

Abstract
It has been proven that three‐dimensional protein structures could be modeled by supplementing homologous sequences with metagenome sequences. Even though a large volume of metagenome data is utilized for such purposes, a significant proportion of proteins remain unsolved. In this review, we focus on identifying ecological and evolutionary patterns in metagenome data, decoding the complicated relationships of these patterns with protein structures, and investigating how these patterns can be effectively used to improve protein structure prediction. First, we proposed the metagenome utilization efficiency and marginal effect model to quantify the divergent distribution of homologous sequences for the protein family. Second, we proposed that the targeted approach effectively identifies homologous sequences from specified biomes compared with the untargeted approach's blind search. Finally, we determined the lower bound for metagenome data required for predicting all the protein structures in the Pfam database and showed that the present metagenome data is insufficient for this purpose. In summary, we discovered ecological and evolutionary patterns in the metagenome data that may be used to predict protein structures effectively. The targeted approach is promising in terms of effectively extracting homologous sequences and predicting protein structures using these patterns.
Keywords: ecology, evolution, metagenome data, protein 3D structure modeling, targeted approach
For protein 3D structure prediction, we mine the data‐dependent ecological and evolutionary trends hidden in metagenome data. Based on this pattern, the targeted approach was presented to predict the protein 3D structure more effectively and accurately than the untargeted approach's blind search.
Highlights
Metagenome benefits for homologous sequence supplement for protein three‐dimensional (3D) structure prediction.
Metagenome utilization efficiency shows a divergent distribution of proteins.
Marginal effect model also quantifies this divergent distribution of proteins.
For mining homologous sequences, the targeted approach outperforms the untargeted approach.
Current metagenome data is not enough for modeling 3D structures for all proteins.
INTRODUCTION
It has been proven feasible that protein three‐dimensional (3D) structures could be modeled with the supplement of metagenome sequences as homologous sequences. However, although a large amount of metagenome data is used for such purposes, a considerable number of proteins could still not be modeled. Such phenomenon has attracted our attention: is there any metagenome data‐dependent patterns behind, what are the intricate but potentially important properties about protein structures that lead to such patterns, and how to best utilize such properties for better protein structure prediction. More importantly, it was suspected that the reason behind this is tightly related to the ecological and evolutionary patterns of the metagenome sequence utilization based on different niches (i.e., biomes).
Here we focused on the divergent distribution of homologous sequences for protein families in the different metagenome and conducted a biome‐aware assessment for different performances of metagenome‐based protein 3D structure prediction methods. Firstly, to detect the divergent distribution of homologous sequences in the metagenome from different biomes, metagenome utilization efficiency is proposed, which is defined as the proportion of aligned homologous sequences in all metagenome sequences. The analysis of utilization efficiency on the ecological and evolutionary perspective shows a biome‐dependent homologous sequences distribution for a protein family. Secondly, as a model to illustrate the different potential of metagenome data from different biomes in supplementing the homologous sequences for protein structure modeling, the marginal effect model could also quantify this divergent distribution. Thirdly, constructed based on this pattern, the targeted approach could find enough homologous sequences from targeted biomes rather than the blind search used in the untargeted approach. The benchmark result shows that the targeted approach needs much fewer metagenome sequences and results in a more precise model compared to the untargeted approach. Finally, the lower bounds for metagenome data needed for protein structure prediction have been estimated and the results show that current metagenome data (roughly 1.48E12 metagenome sequences) is still far from enough for reliable protein structure prediction (roughly 7.12E12 metagenome sequences). And the targeted approach would partially overcome this challenge by lowering this bound to around 4.32E12 metagenome sequences due to higher utilization efficiency.
Collectively, our assessment of the utilization efficiency and the marginal effect has revealed strong ecological and evolutionary patterns behind the metagenome data for effective protein structure prediction. Utilizing these patterns, the targeted approach is promising in reliably excavating homologous sequences and predicting protein structures.
PROTEIN 3D STRUCTURE PREDICTION
It has always been fascinating how proteins, in their native structures, could function in a species [1, 2, 3], leading to the central topic of how protein structure is associated with protein functions. Modeling the 3D structure of proteins is a computer method for better understanding this important subject [4, 5]. A major challenge, however, is that the number of ways a protein could theoretically fold before settling into its final 3D structure is astronomical [6, 7, 8, 9]. However, proteins fold spontaneously in nature, some within milliseconds—a dichotomy sometimes referred to as Levinthal's paradox [10, 11]. These findings may allow for more accurate drug development efforts, complementing existing experimental approaches to uncover potential therapies more quickly [12, 13]. Furthermore, some published tools offer the ability to investigate the hundreds of millions of proteins for which we presently lack models—a big territory of undiscovered biology [14, 15, 16]. There may be proteins with novel and intriguing functions among the unsolved proteins, much as a telescope allows us to view deeper into the undiscovered cosmos [17, 18, 19].
Determination of protein 3D structure is usually conducted by wet‐lab experiments [20, 21, 22]. X‐ray crystallography, nuclear magnetic resonance spectroscopy, and electron microscopy are some of the technologies now utilized to identify the structure of a protein [23, 24, 25]. To develop the final atomic model, the scientist employs several bits of information in each of these methods [26, 27]. However, because experimental approaches are often slow and arduous, thus for many proteins, computational methods are usually employed to determine, or more precisely predict, the protein 3D structures, with varying resolutions [26, 28, 29].
