

Abstract
Joint models of longitudinal process and time‐to‐event data have recently gained attention, notably to provide individualized dynamic predictions. In the presence of competing risks, models published mostly involve cause‐specific hazard functions jointly estimated with a linear or generalized linear model. Here we propose to extend the modeling to full parametric joint estimation of a nonlinear mixed‐effects model and a subdistribution hazard model. We apply this approach on 6046 patients admitted in intensive care unit (ICU) for sepsis with daily Sequential Organ Failure Assessment (SOFA) score measurements. The joint model is built on a randomly selected training set of two thirds of patients and links the current predicted SOFA measurement to the instantaneous risks of ICU death and discharge from ICU, both adjusted on the patient age. Stochastic Approximation Expectation Maximization algorithm in Monolix is used for estimation. SOFA evolution is significantly associated with both risks: 0.37, 95% confidence interval (CI) = [0.35, 0.39] for the risk of death and −0.38, 95% CI = [−0.39, −0.36] for the risk of discharge. A simulation study, inspired from the real data, shows the good estimation properties of the parameters. We assess on the validation set the added value of modeling the longitudinal SOFA follow‐up for the prediction of death compared with a model that includes only SOFA at baseline. Time‐dependent receiver operating characteristic area under the curve and Brier scores show that when enough longitudinal individual information is available, joint modeling provides better predictions. The methodology can easily be applied to other clinical applications because of the general form of the model.
Study Highlights.
WHAT IS THE CURRENT KNOWLEDGE ON THE TOPIC?
Joint modeling under competing risk setting has been rarely described in the literature, especially when dealing with nonlinear mixed‐effects models (NLMEMs). Most published models considered a linear biomarker evolution, possibly with spline functions to deal with nonlinearity. One considers an NLMEM model jointly estimated with a cause‐specific multistate model using NONMEM software.
WHAT QUESTION DID THIS STUDY ADDRESS?
We propose an approach to model joint estimation of NLMEM and competing risks using a parametric subdistribution hazard model. We apply this new approach on a large data set of patients admitted in intensive care unit (ICU) for sepsis, with daily Sequential Organ Failure Assessment (SOFA) score assessments, to predict the risk of death with the competing risk being discharge from ICU.
WHAT DOES THIS STUDY ADD TO OUR KNOWLEDGE?
The Stochastic Approximation Expectation Maximization algorithm can be used to provide unbiased estimates of such model parameters. In the real case application, we showed that the joint modeling improves the quality of predictions when sufficient SOFA follow‐up is considered compared with a model that only uses baseline information.
HOW MIGHT THIS CHANGE DRUG DISCOVERY, DEVELOPMENT, AND/OR THERAPEUTICS?
The methodology can be easily extended to other clinical applications of individualized predictions, which is useful because a competing risk setting arises in many biomedical applications.
INTRODUCTION
A major ambition of precision medicine is to provide every patient with a personalized and adapted medical treatment. Individual dynamic predictions of a clinical outcome based on discrete longitudinal observations of a biomarker fully enter the scope of precision medicine. To get individual predictions that can be updated as more observations become available, a natural approach is to use the fit of a joint model combining (i) the longitudinal model for the evolution of the biomarker and (ii) the time‐to‐event process describing the risk of the clinical outcome in consideration.
This joint modeling approach has recently gained attention, 1 , 2 , 3 , 4 mainly for two reasons. First, a much simpler strategy where biomarker observations are included as a time‐varying covariate in a survival model imposes to make a hypothesis about the marker evolution between measurements, neglects measurement errors, and is known to be incorrect because of the endogenous nature of the covariate (i.e., whose existence is directly related to failure status). 5 , 6 Second, one could consider fitting a first model for the biomarker evolution and then plugging the predicted evolution as a time‐dependent covariate in the survival model, resulting in a so‐called two‐stage procedure. Unfortunately, the dropout process induced by the survival model, that is, the onset of an event that precludes any further biomarker measurements, generates missing data for the biomarker that can be not at random (missing not at random [MNAR]). This leads to possible bias in the estimations as described in a published study. 7 The joint modeling approach genuinely overcomes these two methodological issues. A recent publication 8 proposes a workflow for a joint model of longitudinal and time‐to‐event data.
Competing risks are frequent in biomedical applications, where patients are at risk of multiple and mutually exclusive events (e.g., death and relapse in oncology or death and discharge in a hospital ward). When dealing with competing events, two distinct risks can be modeled: the cause‐specific hazard (CSH) 9 and the subdistribution hazard (SDH). 10 Although both approaches are essentially two different parametrizations of the same random process, some authors argue that the CSH parameters are more suitable for etiologic studies and SDH parameters for risk prediction. 11 , 12 We also emphasize that the hypothesis of proportionality of risks on CSH and SDH are generally not compatible. 13 Although the cause‐specific approach was the most often used in the context of joint modeling, 3 , 14 , 15 , 16 we decided here to analyze the data assuming that the hypothesis of proportional hazards holds on the SDHs.
The joint estimation with competing risks complicates the analysis, especially when the biomarker evolution is associated with the risk of both events. In the literature, linear 17 , 18 , 19 and nonlinear 1 , 4 , 20 joint models have been extensively described. However, when dealing with competing risks, linear mixed‐effects submodels, possibly involving a combination of spline functions to deal with nonlinearity (using R‐INLA 21 or JMbayes 15 ) are predominant. To our knowledge, only one study 22 considered a nonlinear mixed‐effects model (NLMEM) jointly estimated with a cause‐specific multistate model using NONMEM software (ICON plc).
A popular application when treating of joint models is to derive individual dynamic predictions of both marker evolution and associated risks of event. It consists of considering a so‐called landmark time and predicting, for one individual, the future evolution of the marker and the cumulative incidences of the competing events conditionally to the overall survival up to that landmark time. 1 , 23 In that case, the competing risk framework imposes to carefully define the at‐risk population for predictions, in particular when assessing their performances.
