x1, … , xp)⊤ with E(x) = μ = (μ1, … , μp)⊤. The observed data include n i.i.d. copies of x, denoted by x1, … , xn with xi = (xi,1, … , xi,p)⊤. In factor analysis, testing H0 in (2.1) can be used to examine whether Σ has any significant factor or not [1].
Global testing of covariance structure plays an important role in many statistical analysis and applications; see a review in [7]. Conventional tests include the likelihood ratio test, John’s test and Nagao’s test, etc. [1, 50]. These methods, however, often fail in the high-dimensional setting when both n, p → ∞. To address this issue, new procedures have been recently proposed (e.g., [3, 8, 13, 36-38, 41, 42, 45, 46, 53, 57-59]). However, these methods might suffer from loss of power when the sparsity level of the alternative covariance matrix varies. In the following subsections, we introduce the general U-statistics framework, study their asymptotic properties and develop a powerful adaptive testing procedure.
We introduce some notation. For two series of numbers un,p, vn,p that depend on n, p: un,p = o(vn,p) denotes denotes ; un,p = Θ(vn,p) denotes ; un,p ≃ vn,p denotes . Moreover, and represent the convergence in probability and distribution, respectively. For p-dimensional random vector x with mean μ and ∀j1, … , jt ∈ {1, … , p}, we write the central moment as
| (2.2) |
2.1. Asymptotically independent U-statistics.
For testing (2.1), the set of parameters that we are interested in is . Following the previous analysis of (1.1), since σj1,j2 has a simple unbiased estimator xi1,j1xi1,j2 − xi1,j1xi2,j2 with 1 ≤ i1 ≠ i2 ≤ n, then for integers a ≥ 1, an unbiased U-statistic of is
This is equivalent to
| (2.3) |
Remark 2.1. The U-statistics can be constructed by another method equivalently. Given 1 ≤ j1 ≠ j2 ≤ p, define φj1,j2 = σj1,j2 + μj1μj2. Then
| (2.4) |
which is a polynomial function of the moments μj and φj1,j2. Since μj and φj1,j2 have unbiased estimators xi,j and xi,j1xi,j2 respectively, then for 1 ≤ i1 ≠ ⋯ ≠ ia+c ≤ n, . Given this and (2.4), the U-statistics (2.3) can be obtained.
Remark 2.2. The summed term with c = 0 in (2.3) is
| (2.5) |
which has the same form as the simplified U-statistic for mean zero observations in Example 2, and is shown to be the leading term of (2.3) in proof.
We next introduce some nice properties of the U-statistics (2.3). The first one is the following location invariant property.
Proposition 2.1. constructed as in (2.3) is location invariant; that is, for any vector , the U-statistic constructed based on the transformed data {xi + Δ : i = 1, … , n} is still .
The following proposition verifies that the constructed U-statistics are unbiased estimators of .
Proposition 2.2. For any integer a, . Under H0 in (2.1), .
We next study the limiting properties of the constructed U-statistics under H0 given the following assumptions on the random vector x = (x1, … , xp)⊤.
Condition 2.1 (Moment assumption). and .
Condition 2.2 (Dependence assumption). For a sequence of random variables z = {zj : j ≥ 1} and integers a < b, let be the σ-algebra generated by {zj : j ∈ {a, … , b}}. For each s ≥ 1, define the α-mixing coefficient . We assume that under H0, x is α-mixing with αx(s) ≤ Mδs, where δ ∈ (0, 1) and M > 0 are some constants.
Condition 2.2* (Alternative dependence assumption to Condition 2.2). Following the notation in (2.2), we assume that under H0, for any j1, j2, j3 ∈ {1, … , p}, Πj1,j2,j3 = 0; for any j1, j2, j3, j4 ∈ {1, … , p}, Πj1,j2,j3,j4 = κ1(σj1,j2σj3,j4 + σj1,j3σj2,j4 + σj1,j4σj2,j3) for some constant κ1 < ∞; and for t = 6, 8, and any j1, … , jt ∈ {1, …, p}, Πj1,…,jt = 0 when at least one of these indexes appears odd times in {j1, …, jt}.
Condition 2.1 assumes that the eighth marginal moments of x are uniformly bounded from above and the second moments are uniformly bounded from below, which are true for most light-tailed distributions. Condition 2.2 assumes weak dependence among different xj’s under H0, since the uncorrelatedness of xj’s under H0 may not imply the independence of them, especially when xj’s are non-Gaussian. Under H0, Condition 2.2 automatically holds when x is Gaussian or m-dependent. The mixing-type weak dependence is similarly considered in previous works such as [5, 11, 67] and also commonly assumed in time series and spatial statistics [24, 55]. Moreover, the variables in our motivating genome-wide association studies have a local dependence structure, with their associations often decreasing to zero as the corresponding physical distances on a chromosome increase. We note that it suffices to have Condition 2.2 hold up to a permutation of the variables.
Alternatively, we can substitute Condition 2.2 with Condition 2.2*. Condition 2.2* specifies some higher-order moments of x and is satisfied when x follows an elliptical distribution with finite eighth moments and covariance Σ (see [1, 22, 50, 51]). Conditions 2.2* and 2.2 become equivalent when x follows a multivariate Gaussian distribution. The fourth moment condition is also assumed in other high-dimensional research [6]. In this work, the eighth moment condition is needed to establish the asymptotic joint distribution of different U-statistics.
The following theorem specifies the asymptotic variances of the finite order U-statistics and their joint limiting distribution. Since the U-statistics are degenerate under H0, an analysis different from the asymptotic theory on nondegenerate U-statistics (e.g., [32]) is needed in the proof.
Theorem 2.1. Under H0 in (2.1) and Conditions 2.1 and 2.2 (or 2.2*), for ’s defined in (2.3) and any distinct finite (and positive) integers {a1, … , am}, as n, p → ∞,
| (2.6) |
where
| (2.7) |
with Πj1,j2,j3,j4 defined in (2.2). Note that σ2(a) = Θ(p2n−a).
Theorem 2.1 shows that after normalization, the finite-order U-statistics have a joint normal limiting distribution with an identity covariance matrix, which implies that they are asymptotically independent as n, p → ∞. The nice independence property makes it easy to combine these U-statistics and apply our proposed adaptive testing later. Moreover, the conclusion holds on general asymptotic regime for n, p → ∞, without any constraint on the relationship between n and p. We will also see in Section 4 that similar results hold generally for some other testing problems.
Remark 2.3. Theorem 2.1 discusses the U-statistics of finite orders, that is, the a values do not grow with n, p. When {x1, … , xp} are independent, Theorem 2.1 can be extended when a = O(1) min{logϵ n, logϵ p} for some ϵ > 0. On the other hand, we will show in Section 2.2 that it is usually enough to include ’s of finite a. Therefore, we do not pursue the general case when a grows with n, p in this work.
In the following, we further discuss the maximum-type test statistic , which corresponds to the ℓ∞-norm of the parameter vector , that is, . In the existing literature, there is already some corresponding established work [8, 36] on the test statistic:
| (2.8) |
where and . We will take below. The limiting distribution of was first studied in [36] and extended by [8, 46, 58]. Next, we restate the result in [8], which gives the limiting distribution of (2.8) under the following condition.
Condition 2.3. Consider the random vector x = (x1, … , xp)⊤ with mean vector μ = (μ1, … , μp)⊤ and covariance matrix Σ = dia(σ1,1,… , σp,p). are i.i.d. for j = 1, … , p. Furthermore, for some 0 < ς ≤ 2 and t0 > 0.
Theorem 2.2 (Cai and Jiang [8], Theorem 2). Assume Condition 2.3 and log p = o(nβ), where β = ς/(4 + ς). Then , where and G(u) is an extreme value distribution of type I.
Theorems 2.1 and 2.2 give the limiting distributions of of finite orders and respectively; it is of interest to examine their joint distribution. The following theorem shows that although has limiting distribution different from , a < ∞, they are still asymptotically independent.
Theorem 2.3. Assume that Condition 2.1 is satisfied, Condition 2.3 holds for ς = 2, and log p = o(n1/7). For finite integers {a1, … , am}, under H0, and are mutually asymptotically independent. Specifically, ∀z1, … , zm, , as n, p → ∞,
Theorem 2.1 suggests that all the finite-order U-statistics are asymptotically independent with each other. Given this, Theorem 2.3 further shows that the maximum-type test statistic is also asymptotically mutually independent with those finite-order U-statistics. The conclusion shares similarity with some classical results on the asymptotic independence between the sum-of-squares-type and maximum-type statistics. Specifically, for random variables w1,… , wn, [30, 33] proved the asymptotic independence between and maxi=1,…,n ∣wi∣ for weakly dependent observations. The similar independence properties were extensively studied in literature (e.g., [31, 34, 44, 48, 54, 67]). However, there are several differences between existing literature and the results in this paper. First, we discuss a family of U-statistics ’s, which takes different a values, and here corresponding to the sum-of-squares-type statistic is only a special case of general . Furthermore, we have shown not only the asymptotic independence between and , but also the asymptotic independence among ’s of finite a values. Second, the constructed ’s are unbiased estimators, which are different from the sum-of-squares statistics usually examined in the literature. Moreover, the x’s are allowed to be dependent and the theoretical development in the covariance testing involves a two-way dependence structure, which requires different proof techniques from the existing studies.