TEMPLATE‐FREE PROTEIN 3D STRUCTURE PREDICTION
Protein 3D structures are usually predicted through two approaches: template‐based and template‐free [5, 30, 31]. Template‐based protein structure prediction (also known as homology or comparative modeling) employs knowledge of solved structures to model the native or true fold of a protein sequence [32, 33, 34]. Template‐based protein structure prediction has long been thought to have tremendous potential for producing atomically precise models that are close to the native conformation [35, 36]. However, because the template‐based method is strongly reliant on an existing solved structure, it can only be used for a restricted number of proteins [37, 38].
Template‐free methods are currently big‐data‐driven methods that are based on homologous protein sequences and multiple sequence alignment (MSA) to predict protein structures without any known template [39, 40, 41]. The template‐free method relies on a large amount of high‐quality homologous sequences to make accurate predictions [14, 42, 43]. Currently, several representative template‐free methods are widely used for protein 3D structure prediction, including Rosetta [42], Iterative Threading ASSEmbly Refinement (I‐TASSER) [5], and AlphaFold [44]. Rosetta [42] is a long‐standing software system for predicting protein structure well‐known for its versatile functionalities and diverse applications [45, 46, 47]. I‐TASSER is also a long‐standing software system for protein structure prediction [5]. Empowered by deep learning methods, I‐TASSER performs well in the field of template‐free protein structure prediction [48, 49]. Most importantly, recent AlphaFold predicted extremely high‐accuracy structures for 87 out of 92 domains in the CASP14, outperforming other methods [44, 50, 51]. All these template‐free tools' achievements rely substantially on homologous sequences, implying that homologous sequences are crucial for template‐free protein 3D structure prediction [16, 52, 53].
In summary, template‐free methods are currently commonplace in protein structure prediction, and several template‐free methods are utilized to predict huge batches of proteins. On the one hand, deep learning techniques have made it possible for template‐free methods to predict protein structures at unprecedented speed and accuracy. On the other hand, template‐free methods are usually dependent on homologous sequences of the proteins, which should be plentiful and diverse within themselves. And these requirements for homologous sequences have resulted in the formation of a huddle for template‐free protein 3D structure prediction.
CURRENT PROBLEMS FOR TEMPLATE‐FREE PROTEIN 3D STRUCTURE PREDICTION
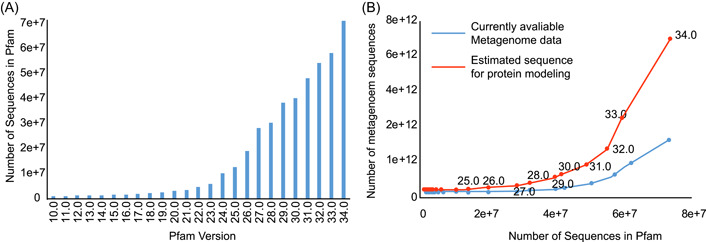
Everything has two or multiple sides, protein 3D structure prediction is not an exception [54, 55, 56]. On one side, current methods, particularly AlphaFold, have already enabled the accurate structure prediction across more than 365,198 proteins for 21 species, resulting in an average coverage of 80.45% for all the proteins in reference proteome, including nearly all proteins (coverage over 99%) in six species [57]. On the other side, many proteins, including those in the Pfam database, have unknown 3D structures, and this number is also soaring rapidly [58, 59, 60]. In Pfam 26.0, only 2% of proteins lack structural information, but in Pfam 34.0, more than 50% of proteins do not have structural information (Figure 1). This phenome would be due to the contradiction between the advanced sequencing technology to find out more novel proteins and the limited development of wet experiment technology or the limited homologous sequences to identify their 3D structures [38, 61, 62].
Figure 1.
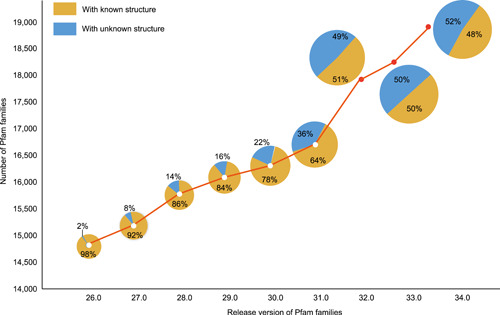
The number of Pfam families under release version changes up till Pfam version 34.0. The curve illustrates the number of Pfam families ranged by the release version. The pie charts attached to the corresponding release version reflect the proportion of Pfam families with known and unknown structures
These facts have resulted in an ostensibly but sensible trend: While the structures of more and more proteins are being predicted with increasing precision, there are also more and more proteins emerged that have no structure. This is rational because more and more species have been sequenced, leading to more and more proteins. As most of these are novel proteins, their protein 3D structures are not readily available. Faced with the increasing number of novel proteins, there is an urgent need to effectively find all available homologous sequences for template‐free protein 3D structure prediction.
PREDICTION OF PROTEIN 3D STRUCTURE USING METAGENOME SEQUENCES
One possible solution for the prediction of no known protein structure problem is by means of using metagenome sequence data to supplement the homologous sequence [63, 64, 65, 66]: As a big reservoir of functional genes, metagenome could supply a considerable amount of homologous sequences for proteins [67, 68, 69]. Combined with more homologous information and an advanced template‐free prediction pipeline, many proteins with unsolved structures would be modeled with reliable structures. However, regardless of the protein structure prediction technique used, “more sequences lead to more protein structure predictions” is not true in most circumstances [63, 64]. Using over two billion proteins from different metagenome samples (mostly from the Gut microbiome), Baker et al. [63] could predict protein structures for 614 proteins with unknown structures in the Pfam database. While by only utilizing 97 million proteins from Ocean metagenome data, Zhang et al. [64] could predict protein structures for 27 proteins that cannot be solved in Baker et al.'s work. Most recently, by using 4.25 billion microbiome sequences from four biomes (Gut, Lake, Soil, Fermentor), Yang et al. [70] could predict protein structures for 1044 proteins in the Pfam database. All these findings suggested that metagenome sequences could supplement homologous sequences for protein 3D structure prediction and that this supplement has a significant biome‐related divergence.