In this work, we propose to use Monolix software (Lixoft) to jointly estimate a nonlinear mixed‐effects submodel for modeling the longitudinal trajectory of a biomarker and a parametric SDH submodel for modeling multiple risks of events. This approach is then applied to a subset of OUTCOMEREA database in patients admitted in intensive care unit (ICU) for sepsis, a life‐threatening condition where severe organ dysfunctions are caused by the infection of the organism by a pathogen. 24 We also propose a simulation study to assess performances of the estimation in terms of relative bias and relative root mean square error.
METHODS
General framework
Joint Model
Nonlinear mixed‐effects models
Let N be the number of subjects and the vector of longitudinal observations of subject i (for i = 1, … , N). Observation y ij denotes the jth measurement of patient i at time t ij (for j = 0, … , n i ). Let m be the known nonlinear function describing the structural model and g the known function describing the error model. The NLMEM writes as follows:
| (1) |
ψ i = f(μ, η i , Z i ) denotes the individual parameters expressed as a function of population parameters, noted μ; individual random effects, noted η i ; and an optional vector of individual covariates Z i . The random effects are assumed to be normally distributed with mean 0 and variance–covariance matrix Ω, and independent of the residual Gaussian error, noted ϵ ij , of mean 0 and variance 1. σ denotes the vector of the error model parameters.
SDH models
Let the variable T describe the time‐to‐event distribution, C the noninformative censoring time, and K denotes the event type that occurs. For the sake of simplicity, we consider only two events . We set as the event indicator, thus δ = K in case of failure and δ = 0 in case of censoring. The couple with is observed for each individual. The cumulative incidence on event k is modeled with an SDH λ k associated with the variable T k defined as: . To model T 1 and T 2 and derive cumulative incidences, we introduce two parametric SDH functions and .
Likelihood and estimation
Longitudinal and survival parts are supposed to be linked as described in the following equation:
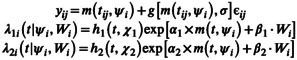 |
(2) |
where and are the baseline hazard functions for the risk of event 1 and the risk of event 2, and which depend on vectors of parameters χ 1 and χ 2, respectively. and are the coefficients that link the current predicted value of the marker with the instantaneous risks of event 1 and event 2, respectively. For the sake of clarity, we only considered a linear link between the longitudinal process and the subdistribution risks. Depending on the modeled data, more complex link functions could also be considered (e.g., involving splines or integration). W i is the optional vector of covariates with coefficient β 1 or β 2.
Both longitudinal and survival submodels are linked by shared random effects, and the joint likelihood writes:
| (3) |
where is the vector of parameters to estimate. p(y ij |η i , Z i ; θ) is the density function of longitudinal process, p(η i ; θ) the density function of random effects, and p(t, δ|η i ; θ) is the density function of the survival process given by:
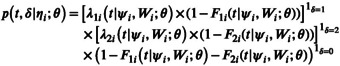 |
(4) |
where, for k = {1, 2}, is the individual cumulative incidence function for event k at time t.
The population parameter θ can be estimated by the maximization of the likelihood with the Stochastic Approximation Expectation Maximization (SAEM) algorithm implemented in Monolix (http://lixoft.com). This algorithm has been shown to be powerful, having good theoretical properties and accurately estimating parameters. 25 Variance–covariance matrix Σ of the population parameters is estimated with a stochastic approximation. 26 We note and their estimates.
Individual dynamic predictions
A popular application of joint models is to provide individual dynamic predictions for the biomarker evolution and for survival outcome(s). For a new patient i who has longitudinal observations until a landmark time l, , we aim at predicting his future marker value at time l + t, denoted m i (l + t|l), and his event 1 survival probability s i (l + t|l). The time t is called horizon time. Because dynamic predictions are applied to patients who are event free before time l, we focus on the conditional probability of not experiencing the event of interest expressed as:
| (5) |
Thus, for each landmark time l, the marker measurements of patient i up to time l and the information provided by the population parameters are used to compute the a posteriori distribution of the individual parameters and infer the desired quantities. But as the a posteriori distribution has no closed form, Markov chain simulation is needed. In particular, some authors 27 compared different software and computing methods to draw a posteriori values and showed that Monolix software and its Metropolis‐Hastings (MH) algorithm are able to provide those quantities with good properties. Then, the Monte Carlo process described in Rizopoulos 23 can be used to derive R samples of individual parameters. For a repetition r ∈ [1, R],
draw to take into account estimation uncertainty on population parameters
draw a realization of on the a posteriori distribution: and infer
compute and with .
Estimates of m i (l + t|l) and π i (l + t|l) are derived with
| (6) |
Prediction intervals can be derived by reporting the corresponding percentiles.
Performances are assessed in terms of discrimination with the time‐dependent receiver operating characteristic area under the curve (ROC AUC) 28 and calibration with the time‐dependent Brier score. 28 Details on the definition and computation of those indicators can be found in Supplementary Information S1.
Application framework
Data and objectives
Description of the data
The data are a subset of the OUTCOMEREA database composed of patients admitted in the ICU in 30 French centers between 1997 and 2015. Ethical and legal aspects of the database are described in Supplementary Information S2. In this application, we focus on patients included for sepsis or septic shock aged older than 18 years. Exclusion criteria were readmissions, admissions for palliative care, brain deaths, or early decisions not to forego life‐sustaining therapy. The patient set was randomly divided into two subsets to build a training data set composed of two thirds of the data and a validation data set composed of the remaining one third. Daily assessment of the sepsis‐related Sequential Organ Failure Assessment (SOFA) score was available for each patient stay. The SOFA score quantifies the number and the severity of organ dysfunctions between 0 (no organ dysfunction) and 24 (very severe organ dysfunctions). 29 , 30 , 31 This score is measured daily from ICU admission to discharge from ICU, but not after. ICU duration stay; status (alive/dead) at the end of the stay; and baseline covariates such as age, sex, and presence of comorbidities (e.g., diabetes, chronic heart failure, chronic kidney diseases, liver cirrhosis, chronic obstructive pulmonary diseases and immunocompromised status) were also available.