Remark 2.4. An alternative way to construct is to standardize by its variance . Specifically, following Cai et al. [6], we take . Define and we take . Theoretically, we prove that Theorem 2.3 still holds with in Supplementary Material [28], Section B.11. Numerically, we provide the simulations in Supplementary Material [28], Section C.2, which shows that in (2.8) generally has higher power than .
To apply hypothesis testing using the asymptotic results in Theorems 2.1 and 2.3, we need to estimate . In particular, we propose the following moment estimator of (2.7):
| (2.9) |
The next result establishes the statistical consistency of .
Condition 2.4. For integer a, .
Theorem 2.4. Under H0 in (2.1), assume Conditions 2.1, 2.2 and 2.4 hold. Then .
Theorem 2.4 implies that the asymptotic results in Theorems 2.1 and 2.3 still hold by replacing with its estimator . Specifically, under under Conditions 2.1, 2.2 and 2.4. Moreover, Theorem 2.3 implies that ’s are asymptotically independent with .
2.2. Power analysis.
In this section, we analyze the asymptotic power of the U-statistics. The power of has been studied in the literature. In particular, [10] studied the hypothesis testing of a high-dimensional covariance matrix with H0 : Σ = Ip. The authors characterized the boundary that distinguishes the testable region from the nontestable region in terms of the Frobenius norm ∥Σ − Ip∥F, and showed that the test statistic proposed by [10, 13], which corresponds to in this paper, is rate optimal over their considered regime. However in practice, may be not powerful if the alternative covariance matrix is sparse with a small ∥Σ − Ip∥F. When the alternative covariance has different sparsity levels, it is of interest to further examine which achieves the best power performance among the constructed family of U-statistics.
To study the test power, we establish the limiting distributions of ’s under the alternative hypothesis HA : Σ = ΣA, where the alternative covariance matrix ΣA = (σj1,j2)p×p is specified in the following Condition 2.5. Define JA = {(j1, j2) : σj1,j2 ≠ 0, 1 ≤ j1 ≠ j2 ≤ p}, which indicates the nonzero off-diagonal entries in ΣA. The cardinality of JA, denoted by ∣JA∣, then represents the sparsity level of ΣA.
Condition 2.5. Assume ∣JA∣ = o(p2) and for (j1, j2) ∈ JA, ∣σj1,j2∣ = Θ(ρ), where ρ = Σ(j1,j2)∈JA∣σj1,j2∣/∣JA∣.
Here ρ represents the average signal strength of ΣA. In our following power comparison of two U-statistics and , we say is “better” than , if, under the same test power, can detect a smaller average signal strength ρ (please see the specific definition in Criterion 1 on page 163). Condition 2.5 specifies a general family of “local” alternatives, which include banded covariance matrices, block covariance matrices and sparse covariance matrices whose nonzero entries are randomly located.
Theorem 2.5. Suppose Conditions 2.1, 2.5 and A.1 (an analogous condition to Condition 2.2* under HA) in Supplementary Material [28] hold. For in (2.3) and finite integers {a1, … , am}, if ρ = O(∣JA∣−1/atp1/atn−1/2) for t = 1, … , m, then as n, p → ∞,
where for a ∈ {a1, … , am}, and , which is of order Θ(p2n−a).
Theorem 2.5 shows that for a single U-statistic of finite order a,
| (2.10) |
where z1−α is the upper α quantile of and Φ(·) is the cumulative distribution function of . By Theorem 2.5, the asymptotic power of of the one-sided test depends on
| (2.11) |
where (2.11) = Θ(∣JA∣ρap−1na/2). It follows that when is of the same order of , that is, , the constraint of ρ in Theorem 2.5 is satisfied.
In the following power analysis, we will first compare ’s of finite a and then compare them with . As we focus on studying the relationship between the sparsity level and power, we consider an ideal case where σj1,j2 = ρ > 0 for (j1, j2) ∈ JA and σj, j = v2 > 0 for j = 1, … , p. Then
| (2.12) |
We next show how the order of the “best” U-statistics changes when the sparsity level ∣JA∣ varies. To be specific of the meaning of “best,” we compare the ρ values needed by different U-statistics to achieve the same asymptotic power. Particularly, we fix , that is, (2.12) to be some constant for different a’s and the asymptotic power of each is (2.10) = . Then by (2.12), the ρ value such that attains the power above is
| (2.13) |
By the definition in (2.13), we compare the power of two U-statistics and with a ≠ b following the Criterion 1 below:
Criterion 1. We say is “better” than if ρa < ρb.
Given values of n, p, ∣JA∣ and M, (2.13) is a function of a. Therefore, to find the “best” , it suffices to find the order, denoted by a0, that gives the smallest ρa value in (2.13). We then have the following proposition discussing the optimality among the U-statistics of finite orders in (2.3).
Proposition 2.3. Given n, p, ∣JA∣ and any constant M ∈ (0, +∞), we consider ρa in (2.13) as a function of integer a, then:
(i) when ∣JA∣ ≥ Mp, the minimum of ρa is achieved at a0 = 1;
(ii) when ∣JA∣ < Mp, the minimum of ρa is achieved at some a0, which increases as Mp/∣JA∣ increases.
By Proposition 2.3, the order a0 that attains the smallest value of ρa depends on the value of Mp/∣JA∣ and does not have a closed-form solution. We use numerical plots to demonstrate the relationship between a0 and the sparsity level. Particularly, let ∣JA∣= p2(1–β), where β ∈ (0, 1) denotes the sparsity level. To have a better visualization, we use instead of ρa. We plot g(a) curves in Figure 1 for each β ∈ {0.1,…, 0.9} with M = 4 and p ∈ {100, 10000}. Other values of M and p are also taken, which give similar patterns to Figure 1 and are not presented.
Fig. 1.

g(a) versus a with different sparsity level β for p = 100, 10000.
Figure 1 shows that the a0 such that g(a) attains the smallest value increases when the sparsity level β increases. In particular, when the sparsity level β ≤ 0.3, that is, when ∣JA∣ is “very” large and then ΣA is “very” dense, g(a) has the smallest value at a0 = 1. This is consistent with the conclusion in Proposition 2.3 (i). When the sparsity level β is between 0.4 and 0.5, we note that a0 = 2 achieves the minimum of g(a). This shows that when ∣JA∣ is “moderately” large and ΣA is “moderately” dense, is more powerful than . When the sparsity level β > 0.5, we find that a0 > 2. This implies that when ∣JA∣ becomes smaller and ΣA becomes sparser, U-statistics of higher orders are more powerful. Additionally, we note that a0 increases slowly as β increases, which verifies Proposition 2.3(ii). Moreover, the curves converge as a increases and the differences of g(a) for large a values (a ≥ 6) are small. This implies that when selecting the range of considered orders of U-statistics, it suffices to select an upper bound with a = 6 or 8, which gives better or similar ρa values to those larger a’s.
In summary, when ∣JA∣ is large, that is, ΣA is dense, a small a tends to obtain a smaller lower bound in terms of ρ. But when ∣JA∣ decreases, that is, ΣA becomes sparse, a U-statistic of large finite order (or the maximum-type U-statistic as shown next) tends to obtain a smaller lower bound in ρ. This observation is consistent with the existing literature [7, 8, 10, 13].
Next, we proceed to examine the power of the maximum-type test statistic , and compare it with the U-statistics of finite a defined in (2.3). By [8], the rejection region for with significance level α is
Note and under alternative, the power for is
| (2.14) |
As discussed, we consider the alternatives satisfying Conditions 2.2* and 2.5, σj1, j2 = ρ > 0 for (j1, j2) ∈ JA, and σj, j = ν2 for j = 1,…,p. For simplicity, we assume E(x) = μ and ν2 are given, and focus on the simplified
| (2.15) |
We show in the following proposition when the power of asymptotically converges to 1 or is strictly smaller than 1 under alternative.