Thus, two questions are obvious: what means we can utilize metagenome data for protein structure prediction? And how much metagenome data is needed for protein structure prediction? For both questions, the key objectives lay ahead: effective homologous sequence supplement. It would be vital to investigate what factors have affected the process of prediction of protein structure from metagenome data and find ways to best utilize these metagenome data properties to discover protein 3D structures for more proteins. To answer these critical questions, we have examined the data‐dependent patterns behind the metagenome data, from the ecological and evolutionary perspectives aspects (Figure 2). Using the successfully modeled proteins supplemented by metagenome data with unsolved structures in the Pfam database as a benchmark data set, we would investigate their evolutionary patterns (number of homologous sequences; protein function) and the ecological patterns (the enrichment patterns of source species and metagenome niche).
Figure 2.
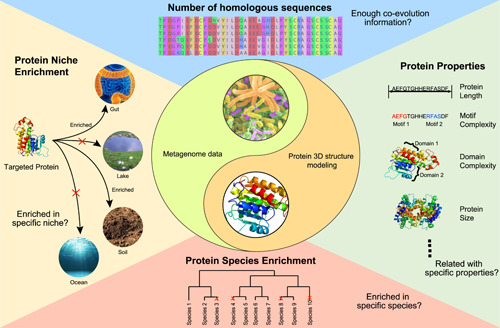
Examining the data‐dependent ecological and evolutionary patterns behind the metagenome data from multiple aspects. To examine the correlation between metagenome and proteins in Pfam, evolutionary patterns, including the number of homologous sequences and protein properties, would be investigated. Moreover, the ecological patterns, including the enrichment patterns of source species and metagenome niche, would also be investigated
ESTIMATION OF THE METAGENOME UTILIZATION EFFICIENCY
With the explosive growth of microbiome data, searching homologous sequences in metagenome for protein requires a huge search space and a significant amount of time [71, 72, 73]. As a result, metagenome utilization efficiency is the key to the successful prediction of protein structure from metagenome data. “Metagenome utilization efficiency” is defined as the proportion of homologous sequences that could be used for MSA supplement, among all sequences examined. Apparently, a greater metagenome utilization value showed that employing metagenome data for protein structure prediction was more successful. It was also clear how to boost metagenome utilization: either increase the number of homologous sequences that might be utilized for MSA supplementation or limit the protein sequence search space. In this review, the effectiveness of using metagenomes from diverse biomes to complement homologous sequences was assessed (Figure 3).
Figure 3.
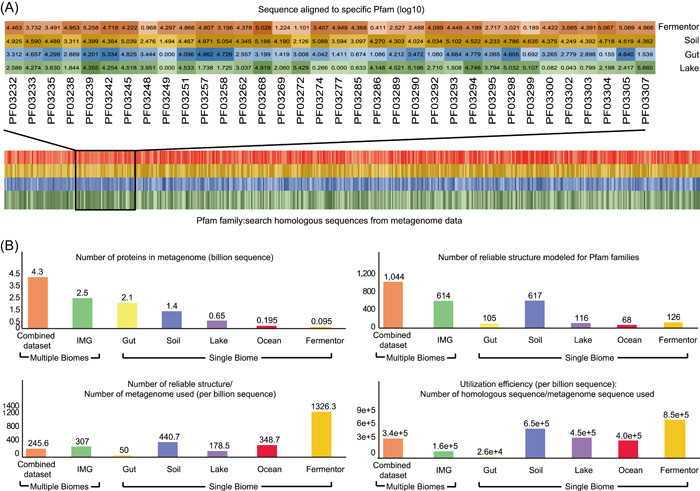
Metagenome sequence utilization efficiency evaluation. (A) Supplemented by the metagenome data set from different biomes, the homologous sequences were aligned to all the Pfam families, exemplified by metagenome from four biomes. Different color means their source biome and the shade of the color represents the number of metagenome sequences aligned to the corresponding Pfam families (the darker, more sequences aligned). (B) After homologous sequences aligned, the number of Pfam families predicted with reliable structures was calculated. Averagely, after using metagenome sequences (billion sequences), the number of homologous sequences aligned, and reliable structure modeled were calculated. Then, the metagenome sequence utilization efficiency was evaluated by calculating the proportion of the number of Pfam families in the number of metagenome sequences and the proportion of the number of supplemented homologous sequences in all the metagenome sequences
First, the homologous sequences of all the Pfam families are searched against metagenome from different biomes to evaluate the utilization efficiency (Figure 3A), which has been utilized to model the reliable structures for Pfam families (Gut, Soil, Lake, Fermentor and combined four data set [70], multiple biomes from IMG database [63] and Ocean [64]). Then using per billion metagenome sequences, the number of reliable proteins structures modeled and the number of supplemented homologous sequences was calculated (Figure 3B). For combined data set from four biomes (Soil, Lake, Fermentor, and Gut), highly reliable folds were modeled for 1044 Pfam families supplemented by 4.25 billion metagenome sequences, accounting for 12.00% of 8700 Pfam families with unsolved structures, higher than those in previous works [63, 64] and one of the four biomes [70]. However, utilizing the combined data set has not been demonstrated to be more efficient. Using the soil biome as the representation of a single biome, 9.1e+5 homologous sequences were detected, and the utilization efficiency would be calculated as 6.5e+5 per billion metagenome sequences (9.1e+5 homologous sequences/1.4 billion of sequencing data used). However, for the combined data set, though 14.6e+5 homologous sequences were detected, the utilization efficiency was only 3.4e+5 per billion metagenome sequence (14.6e+5 homologous sequences/4.3 billion of sequencing data used), much lower than those based on a single biome. The same result would be also deduced when using the IMG database, which includes multiple biomes, than single biomes (Figure 3B). This utilization efficiency analysis shows that if we have targeted the source biomes for the specific protein families, then protein sequences from single biomes considered in this study are significantly more efficiently used than using the data from different biomes.