Objectives
The objective is to estimate jointly the individual SOFA score evolutions and the associated risk of ICU death and discharge within 30 days after ICU admission. It is worth noting that death and discharge are competing events because the occurrence of discharge precludes the possibility to observe the ICU death. It is also reasonable to presume that discharged patients do not have the same risk of death than other patients still hospitalized in the ICU. In this application, SOFA score evolution is modeled by a parametric NLMEM, death and discharge are modeled by a parametric competing risk subdistribution model with ICU death as the event of interest and discharge from ICU as the competing event. The added value of modeling the longitudinal evolution of the SOFA score is assessed by comparing prediction performances of a baseline model (model that only includes baseline SOFA measurement and other baseline covariates) versus the joint model.
Baseline and joint models
Baseline model
SDHs are parametric functions with a constant baseline hazard noted h 1 for the risk of death and h 2 for the risk of discharge. Both instantaneous risks include the baseline SOFA measurement. Covariate selection for age, sex, and number of comorbidities is based on Bayesian information criterion (BIC). All combinations are tested, and the one that minimizes the BIC is added in the baseline model. Briefly, the model writes:
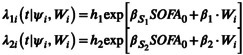 |
(7) |
Joint model
To allow monotonous or nonmonotonous evolution (e.g., initial increase of SOFA followed by a decrease or vice versa), the structural model m is defined as:
| (8) |
where ϕ is a capping function used to enforce the predicted SOFA score to remain between 0 and 24:
and we have:
The parameter t lag stands for the delay between symptom onset and the first SOFA evaluation. Details of coefficient interpretations can be found in Supplementary Information S3.
We used a combined error based on a model selection procedure using the BIC criteria. Thus, g[m(t ij , ψ i ), σ] = σ a + σ b × m(t ij , ψ i ), with σ = {σ a , σ b }. Details referring to error model selection are presented in Table S1 of the Supplementary Materials. In our joint model, the survival part includes baseline covariate(s) to model the dependence between prognosis and a patient's characteristics. In accordance with physicians, we made the hypothesis that the covariates only affect survival, for a given SOFA trajectory, and not the SOFA process itself. Therefore, it was not tested in the longitudinal submodel. Of note, exploring and testing various covariates on each of the five parameters of the structural model would require a careful handling of multiple testing issues.
SDHs are the same parametric functions as presented in the baseline model but including a coefficient linking the longitudinal process and the respective instantaneous risk.
We used Monolix 2018R2 with a maximum of 2000 iterations in the exploratory phase and in the stochastic approximation for both baseline and joint model estimations.
Details and help for readers on practical model implementation can be found in Supplementary Information S4.
Individual dynamic predictions
For both baseline and joint modeling, four landmark times are considered at 0, 3, 6, and 9 days after patient admission. Multiple horizon times are also considered, from landmark time plus 1 day to 30 days after admission.
To assess the performances of the models and according to the methods described, at a landmark time l and an horizon time t, a case is a patient who died in the ICU between l and l + t, and a control is a patient still hospitalized in the ICU or who was discharged between l and l + t. We note that, in our context, no censoring occurs between landmark and horizon times, and there is only an administrative censoring at 30 days. Thus, estimators of the AUC and Brier score in the absence of censoring presented in Supplementary Information S1 are used (Equations 2 and 4).
For the settings of the MH algorithm, we set one chain with three proposal functions that are used in turn: the population distribution, a unidimensional Gaussian random walk, or a multidimensional Gaussian random walk. For the random walks, the variance of the Gaussian is automatically adapted to reach an optimal acceptance ratio of 0.3. The algorithm stops when, for all parameters, the average conditional means and standard deviations of the last 50 iterations do not deviate by more than 5%.
Evaluation of the estimation performances by simulation
We conducted a simulation study to confirm that the SAEM algorithm implemented on Monolix 2018R2 provides good estimation performances of such a joint model. We assessed the estimation accuracy in terms of relative bias and evaluated the incertitude of estimation using relative root mean square errors (RRMSEs).
Simulation setting
We simulated M = 200 data sets of N = 1000 patients assuming that SOFA score measurements were available every day for at most 30 days after the ICU admission. SOFA measurements were reported for each patient until time of ICU death or ICU discharge or also end of the first 30 days of the stay, with no other censoring process.
The longitudinal data were simulated according to the model proposed in the application methods. Thus, this model is used:
| (9) |
with
For the survival part, we considered here two competing events and one categorical covariate W with three modalities. We adapted methods already described 32 , 33 to generate failure time data. The subdistribution for the event of interest is given by:
| (10) |
with λ(s) = exp(α 1 × m(ψ i , t ij ) + β 1 × W i ). Parameters p 1 and g 1 are used to control the number of event 1 at infinite time and the speed of onset. The subdistribution for the competing risk was then obtained using an exponential distribution with rate , where b controls the speed of event 2 onset:
| (11) |
Estimation setting
For each data set , we estimated the following joint model:
| (12) |
Estimation was performed by the maximization of the likelihood using the SAEM algorithm implemented on Monolix 2018 software with the same settings as explained in the application.