Proposition 2.4. Under the considered alternative ΣA above, suppose maxj=1,…,p Eet0∣xj–μj∣ς < ∞ for some 0 < ς ≤ 2 and t0 > 0, and log p = o(nβ) with β = ς/(4 + ς). Then for (2.15), when n, p → ∞:
(i) there exists a constant c1 > 2 such that if , (2.14) → 1;
(ii) there exists another constant 0 < c2 < 2 such that when , Condition 2.2* holds for κ1 ≤ 1 and for some m > 0, we have (2.14) ≤ log(1 – α)−1.
Recall that Proposition 2.3 shows that there exists a finite integer a0, such that ρa0 is the minimum of (2.13), and ρa0 is a lower bound of ρ value for the finite-order U-statistics to achieve the given asymptotic power. With Propositions 2.3 and 2.4, we next compare the finite-order U-statistics defined in (2.3) with the maximum-type test statistic .
Proposition 2.5. Under the conditions of Theorem 2.5 and Proposition 2.4, for any finite integer a, there exist constants c1 and c2 such that when p is sufficiently large:
(i) For any M, when , has higher asymptotic power than .
(ii) When M is big enough and , has higher asymptotic power than .
From Proposition 2.3, we know when Mp/∣JA∣ = O(1), there exists a finite a0 such that is the “best” among all the finite-order U-statistics; in this case, Proposition 2.5(ii) further indicates that has higher asymptotic power than . Specifically, if Mp/∣JA∣ < 1, a0 = 1, then is the “best” and its lowest detectable order of ρ is Θ(p∣JA∣−1n−1/2). More interestingly, when ΣA is moderately dense or moderately sparse with Mp/∣JA∣ > 1 and bounded, some U-statistic of finite order a0 > 1 would become the “best.” By Figure 1, the value of a0 increases as ΣA becomes denser. On the other hand, when ΣA is “very” sparse with , is the “best” and its lowest detectable order of ρ is .
Remark 2.5. The above power comparison results are under the constructed family of U-statistics. We note that additional formulation may further enhance the test power. For instance, [11, 73] showed that an adaptive thresholding in certain ℓp-type test statistics can achieve high power under the alternatives with sparse and faint signals. It is of interest to incorporate the adaptive thresholding into the constructed family of U-statistics, which is left for future study.
Remark 2.6. The analysis above focuses on the ideal case where the nonzero off-diagonal entries of ΣA are the same for illustration. When these entries of ΣA are different, similar analysis still applies by Theorem 2.5 for general covariance matrices. In particular, the asymptotic power of depends on the mean variance ratio (2.11) and . We can then obtain conclusions similar to Propositions 2.3-2.5. One interesting case is when ΣA contains both positive and negative entries; the same analysis applies for even-order U-statistics, since ’s are all nonnegative for even a. On the other hand, the odd-order U-statistics would have low power, since ’s could be small due to the cancellation of positive and negative . We have conducted simulations when the nonzero σj1,j2’s are different in Section 3.1, and the results exhibit consistent patterns as expected.
2.3. Application to adaptive testing and computation.
Adaptive testing.
Power analysis in Section 2.2 shows that when the sparsity level of the alternative changes, the test statistic that achieves the highest power could vary. However, since the truth is often unknown in practice, it is unclear which test statistic should be chosen. Therefore, we develop an adaptive testing procedure by combining the information from U-statistics of different orders, which would yield high power against various alternatives.
In particular, we propose to combine the U-statistics through their p-values, which is widely used in literature [49, 52, 71]. One popular method is the minimum combination, whose idea is to take the minimum p-value to approximate the maximum power [52, 67, 71]. Specifically, let Γ be a candidate set of the orders of U-statistics, which contains both finite values and TO. We compute p-values pa’s of the U-statistics ’s satisfying a ∈ Γ. The minimum combination takes the statistic TadpUmin = min{pa : a ∈ Γ} and has the asymptotic p-value padpUmin = 1 – (1 – TadpUmin)∣Γ∣, where ∣Γ∣ denotes the size of the candidate set Γ. We reject H0 if padpUmin < α. Under H0, pa’s are asymptotically independent and uniformly distributed by the theoretical results in Section 2.1. The type I error is asymptotically controlled as , where . Since , the power of the adaptive test goes to 1 if there exists a ∈ Γ such that the power of goes to 1. We note that the power of the adaptive test is not necessarily higher than that of all the U-statistics. This is because the power of is P(pa < α), and is different from since when ∣Γ∣ > 1. Based on our extensive simulations, we find that the adaptive test is usually close to or even higher than the maximum power of the U-statistics.
Remark 2.7. Fisher’s method [49] is another popular method for combining independent p-values. It has the test statistic , which converges to under H0. By our simulations, the minimum combination and Fisher’s method are generally comparable, while Fisher’s method has higher power under several cases. Moreover, we can also use other methods to combine the p-values, such as higher criticism [16, 17]. We leave the study of how to efficiently combine the p-values for future research.
We select the candidate set Γ by the power analysis in Section 2.2. We would recommend including {1, 2,…, 6, ∞}, which can be powerful against a wide spectrum of alternatives. In particular, by Propositions 2.3 and 2.5, we include a = 1, 2 that are powerful against dense signals; a = ∞ that is powerful against sparse signals; and also a = {3,…, 6} for the moderately dense and moderately sparse signals. By Figure 1, it generally suffices to choose finite a up to 6–8, which often give similar/better performance to/than larger a values. The simulations in Section 3.1 confirm the good performance of this choice of Γ; and the proposed adaptive test appears to well approximate the “best” performance even when Γ may not always contain the unknown “optimal” U-statistics.
We would like to mention that the adaptive procedure can be generalized to other testing problems, as long as similar theoretical properties are given, such as the examples in Section 4.
Computation.
Next, we discuss the computation in the adaptive testing. A direct calculation following the form of in (2.3) and in (2.9) would be computationally expensive for large a with a cost of O(p2n2a). To address this issue, we introduce a method that can reduce the cost.
We first consider a simplified setting when E(xi,j) = 0 to illustrate the idea. As discussed in Remark 2.2, we examine defined in (2.5). Let denote the set of index tuples, and for each index tuple , define si,l = xi,j1 xi,j2. Note that , where . Calculating directly is of order O(na). We then focus on reducing the computational cost of . For and finite integers t1,…,tk, define
| (2.16) |
We can see that with 1a being an a-dimensional vector of all ones, and for any finite integer a. To reduce the computational cost of , the main idea is to obtain from , whose computational cost is O(n). In particular, can be attained iteratively from based on the following equation:
| (2.17) |
which follows from the definitions. Algorithm 1 below summarizes the steps.
Algorithm 1:
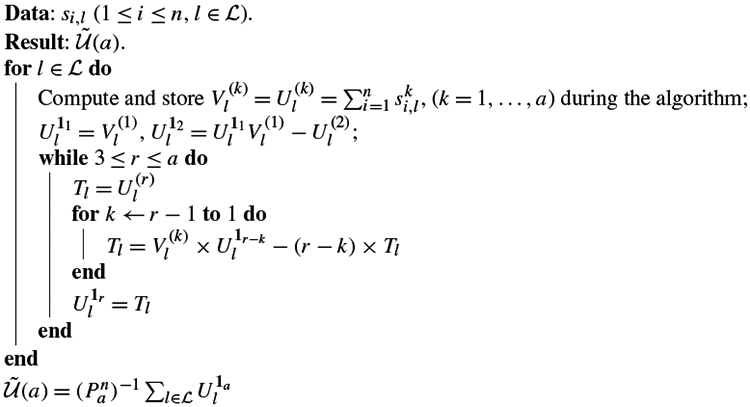
Iterative computation implementation
We illustrate the idea of the algorithm by some examples. By definition, , which can be computed with cost O(n). Next, consider in (2.17), if r = 2 and k = 1, then , which yields with cost O(n). For , we first take r = 3 and k = 2 in (2.17), then with cost O(n), we have , as by the definition. Given and , we obtain . Thus is also computed with cost O(n). Iteratively, for any finite integer a, we can obtain from whose computational cost is O(n). More closed-form formulae representing by are given in Section C.1.1 of Supplementary Material [28].
Algorithm 1 reduces the computational cost of from O(p2na) to O(p2n). Its idea is general and can be extended to compute other different U-statistics by changing the input si,l. In particular, the variance estimator can be computed with cost O(p2n) by specifying , for each . Then and Algorithm 1 can be applied. Moreover, when E(xi,j) is unknown, can still be computed with cost O(p2n) using the iterative method similar to Algorithm 1. The details are provided in Section C.1.2 of Supplementary Material [28].
3. Simulations and real data analysis.
3.1. Simulations.
We conduct simulation studies to evaluate the performance of the proposed adaptive testing procedures, and investigate the relationship between the power and sparsity levels. For one-sample covariance testing discussed in Section 2, we generate n i.i.d. p-dimensional xi for i = 1,…,n, and consider the following five simulation settings.