Taken together, the efficiency of metagenome utilization is extremely biome‐dependent on a global view. Under particular environmental stresses in a given niche (i.e., biome), some genes may evolve so that the host species could better adapt to the environment, according to the ecological perspective on gene or protein evolution. Point mutations or gene structural variations might develop during this process and accumulate throughout generations of species [70, 74, 75]. As a result, we could frequently find a collection of homologous sequences for one protein under one biome. These proteins would aid the host's survival. Hence, choosing the proper biome for a single protein will greatly increase metagenome utilization and give a hint to derive the protein function for its host.
MARGINAL EFFECT FOR PROTEIN STRUCTURE PREDICTION
The term “marginal effect” generally refers to a data set's ability to solve a certain problem [76, 77, 78]. In the context of protein structure prediction, the “marginal effect” ME (B i, P j) is defined as the potential of metagenome data from a given biome B i in supplementing homologous sequences for a certain protein P j. The higher marginal effect usually indicated higher utilization efficiency if we use metagenome data from biome B i for supplementing homologous sequences for protein P j. Exemplified by PF12652, estimated by marginal effect model, up to 6218 homologous sequences could be aligned by the Fermentor biome but only 24 homologous sequences could be aligned from the Soil biome. The actual alignment of homologous sequences from the metagenome in the Fermentor and Soil biomes may corroborate this marginal effect result (Figure 4A): For PF12652, 4125 homologous sequences could be aligned from the Fermentor biome, and 18 homologous sequences could be aligned from the Soil biome. Hence, for PF12652, the metagenome from the Fermentor biome could have a higher potential to supplement the homologous sequences than the Soil biome.
Figure 4.
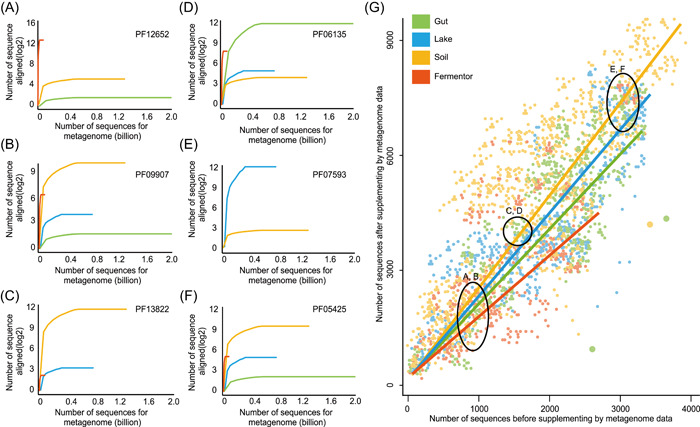
Marginal effects evaluation. Based on the data in reference [70], the marginal effects of the four biomes (Gut, Lake, Soil, Fermentor) on all the 8700 unknown Pfam families (version 32.0) were evaluated, described in reference [70]. The background is an ontology structure that contains the protein families and their relationships, while different colors indicated the high marginal effect values for that protein family by a certain biome. The marginal effect values are also annotated beside several proteins of interest. The data show that the contributions of different biomes to a specific Pfam can be drastically different, as reflected by their marginal values
We evaluated marginal effects on the four biomes (Gut, Soil, Lake, Fermentor) [70] to supplement the homologous sequences for all the 8700 unsolved Pfam families, with results showing that big biomes such as Soil, which contains many metagenome samples and sequences, usually have high marginal effect values for the majority of proteins, but this is not a “winner takes all” pattern. For many proteins, small biomes like Fermentor could also have high marginal effect values (Figure 4). From an evolutionary standpoint, metagenome sequences in various biomes might have distinct evolutionary information (i.e., homologous sequence) for individual proteins.
OTHER FACTORS THAT MIGHT IMPACT THE SUCCESS OF PROTEIN STRUCTURE PREDICTION USING METAGENOME DATA
First, from the evolutionary perspective, the approach of protein structure prediction using metagenome data were characterized as a strategy that “exhausts all attempts in discovering close sequences.” Hence, variables affecting the quality of MSA would impact the success of protein structure prediction using metagenome data. As an important impact parameter, careful e‐value selection while generating the MSA will reduce the noise sequences included in the MSA before tapping the distant sequences. Yang et al. [70] showed that a well‐chosen e‐value would impact the quality of MSA, then impact the success of protein 3D structure modeling. They also design a model, which could predict the optimal sequence distance information parameter (i.e., e‐value cutoff) used for constructing the MSA with the highest quality when given a Pfam family as input.
Second, we should emphasize that, from the ecological perspective, each biome is enriched for a specific set of phyla, which has been proved in previous research [79, 80, 81]. From the perspective of ecology, there are intricate but potentially important properties about protein structures that lead to their association with biomes, and the internal evolutionary and ecological drivers have shaped such properties: to adapt their biomes, functional genes from microbial species have to evolve so that the species could gain the advantage over other species in that specific niche, thus certain functional genes (or protein families) would highly likely to be enriched in a specific niche, though not exclusive to be present in such a niche.