Evaluation criteria
We aimed to assess the performances of the estimation on a subset of the vector of parameters, the longitudinal parameters, and the survival parameters for the event of interest (death). We defined and its estimate. The model specification for data simulation does not allow α 2 and β 2 to be easily identified, which is why the estimation evaluation was based on vector . We evaluated the relative bias and the RRMSE of defined as:
| (13) |
We also provided violin plots of relative estimation errors (REE) defined for each data set as:
| (14) |
RESULTS
Data description
A total of 6046 patients were considered, with 4050 patients included in the training set and 1996 in the validation set. The data flowchart is detailed in Figure 1.
FIGURE 1.
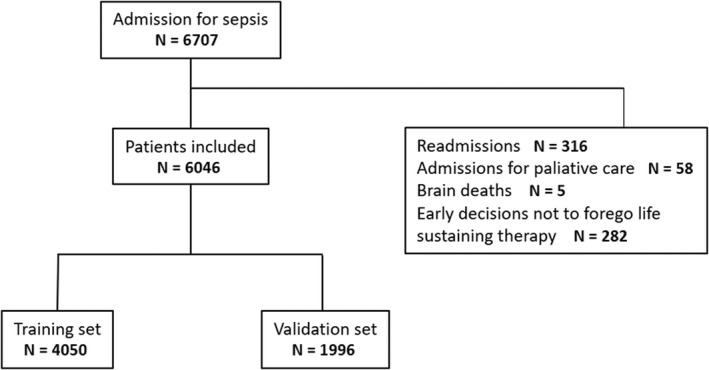
Data flowchart. A total of 6046 patients were included in the analysis, with 4050 in the training set and 1996 in the validation set.
Most of the patients were men (62%), and the median age at admission was 65.1 years ([Q1–Q3]: [52.7–76.2]). About half of the patients had no comorbidity at admission, one third had one, and one third had more than one. Median admission SOFA was 6 and 30 days after admission, about 19% of the patients died, whereas 72% were discharged. Table 1 summarizes the main patient characteristics at admission in both data sets.
TABLE 1.
Main patient characteristics at intensive care unit admission
| Variable | Training set | Validation set |
|---|---|---|
| (n = 4050) | (n = 1996) | |
| Age, years, n (%) | ||
| <60 | 1565 (39) | 782 (39) |
| [60, 75] | 1333 (33) | 682 (34) |
| 75 | 1152 (28) | 532 (27) |
| Sex, n (%) | ||
| Male | 2491 (61) | 1272 (64) |
| Female | 1559 (39) | 726 (36) |
| Comorbidities, n (%) | ||
| 0 | 1988 (49) | 985 (49) |
| 1 | 1340 (33) | 682 (34) |
| >1 | 722 (18) | 329 (17) |
| Admission SOFA, median [Q1–Q3] | 6 [4–9] | 6 [4–9] |
| 30‐day mortality, n (%) | 781 (19) | 362 (18) |
| 30‐day discharge, n (%) | 2921 (72) | 1426 (71) |
Abbreviation: SOFA, Sequential Organ Failure Assessment.
Figure 2a shows the longitudinal SOFA trajectories of 100 random patients of the training data set. Figure 2b shows the cumulative incidences of both competing events (death and discharge) on the training set, truncated at day 30.
FIGURE 2.
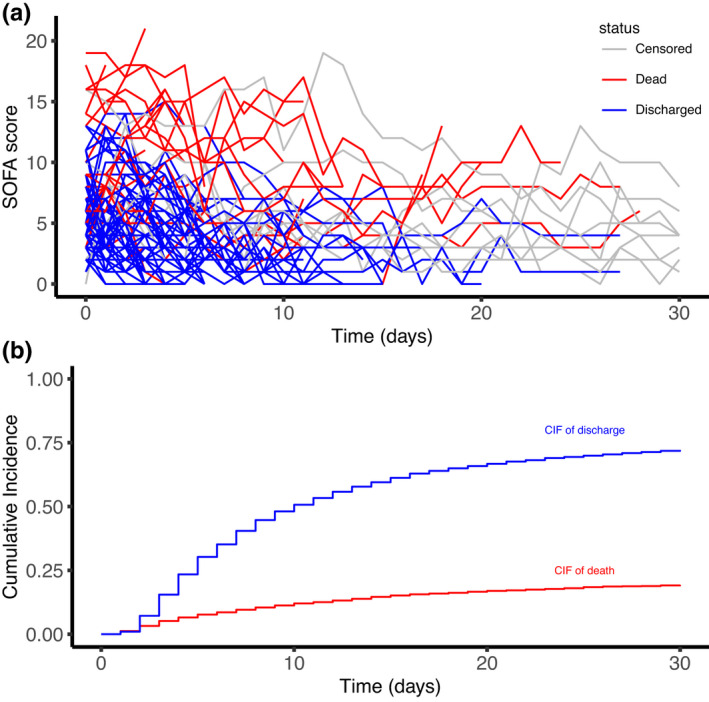
Exploratory plots of longitudinal and competing risk intensive care unit (ICU) data of the training set: (a) the Sequential Organ Failure Assessment (SOFA) score evolution of 100 random patients and (b) the cumulative incidences of ICU death and discharge from ICU (no censoring occurred during the follow‐up). CIF, cumulative incidence function.
Baseline model fit
The baseline model includes the baseline SOFA measurement and the patient age in three categories with cutoffs at 60 and 75 years (see Table S2 of the Supplementary Materials). The baseline SOFA already has a strong effect on the instantaneous risks of death and discharge: at a constant age category, a patient with a one‐point higher baseline SOFA has his instantaneous risk of death multiplied by 1.22 with a 95% confidence interval (CI) of [1.20, 1.24] and his instantaneous risk of discharge divided by 1.13 with a 95% CI of [1.12, 1.14]. Age also has an effect on both risks: for the same baseline SOFA, patients aged [60, 75[years have an instantaneous risk of death multiplied by 1.40 (with 95% CI: [1.18, 1.68]), and patients aged 75 years or older have their risk multiplied by 1.84 (with 95% CI: [1.55, 2.19]), compared with patients aged <60 years. For the risk of discharge from ICU, the effect is more moderate: patients aged [60, 75[years have an instantaneous risk of discharge divided by 1.23 (with 95% CI: [1.14, 1.35]), and patients aged 75 years or older have their risk divided by 1.30 (with 95% CI: [1.19, 1.43]). All parameter estimates can be found in Table S3 of the Supplementary Materials.