Setting 1: xi has p i.i.d. entries of and Gamma(2, 0.5), respectively. Under each case, we take n = 100 and p ∈ {50, 100, 200,400, 600, 800, 1000} to verify the theoretical results under H0 and the validity of the adaptive test across different n and p combinations.
For the following settings 2–5, we generate xi from multivariate Gaussian distributions with mean zero and different covariance matrices ΣA’s.
Setting 2: , where 1p,k0 is a p-dimensional vector with the first k0 elements one and the rest zero. We take (n, p) ∈ {(100, 300), (100, 600), (100, 1000)}, and study the power with respect to different signal sizes ρ and sparsity levels k0.
Setting 3: The diagonal elements of ΣA are all one and ∣JA∣ number of off-diagonal elements are ρ with random positions. We take (n, p) ∈ {(100, 600), (100, 1000)} and let the signal size ρ and sparsity level ∣JA∣ vary to examine how the power changes accordingly.
Setting 4: The diagonal elements of ΣA are all one and ∣JA∣ number of off-diagonal elements are uniformly generated from (0, 2ρ) with random positions. We take (n, p) = (100, 1000) and similarly let the signal size ρ and sparsity level ∣JA∣ vary to examine how the power changes accordingly.
Setting 5: We consider the multivariate models in [13]. Specifically, for each i = 1,…,n, xi = Ξzi + μ, where Ξ is a matrix of dimension p × m, and zi’s are i.i.d. Gaussian or Gamma random vectors. Under null hypothesis, m = p, Ξ = Ip, μ = 21p; under alternative hypothesis, m = p + 1, , . We also take the n and p combination in [13] with (n, p) ∈ {(40, 159), (40, 331), (80, 159), (80, 331), (80, 642)}.
We compare several methods in the literature, including both maximum-type and sum-of-squares-type tests. In particular, the maximum-type test statistic in Jiang [36] is taken as in this framework. Since the convergence in [36] is known to be slow, we use permutation to approximate the distribution in the simulations. In addition, we consider some sum-of-squares-type methods. Specifically, we examine the identity and sphericity tests in Chen et al. [13], which are denoted as “Equal” and “Spher,” respectively. We also compare the methods in Ledoit and Wolf [42] and Schott [57], which are referred to as “LW” and “Schott,” respectively.
To illustrate, Figure 2 summarizes the numerical results for the setting 3 when n = 100 and p = 1000. All the results are based on 1000 simulations at the 5% nominal significance level. In Figure 2, we present the power of single U-statistics with orders in {1,…, 6, ∞}. “adpUmin” and “adpUf” represent the results of the adaptive testing procedure using the minimum combination and Fisher’s method in Section 2.2, respectively. The simulation results show that the type I error rates of the U-statistics and adaptive test are well controlled under H0. In addition, Figure 2 exhibits several patterns that are consistent with the power analysis in Section 2.2. First, it shows that among the U-statistics, when ∣JA∣ is very small, performs best; and when ∣JA∣ increases, the performances of some U-statistics of finite orders catch up. For instance, when ∣JA∣ = 100, and are similar and are better than the other U-statistics; when ∣JA∣ = 400, and are similar and better than the other U-statistics. When ΣA is relatively dense, and become more powerful. Particularly, when ∣JA∣ = 1600, is powerful; when ∣JA∣ becomes larger, such as when ∣JA∣ = 3200, is overall the most powerful. Second, Figure 2 shows that “LW,” “Schott,” “Equal,” “Spher” and perform similarly under various cases. In particular, these methods are not powerful when the alternative is sparse but becomes more powerful when the alternative gets denser. This is because they are all sum-of-squares-type statistics that target at dense alternatives. Third and importantly, the two adaptive tests “adpUmin” and “adpUf” maintain high power across different settings. Specifically, they perform better than most single U-statistics: their powers are usually close to or even higher than the best single U-statistic. Moreover, “adpUmin” and “adpUf” generally have higher power than the compared existing methods. We also note that “adpUf” overall performs better than “adpUmin” in this simulation setting. In summary, Figure 2 demonstrates the relationship between the sparsity levels of alternatives and the power of the tests, confirming the theoretical conclusions in Section 2.2. Notably, the proposed adaptive testing procedure is powerful against a wide range of alternatives, and thus advantageous in practice when the true alternative is unknown.
Fig. 2.

Power comparison.
Due to the space limitation, we provide other extensive numerical studies in Supplementary Material [28], Section C.2. The conclusions are similar to those of Figure 2, and consistent with the theoretical results in Section 2.2. In particular, the results show that the empirical sizes of the tests are close to the nominal level, suggesting the good finite-sample performance of the asymptotic approximations. Moreover, under highly dense alternatives with only nonnegative entries in the covariance matrix, is the most powerful one among the ’s and the other tests in [13, 42, 57], in agreement with the results in Propositions 2.3 and 2.5. Furthermore, the proposed adaptive testing procedures often have higher power than most single U-statistics.
3.2. Real data analysis.
Alzheimer’s disease (AD) is the most prevalent neurodegenerative disease [56] and is ranked as the sixth leading cause of death in the US [68]. Every 65 seconds, someone in the US develops AD [2]. To advance our understanding of AD, the Alzheimer’s Disease Neuroimaging Initiative (ADNI) was started in 2004, collecting extensive genetic data for both healthy individuals and AD patients. To gain insight into the genetic mechanisms of AD, one can test a single SNP a time. However, due to a relatively small sample size of the ADNI data, scanning across all SNPs failed to identify any genomewide significant SNP (with p-value < 5 × 10−8) [40]. To date, the largest meta-analysis of more than 600,000 individuals identified 29 significant risk loci [35] and can only explain a small proportion of AD variance. On the other hand, a group of functionally related genes as annotated in a biological pathway are often involved in the same disease susceptibility and progression [29]. Thus, pathway-based analyses, which jointly analyze a group of SNPs in a biological pathway, have become increasingly popular. We retrieve a total of 214 pathways from the KEGG database [39] for the subsequent analysis.
Although pathway-based analyses with KEGG pathways are common in real studies, formally testing the correlations of the genes in a KEGG pathway has been largely untouched. Here, we apply our method and other competing methods in [13] to test if all the genes in a pathway have correlated gene expression levels. Perhaps as expected, all methods reject the null hypothesis for all pathways with highly significant p-values, since the KEGG pathways are constructed to include only the genes with similar function into the same pathway [39], while similar function often implies co-expression (and vice versa). To compare the performance of the different tests, for each pathway we randomly select 50 subjects and restrict our analysis to pathways of at least 50 genes, leading to 103 pathways for the following analysis. Then we perturb the data by shuffling the gene expression levels of randomly selected 100(1 – α)% genes in a pathway before applying each test. Figure 3 shows the performance of the tests with two significance cutoffs, where “” represents the single statistic, “adpU” represents our proposed adaptive testing procedure using the minimum combination with candidate U-statistics of orders in {1,…, 6, ∞}, and “Equal” and “Spher” represent the identity and sphericity tests in [13], respectively. Because all pathways are highly significant with all samples, we can treat all pathways as the true positives. Due to the adaptiveness of our proposed testing procedure, “adpU” identifies more significant pathways than the competing methods across all the levels of data perturbation (mimicking the varying sparsity levels of the alternatives).
Fig. 3.

Power comparison of different methods with ADNI data.
4. Other high-dimensional examples.
In this section, we apply the proposed U-statistics framework to other high-dimensional testing problems, including testing means, two-sample covariances, and regression coefficients in generalized linear regression models. Similar theoretical results to Section 2 are developed, with detailed proofs and related simulation studies provided in Supplementary Material [28].
4.1. Mean testing.
Testing mean vectors is widely used in many statistical analysis and applications [1, 50]. Under high-dimensional scenarios, for example, in genome-wide studies, dimension of the data is often much larger than the sample size, so traditional multivariate tests such as Hotelling’s T2-test either cannot be directly applied or have low power [18]. To address this issue, several new procedures for testing high-dimensional mean vectors have been proposed [4, 9, 11, 12, 16, 17, 25-27, 60, 62, 67]. However, many of the statistics only target at either sparse or dense alternatives, and suffer from loss of power for other types of alternatives. We next apply the U-statistics framework to one-sample and two-sample mean testing problems.
One-sample mean testing.
We first discuss the one-sample mean vector testing. Assume that x1,…, xn are n i.i.d. copies of a p-dimensional real-valued random vector x = (x1,…,xp)⊤ with mean vector μ = (μ1,…,μp)⊤, covariance matrix Σ = {σj1,j2 : 1 ≤ j1, j2 ≤ p}. We want to conduct the global test on H0 : μ = μ0 where μ0 = (μ1,0,…,μp,0)⊤ is given.