UNTARGETED AND TARGETED APPROACHES FOR PROTEIN STRUCTURE PREDICTION
Nowadays, many protein 3D structure prediction pipelines have been developed to utilize different metagenome sequences to supplement the homologous sequence (Table 1). With a rapidly increasing number of metagenome sequences, the metagenome utilization efficiency and marginal effect are critically important indicators of the effectiveness of metagenome data supplement for the protein structure prediction problem, methods that could improve the values of these two indicators could gain advantage for solving the problem.
Table 1.
Approaches that could utilize metagenome data properties for better protein structure prediction
| Approach | Metagenome source | Number of biomes | Strategy | Source |
|---|---|---|---|---|
| HMM + Rosettaa | IMG database | Multiple biomes | Combined | [63] |
| HMM + C‐QUARKb | Ocean microbiome | Single biomes | Single | [64] |
| Alphafoldc | Metagenome | Multiple biomes | Combined | [57] |
| DeepMSA + C‐I‐TASSERd | Mgnify | Multiple biomes | Combined | [70] |
| MetaSource + DeepMSA + C‐I‐TASSERe | Mgnify | Multiple biomes | Targeted | [70] |
Note: Single strategy: using a single large biome as the protein source. Combined strategy: using a set of large biomes as protein sources. Targeted strategy: customized methods that select different biomes for different proteins.
Using IMG database [70, 82], models for 614 protein families were generated for unknown structures.
Using Tara Oceans data [80], proteins for 27 Pfam families were modeled with unsolved structures.
A deep learning algorithm, leveraging multisequence alignments were used for modeling protein structures.
Built on 4.25 billion microbiome sequences, 1044 Pfam families foldable by C‐I‐TASSER [70].
As targeted approach, MetaSource model was used to identify a set of biomes to supplement homologous sequence for specific Pfam families [70].
The untargeted approach (Figure 5A), which is a method that finds homologous sequences from any source of the metagenome, does not have restrictions on the protein sequence search space. The entire process of an untargeted method lacks explanation and controllability since the association between metagenome data and the predicted proteins is not well known. Hence, the model training and metagenome search were mostly blind, and the source tracking of the most relevant biome datasets for individual protein targets was inefficient.
Figure 5.
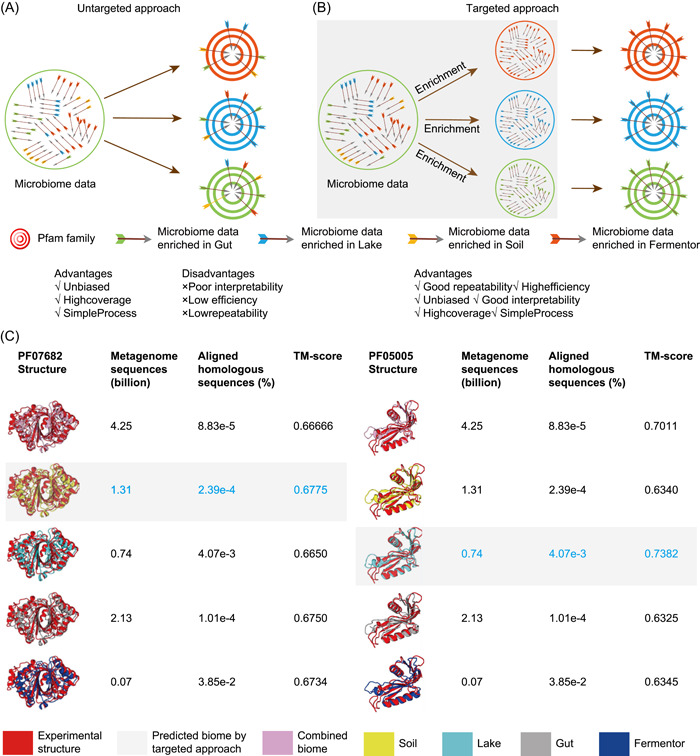
The targeted approach is essentially an enrichment approach. (A) Untargeted approach for the protein 3D structure prediction supplemented by metagenome. (B) Targeted approach for the protein 3D structure prediction supplemented by metagenome. (C) Case studies of modeling Pfam PF07682 and PF05005 with MSA from different biomes as the untargeted approach. For each biome, the number of metagenome sequences and the proportion of aligned homologous sequences in all the metagenome sequences was calculated. The correctness of 3D structure models was determined by comparing them to the known structure, which was quantified using the TM‐score method. The MetaSource is a targeted approach that was developed in a prior study [70]. The model labeled with gray background color is the source biome predicted by MetaSource. In blue type, the model with the highest TM‐score is displayed. 3D, three‐dimensional; MSA, multiple sequence alignment
TARGETED APPROACH COULD UTILIZE METAGENOME DATA PROPERTIES FOR BETTER PROTEIN STRUCTURE PREDICTION
While, compared to the untargeted approach, the targeted approach (Figure 5B) is a type of method that restricted the protein sequence search space. Instead of a blind search, a targeted strategy based on knowledge of the correlation between metagenome sequences might locate enough homologous sequences supplemented by the metagenome from specified biomes, which is favorable in terms of metagenome utilization efficiency and marginal effect.