Joint model fit
The parameter estimates of the joint model can be found in Table 2.
TABLE 2.
Joint model parameter estimation
| Parameter | Value | SE | RSE (%) | p Value a | ||
|---|---|---|---|---|---|---|
| Longitudinal submodel | ||||||
| Fixed effects | ||||||
|
|
1.69 | 0.0547 | 3.23 | |||
|
|
−0.262 | 0.0051 | 1.93 | |||
|
|
−1.13 | 0.0188 | 1.66 | |||
|
|
10.4 | 0.135 | 1.29 | |||
|
|
−1.48 | 0.0286 | 1.94 | |||
| Random effects | ||||||
|
|
2.56 | 0.0424 | 1.66 | |||
|
|
0.194 | 0.00411 | 2.12 | |||
|
|
0.494 | 0.013 | 2.63 | |||
|
|
0.459 | 0.00962 | 2.10 | |||
|
|
0.669 | 0.02 | 3.00 | |||
| Error parameters | ||||||
|
|
0.887 | 0.0123 | 1.39 | |||
|
|
0.127 | 0.00265 | 2.08 | |||
| Survival submodel | ||||||
| Death | ||||||
|
|
0.000476 | 6.52 × 10−5 | 13.7 | |||
|
|
0.371 | 0.00788 | 2.12 |
|
||
|
|
0 | |||||
|
|
0.348 | 0.0876 | 25.1 |
|
||
|
|
0.766 | 0.119 | 15.6 |
|
||
| Discharge | ||||||
|
|
0.325 | 0.00901 | 2.77 | |||
|
|
−0.375 | 0.00768 | 2.05 |
|
||
|
|
0 | |||||
|
|
−0.195 | 0.0187 | 9.58 |
|
||
|
|
−0.225 | 0.0302 | 13.4 |
|
||
Abbreviation: RSE, relative standard error.
Wald test p values are reported for link and covariate coefficients.
The parameters are those from (8).
The p values from the Wald test are reported for the link coefficients and those associated with covariate effects. As expected, we showed a significant association between an increase of the SOFA score and a higher risk of death (α 1 = 0.371 with 95% CI: [0.356, 0.386]) and a lower risk of discharge (α 2 = −0.375 with 95% CI: [−0.390, −0.360]). We also reported the significant effect of age class on both death and discharge risk. Age has a more important impact on the risk of death, similar to the baseline model: for the same SOFA evolution, patients aged [60, 75[years have an instantaneous risk of death multiplied by 1.42 (with 95% CI: [1.20, 1.68]), and patients aged 75 years or older have their risk multiplied by 2.15 (with 95% CI: [1.70, 2.72]), compared with the reference class age (<60 years).
Some diagnostic plots and indicators that assessed the quality of the longitudinal model and the joint model, respectively, can be found in Supplementary Information S5.
Dynamic predictions
Figure 3 illustrates dynamic predictions for two patients (a and b) of the validation set using the joint model. It shows the observed and predicted SOFA evolution on the top and predicted individual survival probability on the bottom, depending on landmark time. Predicted SOFA evolution and predicted survival are updated at each landmark time. Patient a of the figure shows an initial clinical deterioration, followed by an improvement of his clinical state. The more landmark time increases, better is his predicted survival. The SOFA score of Patient b monotonously increases over time, resulting in his predicted survival at 30 days getting worse as the landmark increases. He finally died on Day 26.
FIGURE 3.
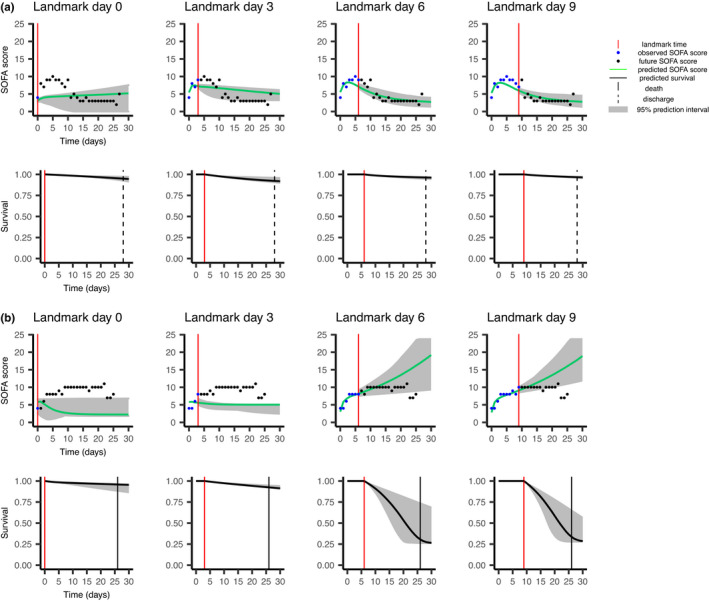
Dynamic predictions for two random patients (a and b) of the validation data set. For each patient, predictions of the Sequential Organ Failure Assessment (SOFA) evolution are on the top, and predictions of the risk of death are on the bottom. Patient a, who is older than 75 years, was discharged 28 days after his intensive care unit admission, whereas Patient b, also older than 75 years, died 26 days after his admission.