Similar to previous discussion, the parameter set that we are interested in is . For each j = 1,…, p, E(xi,j) = μj, so Kj(xi) = xi,j – μj,0 is a kernel function, which is a simple unbiased estimator of the target. Following our construction, the U-statistic for finite a is
| (4.1) |
which targets at , and the U-statistic corresponding to is with .
Given the statistics, we have the theoretical results similar to Theorems 2.1-2.3. The following Theorems 4.1-4.2 are established under similar conditions to that of Theorems 2.1-2.3. Due to the limited space, we provide the conditions and corresponding discussions in Supplementary Material [28].
Theorem 4.1. Under H0: μ = μ0, assume Condition A.2 in Supplementary Material [28]. Then for any finite integers {a1,…,am}, as n, p → ∞, , where with the order of Θ(a!pn−a).
Theorem 4.2. Under H0: μ = μ0, assume Condition A.3 in Supplementary Material [28]. Then , , as n, p → ∞, where τp = 2 log p – log log p. In addition, for any finite integer a, are asymptotically independent.
By Theorems 4.1 and 4.2, we obtain the asymptotic independence among the U-statistics and the corresponding limiting distributions of the U-statistics under H0. Under the alternative hypothesis, since the power analysis of the one-sample mean testing is similar to that of the two-sample case, we delay the power analysis after presenting the asymptotic independence property of the proposed U-statistics in the two-sample mean testing problem.
Two-sample mean testing.
Next, we discuss the two-sample mean testing problem. Suppose we have two groups of p-dimensional observations and , which are i.i.d. copies of two independent random vectors x = (x1, … , xp)⊤ and y = (y1, … , yp)⊤, respectively. Suppose E(x) = μ = (μ1, … , μp)⊤, E(y) = ν = (ν1, … , νp)⊤, cov(x) = Σx and cov(y) = Σy. We write n = nx + ny and assume nx = Θ(ny). For easy illustration, we first consider Σx = Σy = Σ = {σj1, j2 : 1 ≤ j1, j2 ≤ p}. We will then discuss the case when Σx ≠ Σy, where similar analysis applies.
The two-sample mean testing examines H0: μ = ν versus HA: μ ≠ ν, then . For 1 ≤ j ≤ p, 1 ≤ k ≤ nx, 1 ≤ s ≤ ny, Kj(xk, ys) = xk,j − ys,j is a simple unbiased estimator of μj − νj, and thus we construct , which is also equivalent to
| (4.2) |
We can check that (4.2) satisfies , so is an unbiased estimator of . On the other hand, for , following the maximum-type test statistic in Cai et al. [9], we have
| (4.3) |
where , . We then obtain results similar to Theorems 2.1, 2.3 and 2.5. As the conditions are similar to those in Section 2, we only keep the key conclusions, and the details of conditions and discussions are given in Supplementary Material [28], Section A.8.
Theorem 4.3. Under Condition A.4 in Supplementary Material [28], Σx = Σy and H0: μ = ν, for any finite integers (a1, … , am), as n, p → ∞, , where is of the order Θ(a!pn−a).
Theorem 4.4. Under Condition A.4 in Supplementary Material [28], Σx = Σy and H0: μ = ν, , , as n, p → ∞, where τp = 2log p − log log p. Moreover, of finite integer a and are asymptotically independent.
Theorems 4.3 and 4.4 provide the asymptotic properties of finite-order U-statistics and under H0. To analyze the power of ’s, we derive the asymptotic results of ’s under the alternative hypotheses. We focus on the two-sample mean testing problem, while one-sample mean testing can be obtained similarly. Specifically, we consider the alternative for j = 1, … , k0; μj − νj = 0 for j = k0 + 1, … , p}. We then obtain similar conclusions to Theorem 2.5.
Theorem 4.5. Assume Condition A.4 in Supplementary Material [28] and k0 = o(p). For any finite integers {a1, … , am}, if ρ in satisfies for t = 1, … , m, then , as n, p → ∞. Here, and , with of the order Θ(a!pn−a).
Next, we compare the power of different U-statistics under alternatives with different sparsity levels. Theorem 4.5 shows that under the local alternatives, the asymptotic power of mainly depends on . Therefore, by Theorem 4.5, given constant M > 0, for each , if , then ; that is, different ’s have the same power asymptotically. For easy illustration, we consider σj1, j2 = 1 when j1 = j2 ∈ {k0 + 1, … , p}, and σj1, j2 = 0 when j1 ≠ j2 ∈ {k0 + 1, … , p}, then with
| (4.4) |
Therefore, similar to the analysis in Section 2.2, to find the “best” , it suffices to find the order, denoted by a0, that gives the minimum ρa in (4.4). We have the following result similar to Proposition 2.3.
Proposition 4.1. Given any constant M ∈ (0, + ∞) and n, p, k0, we consider ρa in (4.4) as a function of positive integers a, then:
(i) when , the minimum of ρa is achieved at a0 = 1;
(ii) when , the minimum of ρa is achieved at some a0, which increases as increases.
Proposition 4.1 shows that when the sparsity level k0 is large, that is, is dense, a small a tends to obtain a smaller lower bound in ρ, and vice versa. As (4.4) and (2.13) are similar, we have similar patterns to that in Figure 1 when examining the corresponding numerical plots of ρa. In addition, [9] shows that when for a large C1, the power of converges to 1, and is minimax rate optimal for sparse alternatives; see also [17]. Thus, if ρ∞ < ρa0, that is, , is the “best” and its lowest detectable order of ρ is . On the other hand, Proposition 4.1 shows that when is dense with , is the “best” and its lowest detectable order of ρ is . Moreover, for some large M and C2, when is “moderately dense” or “moderately sparse” with , is the “best” and its lowest detectable order of ρ is , which is of a smaller order than the optimal detection boundary of the sparse case .
More generally, when Σx ≠ Σy, similar results to Theorems 4.3 and 4.5 can be obtained. In particular, we have the following corollary.
Corollary 4.1. When Σx ≠ Σy, under Condition A.4 in Supplementary Material [28], Theorem 4.3 holds with and Theorem 4.5 holds with .
Corollary 4.1 shows that the asymptotic power of finite-order U-statistics depends on . By the construction of finite-order U-statistics and the proof, we obtain that and . We then know that for finite-order U-statistics, similar results to Proposition 4.1 still hold by examining .
The above power analysis shows that the optimal U-statistic varies when the alternative hypothesis changes. To achieve high power across various alternatives, we can develop an adaptive test similar to that in Section 2.3. Specifically, we calculate the p-values of the U-statistics (4.1) and (4.2) following the theoretical results above and the algorithm in Section 2.3. By combining the p-values as discussed in Section 2.3, the asymptotic power of the adaptive test goes to 1 if there exists one whose power goes to 1.
Remark 4.1. Xu et al. [67] has also discussed the adaptive testing of two-sample mean that is powerful against various ℓp-norm-like sums of μ − ν. But [67] is under the framework of a family of von Mises V-statistics where . We note that is equivalent to
which allows the indexes k’s and s’s to be the same, and thus is different from the U-statistics in (4.2). [67] shows that the constructed V-statistics are biased estimators of , and and are asymptotically independent if a + b is odd, but are asymptotically correlated if a + b is even. The constructed U-statistics in this work extend the properties of those V-statistics such that in (4.2) is an unbiased estimator of , and all ’s are asymptotically independent with each other. Given these nice statistical properties, it becomes easier to obtain the joint asymptotic distribution of the U-statistics, and then apply the adaptive test.
4.2. Two-sample covariance testing.
The U-statistics framework can be applied similar to testing the equality of two covariance matrices. Suppose and are i.i.d. copies of two independent random vectors x = (x1, … , xp)⊤ and y = (y1, … , yp)⊤, respectively. Denote E(x) = μ = (μ1, … , μp)⊤, E(y) = ν = (ν1, … , νp)⊤; cov(x) = Σx = [σx, j1, j2 : 1 ≤ j1, j2 ≤ p} and cov(y) = Σy = [σy, j1, j2 : 1 ≤ j1, j2 ≤ p}. Consider H0 : Σx = Σy = Σ = (σj1, j2)p×p. Given 1 ≤ j1, j2 ≤ p, 1 ≤ k1 ≠ k2 ≤ nx, and 1 ≤ s1 ≠ s2 ≤ ny, Kj1, j2 (xk1, xk2, ys1, ys2 ) = (xk1,j1 xk1,j2 − xk1,j1 xk2,j2) − (ys1,j1 ys1,j2 − ys1,j1 ys2,j2) is a simple unbiased estimator of σx, j1, j2 − σy, j1, j2. Therefore, for a finite positive integer a, we have the U-statistic
| (4.5) |
As in Remark 2.1, another formulation of equivalent to (4.5) is
| (4.6) |
where , and (4.6) shall be used in the theoretical developments.