For this purpose, the goal is simple: select a biome or a group of biomes for a given protein family, so that homologous sequences from this biome are much more enriched than those from other biomes. This MetaSource approach for guiding the source biome of metagenome data for supplementing protein structure prediction was born from this goal [70]: Based on the fact that different biomes enriched with different proteins, MetaSource trained with the Pfam families successfully modeled with a single biome. MetaSource was able to identify which biome would provide the most homologous sequences for protein, and the protein model supplemented by the metagenome from the predicted biome was validated with more accuracy than the protein model supplied by the metagenome from all biomes combined.
As a targeted approach, MetaSource not only predicts more precise protein structure but also outperforms untargeted approaches in terms of metagenome utilization efficiency. Evaluated by the data from previous research [70], MetaSource would be estimated with the metagenome utilization efficiency as 7810 homologous sequences per billion metagenome sequences, which is 50 times higher than the utilization rate using the IMG database (160 homologous sequences per billion metagenome sequences) [63] (Figure 3B). In other words, as a targeted approach, MetaSource can be used to decrease the time spent on the step of supplementing homologous sequences in protein structure prediction. This appears to be a critical area for a focused strategy since it has a direct impact on the efficiency of structure prediction.
For example, we have taken two Pfam examples from PF07682 and PF05005 with the known structure to evaluate the targeted approach and untargeted approach (Figure 5C) [70]. We also discovered that, even though the MSA from the combined biome contains more sequences than a single biome, the structural models from the combined biome are inferior to the MSA from a single biome (Soil or Lake), most likely owing to noise from irrelevant metagenome sequences (Figure 5C). As the targeted approach, MetaSource could forecast the right biome to model the protein 3D structure with the highest TM‐score, using much fewer metagenome sequences than the untargeted approach. The cause for this may be derived from the taxonomic profile found in the Pfam database: PF07682 and PF05005 are mainly composed of proteins from phylum Proteobacteria and Cyanobacteria, which dominate in Soil and Lake biomes, respectively [83, 84]. This result supports the advantage of the targeted approach: high coverage, high efficiency, and interpretability.
In summary, from the ecological and evolutionary perspectives, the metagenome utilization efficiency and marginal effect are crucial metrics for the effective prediction of protein structure from metagenome data, respectively. Metagenome utilization efficiency is highly data‐ and method‐dependent: on the data side, it is heavily dependent on the biomes from which the sequences are obtained; on the method side, an untargeted approach and targeted approach would lead to drastically different metagenome utilization efficiency. Furthermore, in many cases, the targeted approach would result in a more precise protein structure because of the less noise involved, as demonstrated by the comparison of the results based on two Pfam families.
EXAMINATION OF THE BOUNDS FOR METAGENOME DATA NEEDED FOR PROTEIN STRUCTURE PREDICTION
Because template‐free methods rely on a high number of homologous sequences, it would be beneficial to anticipate the bound to represent all the proteins' reliable structures. Although the exact lower bound of metagenome sequences required for protein structure prediction is difficult to quantify, these bounds could be expected based on the same two key factors: metagenome utilization efficiency and marginal effect. Before estimating the bounds, we made a few simple assumptions: (1) from the current Pfam database [60], the number of proteins N(P j), the homologous sequences for a protein family Homo(P j), and the average homologous sequences for a protein AveHomo(P j) could be derived; (2) for current metagenome data (i.e., from IMG database [85], Mgnify database [86] and NCBI SRA database [87]), the number of biomes N(B i) might be determined; (3) based on previous work [63, 64, 70], metagenome utilization efficiency UE(B i, P j) for using metagenome data from a specific biome B i for a specific protein P j, and the average metagenome utilization efficiency Ave(UE) could be calculated. (4) Based on previous work [63, 64, 70], marginal effect ME (B i, P j) for metagenome data from a specific biome B i in supplementing homologous sequences for a specific protein P j could be calculated.
Based on these assumptions, when an untargeted approach is used, a very rough estimation has shown that it would need an enormous amount of metagenome data without restriction on protein sequence search space. The total number of metagenome sequences that would be needed is:
| (1) |
| (2) |
And based on current data statistics, AveHomo(P j) ∼ 3713, N(P j) is 19,179 based on Pfam 34.0 (http://pfam.xfam.org/). And Ave(UE) ∼ 100 per billion metagenome sequences. Thus, Sum(Seq) ∼ 7.12E12 is based on the most conservative estimation.
When the targeted approach is used, the bound of the number of homologous sequences could be largely reduced. For all proteins, the number of metagenome sequences is:
| (3) |
For this number, we can estimate the lower bound as 4.32E12. According to the data from previous research based on four representative biomes (Gut, Soil, Lake, Fermentor) [70], the average metagenome utilization efficiency (per billion metagenome sequence used for specific protein family) are Gut: 10, Soil: 248, Lake: 142, Fermentor: 320, respectively. And the average utilization efficiency is 180 per billion metagenome sequences, which is equivalent with (10(Gut) + 248(Soil) + 142(Lake) + 320(Fermentor))/4(number of biomes) (Equation 1).
Taken together, we have created correlations between the rising number of proteins and the increasing number of metagenome sequences by combining our findings (Figure 6). With the increasing number of sequences in the Pfam database (Figure 6A), the gap between the number of protein sequences and the needed metagenome sequences is widening (Figure 6B). Given that the current Pfam database has 19,179 proteins, 7.12E12 metagenome sequences are estimated to predict all the protein structures but the current metagenome database only about 1.48E12 metagenome sequences (from three metagenome databases: IMG database [85], Mgnify database [86] and SRA database [87]). According to the data from previous research based on four representative biomes (Gut, Soil, Lake, Fermentor) [70], the targeted approach (lower bound was estimated as 4.32E12 by Equation 3) has a lower bound than the untargeted approach, owing to the targeted approach's greater average utilization efficiency (185 per billion metagenome sequences) than the untargeted approach (100 per billion metagenome sequences). It should be noted that this lower bound of the targeted approach is estimated based on using four representative biomes (Gut, Soil, Lake, Fermentor), yet it should already be clear that the lower bound of the targeted approach is small than that of the untargeted approach. Collectively, the targeted approach could substantially reduce the number of metagenome sequences required for this prediction purpose.