To visualize the covariate effect on predictions, in Supplementary Information S6 we added the median [Q1–Q3] survival predictions in the validation population for the three age categories and for baseline SOFA splits in three categories for various landmark times.
To assess the predictive performances of the baseline and joint models, we used the 1996 patients of the validation set. Time‐dependent ROC AUC and the Brier score including 95% CIs within the joint model are presented in Figure 4. The ones for the baseline model are presented in Figure S1 of the Supplementary Materials. The joint modeling approach allows to improve the quality of prediction when the follow‐up is sufficient. For instance, when considering landmark time = 6 and horizon time = 30, AUC = 0.63 (95% CI: [0.58, 0.68]) and AUC = 0.77 (95% CI: [0.74, 0.80]) for the baseline and the joint model, respectively. However, when considering an early landmark where only one SOFA observation is available, the joint model does not perform better than the baseline model (for landmark time = 0 and horizon time = 30, AUC = 0.73, 95% CI = [0.70, 0.77] and AUC = 0.69 with 95% CI = [0.66, 0.72] for the baseline and joint models, respectively).
FIGURE 4.
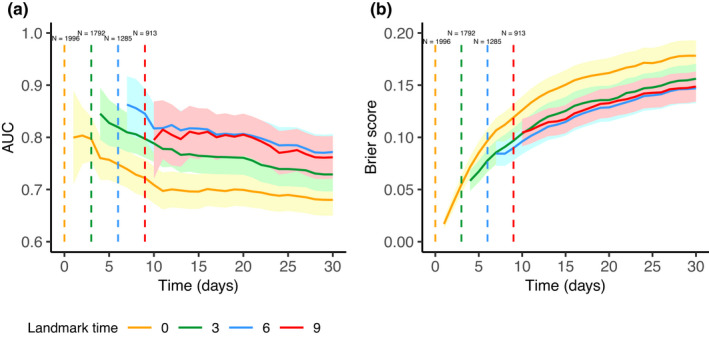
Time‐dependent receiver operating characteristic area under the curve (ROC AUC) (a) and Brier score (b) computed on the validation set depending on landmark time. The 95% confidence intervals are represented by the corresponding colored intervals. Number of at‐risk patients at each landmark time is specified on the top.
Results of the simulation study
Values of parameters (except p 1, g 1 and b) used to simulate data were based on estimates obtained by maximization of the likelihood using this model on the OUTCOMEREA database presented previously. The details of the values can be found in Table 3. p 1, g 1 were set to 0.01, 0.05, respectively, and b was fixed to 6 to obtain about 20% Cause 1 failures, 78% Cause 2 failures, and 2% administrative censoring at time 30, similar to the application.
TABLE 3.
Estimated relative bias and root mean square errors based on 200 simulations
| Parameter | True value | Relative bias (%) | RRMSE (%) | |
|---|---|---|---|---|
| Longitudinal part | ||||
| Fixed effects | ||||
|
|
2 | 2 | 11 | |
|
|
−0.25 | 5 | 10 | |
|
|
−1 | 4 | 8 | |
|
|
10 | −0.06 | 5 | |
|
|
−1 | 6 | 12 | |
| Random effects | ||||
|
|
3 | 6 | 9 | |
|
|
0.2 | 15 | 18 | |
|
|
0.5 | −0.5 | 13 | |
|
|
0.5 | −14 | 16 | |
|
|
0.8 | 6 | 11 | |
| Error parameters | ||||
|
|
0.9 | −0.3 | 2 | |
|
|
0.1 | 3 | 5 | |
| Survival part | ||||
|
|
0.35 | 2 | 9 | |
|
|
0.34 | −12 | 85 | |
|
|
0.76 | 7 | 39 | |
Abbreviation: RRMSE, relative root mean square error.
The parameters are those from (12).
Table 3 provides the relative biases and RRMSEs expressed in percentage. Relative biases are low for all parameters, which reflects good accuracy. The parameter that links the longitudinal and the survival process (α 1) was of particular interest. The simulation showed that it is accurately estimated with a relative bias of about 2% and also precisely estimated with a RRMSE about 9%. Overall, the parameters are precisely estimated except parameters associated with the baseline covariate, which have high RRMSEs.
Violin plots can be found in Figure S2A of the Supplementary Materials and provide the same conclusion.
DISCUSSION
In many biomedical applications, the patients are not only at risk of a single event, but of several. Joint modeling under competing risks is seldom explored, particularly in a full parametric setting.
In our application, a significant association was found between the longitudinal evolution of the SOFA and each outcome (death and discharge): an increase of the SOFA score is associated with a higher risk of death and a lower risk of discharge. In the joint model, higher uncertainty was found in the estimates of the baseline age effect when adjusted on the SOFA evolution. Of note, simulations according to the baseline model (see Figure S2B of the Supplementary Materials), which is adjusted on the baseline SOFA value, also reported the same trend: high uncertainty in the estimates of the baseline age effect, which highlights the difficulty in estimating age effect when the SOFA score is in the model.
For landmark time 3 and more, as sufficient information becomes available, individual predictions from the joint model are significantly improved and outperform those from the baseline model. At landmark time 0, no added value of the joint model was shown as there is no longitudinal information available. Individual predictions at any landmark time, using all available SOFA scores at that time, can be very useful for clinicians in routine medical practice as it may help clinical decisions such as therapeutic escalation or limitation, as indeed those decisions arise during the follow‐up and not at admission.
The proposed joint model could probably be improved on some points. First, we could test for the covariate effects in the parameters of the longitudinal submodel. Second, we did not assess graphically the quality of the survival model fit because usual diagnostic plots are, to date, unavailable for this kind of model. This is because these plots rely on simulations, which are currently not available for SDH formulation and would require additional developments that are beyond the scope of this article. Finally, we considered the subdistribution approach to treat the competing risk setting, and sensitivity analyses can be done with a cause‐specific approach.