We next present the asymptotic results of the constructed U-statistics under the null hypothesis. Here, we assume the regularity Condition A.5 or A.6, whose details and discussions are provided in Section A.13.1 of Supplementary Material [28] due to the space limitation. We mention that Condition A.5 is a mixing-type dependence assumption similar to Condition 2.2, and Condition A.6 is a moment-type dependence assumption similar to Condition 2.2*. Particularly, Condition A.6 extends the moment assumption for second-order U-statistics in Li and Chen [45] to U-statistics of general orders; please see the detailed discussions in Section A.13.1.
Theorem 4.6. Under H0 and Condition A.5 or A.6 in Supplementary Material [28], for finite integers {a1, … , am}, , where for a ∈ {a1, … , am},
with and .
Theorem 4.6 provides the asymptotic independence and joint normality of the finite-order U-statistics, which are similar to Theorems 2.1, 4.1 and 4.3. To further study the power of these finite-order U-statistics, we next consider the alternative hypotheses where Σx ≠ Σy. Let be the largest subset of {1, … , p} such that σx, j1, j2 = σy, j1, j2 = σj1, j2 for any j1, . We then obtain the following theorem under the regularity conditions given in Section A.14 of Supplementary Material [28].
Theorem 4.7. Under Conditions A.7 and A.8 in Supplementary Material [28], for finite integers {a1, … , am}, , where
and Cκ,a = {(κx − 1)/nx + (κy − 1)/ny}a + 2(κx/nx + κy/ny)a with κx and κy given in Condition A.7.
Given the asymptotic results under the alternatives, we next analyze the power of the finite-order U-statistics. By Theorem 4.7, the asymptotic power of depends on . Let JD = {(j1, j2) : σx, j1, j2 ≠ σy, j1, j2, 1 ≤ j1, j2 ≤ p}, then . Similar to Section 2.2, to study the relationship between the sparsity level of Σx − Σy and the power of U-statistics, we consider the case where the nonzero differences between Σx and Σy are the same. Specifically, let σx, j1, j2 − σy, j1, j2 = ρ for (j1, j2) ∈ JD, and then . Following the analysis in Section 2.2, we compare the ρ values needed by different ’s to achieve for a given constant M. In particular, for given integer a, suppose is achieved when ρ = ρa. For any a ≠ b, we compare and following Criterion 1.
We use the following example as an illustration, where Σx and Σy satisfy the conditions of Theorem 4.7. Specifically, we assume that Σx = (σx, j1, j2)p×p has the diagonal elements σx, j, j = ν2; and the off-diagonal elements σx, j1, j2 = h∣j1−j2∣ ∈ (0, ν2) with h∣j1−j2∣ = Θ(ν2) when ∣j1 − j2∣ ≤ s, while σx, j1, j2 = 0 when ∣j1 − j2∣ > s. This covers the moving average covariance structure of order s, and Σx is a banded matrix with bandwidth s. In addition, we assume the bandwidth s = o(p) and . By the definition of , the assumption implies that a large square sub-matrix of Σx and Σy are the same. For simplicity, we let nx = ny with n = nx + ny, and a similar analysis can be applied when nx ≠ ny. By Theorem 4.7, , where κ1 = κx + κy and κ2 = κx + κy − 2. Therefore, we know for given finite integer a, holds when ρ = ρa defined as
We next compare the ρa’s and obtain the following proposition.
Proposition 4.2. There exists that only depends on the given κx, κy, ν2, s, and ht, t = 1, … , s, and satisfies such that:
(i) When , the minimum of ρa is achieved at a0 = 1.
(ii) When , the minimum of ρa is achieved at some a0, which increases as Mp/∣JD∣ increases.
Proposition 4.2 is similar to Propositions 2.3 and 4.1. Following the analysis in Section 2.2, Proposition 4.2 shows that when the difference Σx − Σy is “very” dense with , is the most powerful U-statistic; when Σx − Σy becomes sparser as Mp/∣JD∣ decreases, a higher-order U-statistic is more powerful; when the Σx − Σy is “moderately” dense or sparse, a U-statistic of finite order a0 > 1 would be the most powerful one.
The power analysis above shows that the power of the U-statistics varies when the alternative changes. To maintain high power across different alternatives, we can develop an adaptive testing procedure similar to that in Section 2.3. Given the asymptotic independence in Theorem 4.6, an adaptive testing procedure using the constructed ’s is valid with the type I error asymptotically controlled. Also, the adaptive test achieves high power by combining the U-statistics as discussed in Section 2.3.
We provide simulation studies on two-sample covariance testing in Supplementary Material [28], Section C.3. By the simulations, we first find that the type I errors of the U statistics and the adaptive test are well controlled under H0. This verifies the theoretical results in Theorem 4.7. Second, similar to the one-sample covariance testing, we find that generally when the difference Σx − Σy is sparser, a U-statistic of higher order is more powerful, and vice versa. Moreover, under moderately sparse/dense alternatives, with a0 > 1 could achieve the highest power. The results are consistent with Proposition 4.2. Third, we compare the proposed adaptive test with existing methods in literature including [6, 45, 57, 61], and find that the proposed adaptive testing procedure maintains high power across various alternatives.
Remark 4.2. Similar to Section 2, we can let be the maximum-type test statistic in [6], and expect that the result similar to Theorem 2.3 holds under certain regularity conditions. However, as the dependence structure of two-sample covariance matrices is more complicated than the one-sample case, it is more challenging to establish the asymptotic joint distribution of and finite-order U-statistics. We leave this interesting problem for future study, while find in simulations that the performance of is similar to high-order U-statistics ’s.
4.3. Generalized linear model.
In this section, we consider Example 3 of generalized linear models (on page 156) to show that the proposed framework can be extended to other testing problems. Similar to the results in Section 4.1, we show that the constructed U-statistics are asymptotically independent and normally distributed, and also establish the power analysis results of the U-statistics. We provide the details in Section A.16 of Supplementary Material [28]. Recently, Wu et al. [65] also discussed the adaptive testing of generalized linear model. But [65] is under the framework of a family of von Mises V-statistics, and thus is different from the current paper as discussed in Remark 4.1. Moreover, the current work provides the theoretical power analysis while [65] did not.
5. Discussion.
This paper introduces a general U-statistics framework for applications to high-dimensional adaptive testing. Particularly, we focus on the examples including testing of means, covariances and regression coefficients in generalized linear models. Under the null hypothesis, we prove that the U-statistics of finite orders have asymptotic joint normality, and establish the asymptotic mutual independence among the finite-order U-statistics and . Moreover, under alternative hypotheses, we analyze the power of different U-statistics and demonstrate how the most powerful U-statistic changes with the sparsity level of the alternative parameters. Based on the theoretical results, we propose an adaptive testing procedure, which is powerful against different alternatives. The superior performance of this adaptive testing is confirmed in the simulations and real data analysis.
There are several possible extensions of the U-statistics framework in this paper. First, by our current proof, the convergence rate in Theorem 2.3 is bounded by O(log−1/2 p), which is an upper bound and not sharp. From our extensive simulations, we find that the type I error rate of the adaptive testing is well controlled with a relatively small p, for example, p = 50. We might obtain a shaper bound of the convergence rate, but more refined concentration property of the high-dimensional and high-order U-statistics is needed. Second, the proposed framework requires that the elements in the parameter set have unbiased estimates. When we cannot obtain unbiased estimates easily, for example, for the precision matrix, the proposed construction may not follow directly. Nevertheless we may use “nearly” unbiased estimators to construct “U-statistics” for hypothesis testing, such as the “nearly” unbiased estimator of the precision matrix proposed in [66]; the main challenge is then to control the accumulative bias over the parameters under high dimensions. Third, this paper discusses the examples where the elements in are comparable. When the parameters in are not comparable, such as containing both means and covariances parameters, the construction of U-statistics still follows but the theoretical derivation may require a careful case-by-case examination. Fourth, the construction of the U-statistics treats the parameters in with equal weight. More generally, we could assign different weights to different parameter estimators. For instance, standardizing the data is one example of assigning different weights. As inappropriate weight assignments could lead to power loss, when the truth is unknown, how to effectively assign weights to maximize the test power is an interesting research question. We shall discuss these extensions in the future as a significant amount of additional work is still needed.