Figure 6.
The relationships between the increasing number of proteins, and the increasing amount of metagenome sequences. (A) The number of sequences in Pfam under different versions. (B) The correlation between the number of metagenome sequences and the number of sequences in Pfam. Each node represents a Pfam release version
DISCUSSIONS AND CONCLUSION
Protein 3D structures prediction supplemented by metagenome sequence is a very promising strategy for decoding the structure and function of the proteins, yet previous research has shown that such an approach is quite unstable. This study has revealed the data‐ and method‐dependent patterns behind this approach: The metagenome sequences from different biomes could contribute drastically different for a specific protein family, while the targeted approach could perform much better than the untargeted approach for protein family homologous sequence supplement.
From the ecological perspective, the problem of effective discovery of protein family homologous sequences is essentially a problem about ecological and evolutionary patterns of the proteins: to adapt their biomes, functional genes from microbial species have to evolve so that the species could gain the advantage over other species in that specific niche, thus certain functional genes (or protein families) are highly likely to be enriched in a specific niche, though not exclusive to be present in such a niche.
On the side of ecological modeling, the difficulty of finding homologous sequences in protein families is fundamentally an enrichment problem: from which biome or phyla we can most effectively excavate homologous sequences. And our assessment findings have already demonstrated that a targeted approach such as MetaSource could establish the link between microbes' habitats with homologous sequences, allowing us to deduce the sequential and structural aspects of functional genes from microorganisms' habitat information. This would prompt that the solved proteins would play important role in the predicted biomes and increase the interpretability of the whole targeted process.
On the side of evolutionary patterns, the targeted approach would anticipate the source biome for a protein to find enough evolutionary information (i.e., homologous sequences) to model its reliable structure. Different from the untargeted approach, which only provides the existing evolutionary information in the metagenome, the targeted approach would provide the guidance to find the evolutionary information that already exists in nature but has not been sequenced: If available metagenome cannot provide enough evolutionary information for proteins, the evolutionary information would be supplemented by sequencing the new metagenome samples from the predicted biome.
Furthermore, we estimated the lower bounds to predict the demands of metagenome sequences for predicting 3D structures for all the proteins in the Pfam database, and we discovered that current metagenome data could not meet the needs of metagenome sequences. On one hand, collecting more metagenome sequences could lead to more 3D structure prediction, while on the other hand, there is always a need to balance the prediction power and efficiency based on these huge number of metagenome sequences. For this proposal, the targeted approach would be the ideal alternative since it would boost metagenome utilization efficiency by reducing the search space and providing sufficient homologous information based on the knowledge of the ecological and evolutionary information in various biomes. In this regard, the focused strategy might significantly close the gap for this prediction purpose by enhancing the metagenome usage efficiency and guiding the subsequent homologous sequence supplement.
Collectively, the metagenome data utilization efficiency is profoundly improved by the targeted approach (exemplified by the MetaSource approach), demonstrating the targeted approach's enormous promise for protein structure prediction from metagenome sequences. When combined with another finding in this study that it is not necessarily true that more homologous sequence leads to better structure prediction, we deemed that the targeted approach is a win–win solution for protein structure prediction from metagenome sequences: it not only requires a drastically reduced number of sequences but also could improve prediction results for many protein families. On the other hand, the targeted approach has given us a wealth of knowledge regarding the ecological and evolutionary patterns of the proteins of interest.
CONFLICTS OF INTEREST
The authors declare no conflicts of interest.
AUTHOR CONTRIBUTIONS
Kang Ning conceived of and proposed the idea and designed the study. Pengshuo Yang and Kang Ning performed the review. All contributed to editing and proofreading the manuscript. All authors read and approved the final manuscript.
ACKNOWLEDGMENTS
This study was partially supported by the National Science Foundation of China Grant (Grant Nos. 32071465, 31871334, and 31671374) and the Ministry of Science and Technology's national key research and development program grant (Grant No. 2018YFC0910502).
Yang, Pengshuo , and Ning Kang. 2022. “How Much Metagenome Data is Needed for Protein Structure Prediction: The Advantages of Targeted Approach from the Ecological and Evolutionary Perspectives.” iMeta 1, e9. 10.1002/imt2.9
DATA AVAILABILITY STATEMENT
The data that support the findings of this study are openly available at https://doi.org/10.1126/science.aah4043 [63], https://doi.org/10.1186/s13059-019-1823-z, [64], and https://doi.org/10.1073/pnas.2110828118, [70]. Supporting Information (tables, scripts, graphical abstract, slides, videos, Chinese translated version, and update materials) are available online DOI or GitHub https://github.com/iMetaScience/iMeta2022Ning.