Our approach with joint modeling is justified when missing data for the longitudinal biomarker are MNAR. However, depending of the richness of the design, missing data can be considered missing at random (MAR), and some authors 34 showed that treating MAR data with a joint modeling approach can lead to bias in estimates.
The simulation study showed that our estimation procedure has good statistical properties with no major bias in longitudinal parameters and in the coefficient that links the longitudinal process with the survival process. However, we cannot evaluate the bias on event 2 because of the model specification in the simulation process. Further developments are thus needed to fully investigate the quality of estimation on both events as well as the type I error and power of statistical tests involving the coefficients.
In conclusion, we showed in this work that Monolix software and its SAEM algorithm can be used for joint modeling with competing events and provide accurate parameter estimates. We also presented a real‐case application with dynamic predictions. The methodology is easy to reproduce and can be easily extended to other clinical applications because of the general form of the model. The longitudinal model can also be extended to ordinary differential equations in a more pharmacometric application.
AUTHOR CONTRIBUTIONS
A.L.‐M. wrote the manuscript. J.‐F.T., F.M., and J.M. designed the research. A.L.‐M. and J.M. performed the research. A.L.‐M. analyzed the data.
FUNDING INFORMATION
Dr. Timsit was supported by the Innovative Medicines Initiative under grant agreement no. 115737‐2–COMBACTE‐MAGNET.
CONFLICT OF INTEREST
The authors declared no competing interests for this work. As Editor‐in‐Chief of CPT: Pharmacometrics & Systems Pharmacology, France Mentre was not involved in the review or decision process for this paper.
Supporting information
Supplementary Information S1
Supplementary Information S2
Supplementary Information S3
Supplementary Information S4
Supplementary Information S5
Supplementary Information S6
Supplementary Information S7
Supplementary Information S8
Supplementary Information S9
Supplementary Information S10
Supplementary Information S11
Supplementary Information S12
ACKNOWLEDGMENTS
The members of the OUTCOMEREA network are detailed in Supplementary Information S7.
Lavalley‐Morelle A, Timsit J‐F, Mentré F, Mullaert J, The OUTCOMEREA network . Joint modeling under competing risks: Application to survival prediction in patients admitted in Intensive Care Unit for sepsis with daily Sequential Organ Failure Assessment score assessments. CPT Pharmacometrics Syst Pharmacol. 2022;11:1472‐1484. doi: 10.1002/psp4.12856
REFERENCES
- 1. Desmée S, Mentré F, Veyrat‐Follet C, et al. Nonlinear joint models for individual dynamic prediction of risk of death using Hamiltonian Monte Carlo: application to metastatic prostate cancer. BMC Med Res Methodol. 2017;17(1):105. doi: 10.1208/s12248-015-9745-5 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Musoro JZ, Zwinderman AH, Abu‐Hanna A, Bosman R, Geskus RB. Dynamic prediction of mortality among patients in intensive care using the sequential organ failure assessment (SOFA) score: a joint competing risk survival and longitudinal modeling approach. Stat Neerl. 2018;72(1):34‐47. doi: 10.11111/stan.12114 [DOI] [Google Scholar]
- 3. Ferrer L, Putter H, Proust‐Lima C. Individual dynamic predictions using landmarking and joint modelling: validation of estimators and robustness assessment. Stat Methods Med Res. 2019;28(12):3649‐3666. [DOI] [PubMed] [Google Scholar]
- 4. Kerioui M, Mercier F, Bertrand J, et al. Bayesian inference using Hamiltonian Monte‐Carlo algorithm for nonlinear joint modeling in the context of cancer immunotherapy. Stat Med. 2020;39(30):4853‐4868. [DOI] [PubMed] [Google Scholar]
- 5. Latouche A, Porcher R, Chevret S. Note on including time‐dependent covariate in regression model for competing risks data. Biom J. 2005;47(6):807‐814. [DOI] [PubMed] [Google Scholar]
- 6. Rizopoulos D. Joint Models for Longitudinal and Time‐to‐Event Data: With Applications in R. Chapman & Hall/CRC; 2012. [Google Scholar]
- 7. Saha C, Jones MP. Asymptotic bias in the linear mixed effects model under non‐ignorable missing data mechanisms. J R Stat Soc Series B Stat Methodol. 2005;67(1):167‐182. [Google Scholar]
- 8. Zhudenkov K, Gavrilov S, Sofronova A, et al. A workflow for the joint modeling of longitudinal and event data in the development of therapeutics: tools, statistical methods, and diagnostics. CPT Pharmacometrics Syst Pharmacol. 2022;11(4):425‐437. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 9. Prentice RL, Kalbfleisch JD, Peterson AV, et al. The analysis of failure times in the presence of competing risks. Biometrics. 1978;34(4):541‐554. [PubMed] [Google Scholar]
- 10. Fine JP, Gray RJ. A proportional hazards model for the subdistribution of a competing risk. J Am Stat Assoc. 1999;94(446):496‐509. [Google Scholar]
- 11. Putter H, Fiocco M, Geskus RB. Tutorial in biostatistics: competing risks and multi‐state models. Stat Med. 2007;26(11):2389‐2430. doi: 10.1002/sim.2712 [DOI] [PubMed] [Google Scholar]
- 12. Lau B, Cole S, Gange S. Competing risk regression models for epidemiologic data. Am J Epidemiol. 2009;170(2):244‐256. doi: 10.1093/aje/kwp107 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Grambauer N, Schumacher M, Beyersmann J. Proportional subdistribution hazards modeling offers a summary analysis, even if misspecified. Stat Med. 2010;29(7–8):875‐884. [DOI] [PubMed] [Google Scholar]