In addition to the examples in this paper, the proposed U-statistics framework can be applied to other high-dimensional hypothesis testing problems. For example, it can be applied to testing the block-diagonality of a covariance matrix, whose theoretical analysis would be similar to the considered one sample and two sample covariance testing problems. It can also be used to test high-dimensional regression coefficients in complex regression models other than the generalized linear models, following a similar construction based on the score functions. A key step is then to characterize the impact of nuisance parameters that are estimated under the null hypothesis, and challenges arise especially when the nuisance parameters are high dimensional. Such interesting extensions will be further explored in our follow-up studies.
Supplementary Material
Acknowledgments.
The authors thank Co-Editors, Professor Edward I. George and Professor Richard J. Samworth, an Associate Editor and three anonymous referees for their constructive comments. The authors also thank Professor Ping-Shou Zhong for sharing the code of the paper [13] and Professor Xuming He and Professor Peter Song for helpful discussions.
This research is supported by NSF Grants DMS-1711226, DMS-1712717, SES-1659328, CAREER SES-1846747, and NIH grants R01GM113250, R01GM126002, R01HL105397 and R01HL116720.
Footnotes
SUPPLEMENTARY MATERIAL
Supplement to “Asymptotically independent U-statistics in high-dimensional testing” (DOI: 10.1214/20-AOS1951SUPP; .pdf). This supplementary material contains the technical proofs of the main paper and additional simulations.
REFERENCES
- [1].Anderson TW (2009). An Introduction to Multivariate Statistical Analysis. Wiley, New York. [Google Scholar]
- [2].Alzheimer’s Association (2018). 2018 Alzheimer’s disease facts and figures. Alzheimer’s Dement. 14 367–429. [Google Scholar]
- [3].Bai Z, Jiang D, Yao J-F and Zheng S (2009). Corrections to LRT on large-dimensional covariance matrix by RMT. Ann. Statist 37 3822–3840. MR2572444 10.1214/09-AOS694 [DOI] [Google Scholar]
- [4].Bai Z and Saranadasa H (1996). Effect of high dimension: By an example of a two sample problem. Statist. Sinica 6 311–329. MR1399305 [Google Scholar]
- [5].Bickel PJ and Levina E (2008). Regularized estimation of large covariance matrices. Ann. Statist 36 199–227. MR2387969 10.1214/009053607000000758 [DOI] [Google Scholar]
- [6].Cai T, Liu W and Xia Y (2013). Two-sample covariance matrix testing and support recovery in high-dimensional and sparse settings. J. Amer Statist. Assoc 108 265–277. MR3174618 10.1080/01621459.2012.758041 [DOI] [Google Scholar]
- [7].Cai TT (2017). Global testing and large-scale multiple testing for high-dimensional covariance structures. Annu. Rev. Stat. Appl 4 423–446. 10.1146/annurev-statistics-060116-053754 [DOI] [Google Scholar]
- [8].Cai TT and Jiang T (2011). Limiting laws of coherence of random matrices with applications to testing covariance structure and construction of compressed sensing matrices. Ann. Statist 39 1496–1525. MR2850210 10.1214/11-AOS879 [DOI] [Google Scholar]
- [9].Cai TT, Liu W and Xia Y (2014). Two-sample test of high dimensional means under dependence. J. R. Stat. Soc. Ser B. Stat. Methodol 76 349–372. MR3164870 10.1111/rssb.12034 [DOI] [Google Scholar]
- [10].Cai TT and Ma Z (2013). Optimal hypothesis testing for high dimensional covariance matrices. Bernoulli 19 2359–2388. MR3160557 10.3150/12-BEJ455 [DOI] [Google Scholar]
- [11].Chen SX, Li J and Zhong P-S (2019). Two-sample and ANOVA tests for high dimensional means. Ann. Statist 47 1443–1474. MR3911118 10.1214/18-AOS1720 [DOI] [Google Scholar]
- [12].Chen SX and Qin Y-L (2010). A two-sample test for high-dimensional data with applications to gene-set testing. Ann. Statist 38 808–835. MR2604697 10.1214/09-AOS716 [DOI] [Google Scholar]
- [13].Chen SX, Zhang L-X and Zhong P-S (2010). Tests for high-dimensional covariance matrices. J. Amer. Statist. Assoc 105 810–819. MR2724863 10.1198/jasa.2010.tm09560 [DOI] [Google Scholar]
- [14].Chen X (2018). Gaussian and bootstrap approximations for high-dimensional U-statistics and their applications. Ann. Statist 46 642–678. MR3782380 10.1214/17-AOS1563 [DOI] [Google Scholar]
- [15].Colantuoni C, Lipska BK, Ye T, Hyde TM, Tao R, Leek JT, Colantuoni EA, Elkahloun AG, Herman MM et al. (2011). Temporal dynamics and genetic control of transcription in the human prefrontal cortex. Nature 478 519. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [16].Donoho D and Jin J (2004). Higher criticism for detecting sparse heterogeneous mixtures. Ann. Statist 32 962–994. MR2065195 10.1214/009053604000000265 [DOI] [Google Scholar]
- [17].Donoho D and Jin J (2015). Higher criticism for large-scale inference, especially for rare and weak effects. Statist. Sci 30 1–25. MR3317751 10.1214/14-STS506 [DOI] [Google Scholar]
- [18].Fan J (1996). Test of significance based on wavelet thresholding and Neyman’s truncation. J. Amer. Statist. Assoc 91 674–688. MR1395735 10.2307/2291663 [DOI] [Google Scholar]
- [19].Fan J, Han F and Liu H (2014). Challenges of big data analysis. Nat. Sci. Rev 1 293–314. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [20].Fan J, Liao Y and Yao J (2015). Power enhancement in high-dimensional cross-sectional tests. Econometrica 83 1497–1541. MR3384226 10.3982/ECTA12749 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [21].Fan J, Lv J and Qi L (2011). Sparse high dimensional models in economics. Ann. Rev. Econ 3 291–317. 10.1146/annurev-economics-061109-080451 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [22].Frahm G (2004). Generalized elliptical distributions: Theory and applications. Ph.D. thesis, Univ. Köln. [Google Scholar]
- [23].Friston KJ (2009). Modalities, modes, and models in functional neuroimaging. Science 326 399–403. 10.1126/science.1174521 [DOI] [PubMed] [Google Scholar]
- [24].Gaetan C and Guyon X (2010). Spatial Statistics and Modeling. Springer Series in Statistics. Springer, New York. MR2569034 10.1007/978-0-387-92257-7 [DOI] [Google Scholar]
- [25].Goeman JJ, van de Geer SA and van Houwelingen HC (2006). Testing against a high dimensional alternative. J. R. Stat. Soc. Ser. B. Stat. Methodol 68 477–493. MR2278336 10.1111/j.1467-9868.2006.00551.x [DOI] [Google Scholar]
- [26].Gregory KB, Carroll RJ, Baladandayuthapani V and Lahiri SN (2015). A two-sample test for equality of means in high dimension. J. Amer. Statist. Assoc 110 837–849. MR3367268 10.1080/01621459.2014.934826 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [27].Hall P and Jin J (2010). Innovated higher criticism for detecting sparse signals in correlated noise. Ann. Statist 38 1686–1732. MR2662357 10.1214/09-AOS764 [DOI] [Google Scholar]
- [28].He Y, Xu G, Wu C and Pan W (2021). Supplement to “Asymptotically independent U-statistics in high-dimensional testing.” 10.1214/20-AOS1951SUPP [DOI] [PMC free article] [PubMed] [Google Scholar]
- [29].Heinig M, Petretto E, Wallace C, Bottolo L, Rotival M, Lu H, Li Y, Sarwar R, Langley SR et al. (2010). A trans-acting locus regulates an anti-viral expression network and type 1 diabetes risk. Nature 467 460. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [30].Ho H-C and Hsing T (1996). On the asymptotic joint distribution of the sum and maximum of stationary normal random variables. J. Appl. Probab 33 138–145. MR1371961 10.2307/3215271 [DOI] [Google Scholar]
- [31].Ho H-C and Mccormick WP (1999). Asymptotic distribution of sum and maximum for Gaussian processes. J. Appl. Probab 36 1031–1044. MR1742148 10.1239/jap/1032374753 [DOI] [Google Scholar]
- [32].Hoeffding W (1948). A class of statistics with asymptotically normal distribution. Ann. Math. Stat 19 293–325. MR0026294 10.1214/aoms/1177730196 [DOI] [Google Scholar]
- [33].Hsing T (1995). A note on the asymptotic independence of the sum and maximum of strongly mixing stationary random variables. Ann. Probab 23 938–947. MR1334178 [Google Scholar]
- [34].James B, James K and Qi Y (2007). Limit distribution of the sum and maximum from multivariate Gaussian sequences. J. Multivariate Anal 98 517–532. MR2293012 10.1016/j.jmva.2006.06.009 [DOI] [Google Scholar]