- 14. Proust‐Lima C, Dartigues JF, Jacqmin‐Gadda H. Joint modeling of repeated multivariate cognitive measures and competing risks of dementia and death: a latent process and latent class approach. Stat Med. 2016;35(3):382‐398. [DOI] [PubMed] [Google Scholar]
- 15. Andrinopoulou ER, Rizopoulos D, Takkenberg JJ, et al. Combined dynamic predictions using joint models of two longitudinal outcomes and competing risk data. Stat Methods Med Res. 2017;26(4):1787‐1801. [DOI] [PubMed] [Google Scholar]
- 16. Rué M, Andrinopoulou ER, Alvares D, Armero C, Forte A, Blanch L. Bayesian joint modeling of bivariate longitudinal and competing risks data: an application to study patient‐ventilator asynchronies in critical care patients. Biome J. 2017;59(6):1184‐1203. [DOI] [PubMed] [Google Scholar]
- 17. Sweeting MJ, Thompson SG. Joint modelling of longitudinal and time‐to‐event data with application to predicting abdominal aortic aneurysm growth and rupture. Biom J. 2011;53(5):750‐763. doi: 10.1002/bimj.201100052 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 18. Baghfalaki T, Ganjali MA. Bayesian approach for joint modeling of skew‐normal longitudinal measurements and time to event data. Revstat. 2015;13(2):169‐191. [Google Scholar]
- 19. Borges A, Sousa I, and Castro L. Joint modelling of longitudinal CEA tumour marker progression and survival data on breast cancer. AIP Conf Proc 2017; 1836 (1):020043. [Google Scholar]
- 20. Tardivon C, Desmée S, Kerioui M, et al. Association between tumor size kinetics and survival in patients with urothelial carcinoma treated with Atezolizumab: implication for patient follow‐up. Clin Pharmacol Ther. 2019;106(4):810‐820. doi: 10.1002/cpt.1450 [DOI] [PubMed] [Google Scholar]
- 21. van Niekerk J, Bakka H, Rue H. Competing risks joint models using R‐INLA. Stat Model. 2021;21(1‐2):56‐71. [Google Scholar]
- 22. Krishnan S, Friberg L, Bruno R, Beyer U, Jin JY, Karlsson MO. Multistate model for Pharmacometric analyses of overall survival in HER2‐negative breast cancer patients treated with docetaxel. CPT Pharmacometrics Syst Pharmacol. 2021;10(10):1255‐1266. doi: 10.1002/PSP4.12693 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 23. Rizopoulos D. Dynamic predictions and prospective accuracy in JointModels for longitudinal and time‐to‐event data. Biometrics. 2011;67(3):819‐829. [DOI] [PubMed] [Google Scholar]
- 24. Soo A, Zuege DJ, Fick GH, et al. Describing organ dysfunction in the intensive care unit: a cohort study of 20,000 patients. Crit Care. 2019;23(1):186. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 25. Delyon B, Lavielle M, Moulines EJ. Convergence of a stochastic approximation version of EM algorithm. Ann Stat. 1999;27(1):94‐128. [Google Scholar]
- 26. Kuhn E, Lavielle M. Maximum likelihood estimation in nonlinear mixed effects model. Comput Stat Data Anal. 2005;49:1020‐1038. [Google Scholar]
- 27. Riglet F, Mentre F, Veyrat‐Follet C, Bertrand J. Bayesian individual dynamic predictions with uncertainty of longitudinal biomarkers and risks of survival events in a joint modelling framework: a comparison between Stan, Monolix, and NONMEM. AAPS J. 2020;22(2):50. [DOI] [PubMed] [Google Scholar]
- 28. Blanche P, Proust‐Lima C, Loubère L, Berr C, Dartigues JF, Jacqmin‐Gadda H. Quantifying and comparing dynamic predictive accuracy of joint models for longitudinal marker and time‐to‐event in presence of censoring and competing risks. Biometrics. 2015;71(1):102‐113. [DOI] [PubMed] [Google Scholar]
- 29. Vincent JL, Moreno R, Takala J, et al. The SOFA (sepsis‐related organ failure assessment) score to describe organ dysfunction/failure. Intensive Care Med. 1996;22(7):707‐710. [DOI] [PubMed] [Google Scholar]
- 30. Vincent JL, de Mendonça A, Cantraine F, et al. Use of the SOFA score to assess the incidence of organ dysfunction/failure in intensive care units: results of a multicenter, prospective study. Working group on “sepsis‐related problems” of the European Society of Intensive Care Medicine. Crit Care Med. 1998;26(11):1793‐1800. [DOI] [PubMed] [Google Scholar]
- 31. Timsit JF, Fosse JP, Troché G, et al. Calibration and discrimination by daily logistic organ dysfunction scoring comparatively with daily sequential organ failure assessment scoring for predicting hospital mortality in critically ill patients. Crit Care Med. 2002;30(9):2003‐2013. [DOI] [PubMed] [Google Scholar]
- 32. Fine JP. Regression modeling of competing crude failure probabilities. Biostatistics. 2001;2(1):85‐97. [DOI] [PubMed] [Google Scholar]
- 33. Deslandes E, Chevret S. Joint modeling of multivariate longitudinal data and the dropout process in a competing risk setting: application to ICU data. BMC Med Res Methodol. 2010;10:69. [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. Thomadakis C, Meligkotsidou L, Pantazis N, Touloumi G. Longitudinal and time‐to‐drop‐out joint models can lead to seriously biased estimates when the drop‐out mechanism is at random. Biometrics. 2019;75(1):58‐68. [DOI] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Supplementary Information S1
Supplementary Information S2
Supplementary Information S3
Supplementary Information S4
Supplementary Information S5
Supplementary Information S6
Supplementary Information S7
Supplementary Information S8
Supplementary Information S9
Supplementary Information S10
Supplementary Information S11
Supplementary Information S12