- [35].Jansen IE, Savage JE, Watanabe K, Bryois J, Williams DM et al. (2019). Genome-wide meta-analysis identifies new loci and functional pathways influencing Alzheimer’s disease risk. Nat. Genet 51 404–413. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [36].Jiang T (2004). The asymptotic distributions of the largest entries of sample correlation matrices. Ann. Appl. Probab 14 865–880. MR2052906 10.1214/105051604000000143 [DOI] [Google Scholar]
- [37].Jiang T and Yang F (2013). Central limit theorems for classical likelihood ratio tests for high-dimensional normal distributions. Ann. Statist 41 2029–2074. MR3127857 10.1214/13-AOS1134 [DOI] [Google Scholar]
- [38].Johnstone IM (2001). On the distribution of the largest eigenvalue in principal components analysis. Ann. Statist 29 295–327. MR1863961 10.1214/aos/1009210544 [DOI] [Google Scholar]
- [39].Kanehisa M, Goto S, Furumichi M, Tanabe M and Hirakawa M (2010). KEGG for representation and analysis of molecular networks involving diseases and drugs. Nucleic Acids Res. 38 D355–D360. 10.1093/nar/gkp896 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [40].Kim J, Zhang Y and Pan W (2016). Powerful and adaptive testing for multi-trait and multi-SNP associations with GWAS and sequencing data. Genetics 203 715–731. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [41].Lan W, Luo R, Tsai C-L, Wang H and Yang Y (2015). Testing the diagonality of a large covariance matrix in a regression setting. J. Bus. Econom. Statist 33 76–86. MR3303743 10.1080/07350015.2014.923317 [DOI] [Google Scholar]
- [42].Ledoit O and Wolf M (2002). Some hypothesis tests for the covariance matrix when the dimension is large compared to the sample size. Ann. Statist 30 1081–1102. MR1926169 10.1214/aos/1031689018 [DOI] [Google Scholar]
- [43].Leung D and Drton M (2018). Testing independence in high dimensions with sums of rank correlations. Ann. Statist 46 280–307. MR3766953 10.1214/17-AOS1550 [DOI] [Google Scholar]
- [44].Li D and Xue L (2015). Joint limiting laws for high-dimensional independence tests. ArXiv E-prints. [Google Scholar]
- [45].Li J and Chen SX (2012). Two sample tests for high-dimensional covariance matrices. Ann. Statist 40 908–940. MR2985938 10.1214/12-AOS993 [DOI] [Google Scholar]
- [46].Liu W-D, Lin Z and Shao Q-M (2008). The asymptotic distribution and Berry–Esseen bound of a new test for independence in high dimension with an application to stochastic optimization. Ann. Appl. Probab 18 2337–2366. MR2474539 10.1214/08-AAP527 [DOI] [Google Scholar]
- [47].Manolio TA, Collins FS, Cox NJ, Goldstein DB, Hindorff LA et al. (2009). Finding the missing heritability of complex diseases. Nature 461 747. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [48].Mccormick WP and Qi Y (2000). Asymptotic distribution for the sum and maximum of Gaussian processes. J. Appl. Probab 37 958–971. MR1808861 10.1239/jap/1014843076 [DOI] [Google Scholar]
- [49].Mosteller F and Fisher RA (1948). Questions and answers. Amer. Statist 2 30–31. [Google Scholar]
- [50].Muirhead RJ (2009). Aspects of Multivariate Statistical Theory. Wiley, New York. [Google Scholar]
- [51].Paindaveine D and Van Bever G (2014). Inference on the shape of elliptical distributions based on the MCD. J. Multivariate Anal 129 125–144. MR3215984 10.1016/j.jmva.2014.04.013 [DOI] [Google Scholar]
- [52].Pan W, Kim J, Zhang Y, Shen X and Wei P (2014). A powerful and adaptive association test for rare variants. Genetics 197 1081–1095. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [53].Péché S (2009). Universality results for the largest eigenvalues of some sample covariance matrix ensembles. Probab. Theory Related Fields 143 481–516. MR2475670 10.1007/s00440-007-0133-7 [DOI] [Google Scholar]
- [54].Peng Z and Nadarajah S (2003). On the joint limiting distribution of sums and maxima of stationary normal sequence. Theory Probab. Appl 47 706–709. [Google Scholar]
- [55].Pham TD and Tran LT (1985). Some mixing properties of time series models. Stochastic Process. Appl 19 297–303. MR0787587 10.1016/0304-4149(85)90031-6 [DOI] [Google Scholar]
- [56].Prince M, Bryce R, Albanese E, Wimo A, Ribeiro W and Ferri CP (2013). The global prevalence of dementia: A systematic review and metaanalysis. Alzheimer’s Dement. 9 63–75. [DOI] [PubMed] [Google Scholar]
- [57].Schott JR (2007). A test for the equality of covariance matrices when the dimension is large relative to the sample sizes. Comput. Statist. Data Anal 51 6535–6542. MR2408613 10.1016/j.csda.2007.03.004 [DOI] [Google Scholar]
- [58].Shao Q-M and Zhou W-X (2014). Necessary and sufficient conditions for the asymptotic distributions of coherence of ultra-high dimensional random matrices. Ann. Probab 42 623–648. MR3178469 10.1214/13-AOP837 [DOI] [Google Scholar]
- [59].Soshnikov A (2002). A note on universality of the distribution of the largest eigenvalues in certain sample covariance matrices. J. Stat. Phys 108 1033–1056. MR1933444 10.1023/A:1019739414239 [DOI] [Google Scholar]
- [60].Srivastava MS and Du M (2008). A test for the mean vector with fewer observations than the dimension. J. Multivariate Anal 99 386–402. MR2396970 10.1016/j.jmva.2006.11.002 [DOI] [Google Scholar]
- [61].Srivastava MS and Yanagihara H (2010). Testing the equality of several covariance matrices with fewer observations than the dimension. J. Multivariate Anal 101 1319–1329. MR2609494 10.1016/j.jmva.2009.12.010 [DOI] [Google Scholar]
- [62].Srivastava R, Li P and Ruppert D (2016). RAPTT: An exact two-sample test in high dimensions using random projections. J. Comput. Graph. Statist 25 954–970. MR3533647 10.1080/10618600.2015.1062771 [DOI] [Google Scholar]
- [63].Storey JD and Tibshirani R (2003). Statistical significance for genomewide studies. Proc. Natl. Acad. Sci. USA 100 9440–9445. MR1994856 10.1073/pnas.1530509100 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [64].Wang L, Jia P, Wolfinger RD, Chen X and Zhao Z (2011). Gene set analysis of genome-wide association studies: Methodological issues and perspectives. Genomics 98 1–8. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [65].Wu C, Xu G and Pan W (2019). An adaptive test on high-dimensional parameters in generalized linear models. Statist. Sinica 29 2163–2186. MR3970351 [Google Scholar]
- [66].Xia Y, Cai T and Cai TT (2015). Testing differential networks with applications to the detection of gene-gene interactions. Biometrika 102 247–266. MR3371002 10.1093/biomet/asu074 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [67].Xu G, Lin L, Wei P and Pan W (2016). An adaptive two-sample test for high-dimensional means. Biometrika 103 609–624. MR3551787 10.1093/biomet/asw029 [DOI] [PMC free article] [PubMed] [Google Scholar]
- [68].Xu J, Murphy SL, Kochanek KD, Bastian B and Arias E (2018). Deaths: Final data for 2016. Natl. Vital Stat. Rep 67 1–76. [PubMed] [Google Scholar]
- [69].Xu Z, Xu G and Pan W (2017). Adaptive testing for association between two random vectors in moderate to high dimensions. Genet. Epidemiol 41 599–609. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [70].Yang Q and Pan G (2017). Weighted statistic in detecting faint and sparse alternatives for high-dimensional covariance matrices. J. Amer. Statist. Assoc 112 188–200. MR3646565 10.1080/01621459.2015.1122602 [DOI] [Google Scholar]
- [71].Yu K, Li Q, Bergen AW, Pfeiffer RM, Rosenberg PS, Caporaso N, Kraft P and Chatterjee N (2009). Pathway analysis by adaptive combination of p-values. Genet. Epidemiol 33 700–709. [DOI] [PMC free article] [PubMed] [Google Scholar]
- [72].Zhong P-S and Chen SX (2011). Tests for high-dimensional regression coefficients with factorial designs. J. Amer. Statist. Assoc 106 260–274. MR2816719 10.1198/jasa.2011.tm10284 [DOI] [Google Scholar]
- [73].Zhong P-S, Chen SX and Xu M (2013). Tests alternative to higher criticism for high-dimensional means under sparsity and column-wise dependence. Ann. Statist 41 2820–2851. MR3161449 10.1214/13-AOS1168 [DOI] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.