REFERENCES
- 1. Britton, Candace S. , Sorrells Trevor R., and Johnson Alexander D.. 2020. “Protein‐Coding Changes Preceded Cis‐Regulatory Gains in a Newly Evolved Transcription Circuit.” Science 367: 96–100. 10.1126/science.aax5217 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 2. Levin, Doron , Raab Neta, Pinto Yishay, Rothschild Daphna, Zanir Gal, Godneva Anastasia, Mellul Nadav, et al. 2021. “Diversity and Functional Landscapes in the Microbiota of Animals in the Wild.” Science 372(6539): eabb5352. 10.1126/science.abb5352 [DOI] [PubMed] [Google Scholar]
- 3. North, Justin A. , Narrowe Adrienne B., Xiong Weili, Byerly Kathryn M., Zhao Guanqi, Young Sarah J., Murali Srividya, et al. 2020. “A Nitrogenase‐like Enzyme System Catalyzes Methionine, Ethylene, and Methane Biogenesis.” Science 369: 1094–98. 10.1126/science.abb6310 [DOI] [PubMed] [Google Scholar]
- 4. Zhang, Chengxin , Zheng Wei, Freddolino Peter L., and Zhang Yang. 2018. “MetaGO: Predicting Gene Ontology of Non‐Homologous Proteins Through Low‐Resolution Protein Structure Prediction and Protein‐Protein Network Mapping.” Journal of Molecular Biology 430: 2256–65. 10.1016/j.jmb.2018.03.004 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 5. Zheng, Wei , Zhang Chengxin, Li Yang, Pearce Robin, Bell Eric W., and Zhang Yang. 2021. “Folding Non‐Homologous Proteins by Coupling Deep‐Learning Contact Maps with I‐TASSER Assembly Simulations.” Cell Reports Methods 1(3): 100014. 10.1016/j.crmeth.2021.100014 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 6. Baker, David . 2019. “What has De Novo Protein Design Taught us About Protein Folding and Biophysics?” Protein Science 28: 678–83. 10.1002/pro.3588 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 7. Huang, Po‐Ssu , Boyken Scott E., and Baker David. 2016. “The Coming of Age of De Novo Protein Design.” Nature 537: 320–7. 10.1038/nature19946 [DOI] [PubMed] [Google Scholar]
- 8. Laine, Elodie , Eismann Stephan, Elofsson Arne, and Grudinin Sergei. 2021. “Protein Sequence‐to‐Structure Learning: Is this the End(‐to‐End Revolution)?” Proteins 89(12): 1770–86. 10.1002/prot.26235 [DOI] [PubMed] [Google Scholar]
- 9. Pearce, Robin , and Zhang Yang. 2021. “Deep Learning Techniques have Significantly Impacted Protein Structure Prediction and Protein Design.” Current Opinion in Structural Biology 68: 194–207. 10.1016/j.sbi.2021.01.007 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 10. Ivankov, Dmitry N. , and Finkelstein Alexei V.. 2020. “Solution of Levinthal's Paradox and a Physical Theory of Protein Folding Times.” Biomolecules 10(2): 250. 10.3390/biom10020250 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 11. Zeng, Juan , and Huang Zunnan. 2019. “From Levinthal's Paradox to the Effects of Cell Environmental Perturbation on Protein Folding.” Current Medicinal Chemistry 26: 7537–54. 10.2174/0929867325666181017160857 [DOI] [PubMed] [Google Scholar]
- 12. Dou, Jiayi , Vorobieva Anastassia A., Sheffler William, Doyle Lindsey A., Park Hahnbeom, Bick Matthew J., Mao Binchen, et al. 2018. “De Novo Design of a Fluorescence‐Activating Beta‐Barrel.” Nature 561: 485–91. 10.1038/s41586-018-0509-0 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 13. Lu, Peilong , Min Duyoung, DiMaio Frank, Wei Kathy Y., Vahey Michael D., Boyken Scott E., Chen Zibo, et al. 2018. “Accurate Computational Design of Multipass Transmembrane Proteins.” Science 359: 1042–6. 10.1126/science.aaq1739 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 14. Dhingra, Surbhi , Sowdhamini Ramanathan, Cadet Frédéric, and Offmann Bernard. 2020. “A Glance into the Evolution of Template‐Free Protein Structure Prediction Methodologies.” Biochimie 175: 85–92. 10.1016/j.biochi.2020.04.026 [DOI] [PubMed] [Google Scholar]
- 15. Hameduh, Tareq , Haddad Yazan, Adam Vojtech, and Heger Zbynek. 2020. “Homology Modeling in the Time of Collective and Artificial Intelligence.” Computational and Structural Biotechnology Journal 18: 3494–506. 10.1016/j.csbj.2020.11.007 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16. Vreven, Thom , Hwang Howook, Pierce Brian G., and Weng Zhiping. 2014. “Evaluating Template‐Based and Template‐Free Protein‐Protein Complex Structure Prediction.” Briefings in Bioinformatics 15: 169–76. 10.1093/bib/bbt047 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 17. Cao, Yiwei , Park Sang‐Jun, and Im Wonpil. 2021. “A Systematic Analysis of Protein‐Carbohydrate Interactions in the Protein Data Bank.” Glycobiology 31: 126–36. 10.1093/glycob/cwaa062 [DOI] [PubMed] [Google Scholar]
- 18. Li, Fei , Egea Pascal F., Vecchio Alex J., Asial Ignacio, Gupta Meghna, Paulino Joana, Bajaj Ruchika, et al. 2021. “Highlighting Membrane Protein Structure and Function: A Celebration of the Protein Data Bank.” The Journal of Biological Chemistry 296: 100557. 10.1016/j.jbc.2021.100557 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 19. Saibil, Helen R. 2021. “The PDB and Protein Homeostasis: From Chaperones to Degradation and Disaggregase Machines The Journal of Biological Chemistry 296: 100744. 10.1016/j.jbc.2021.100744 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 20. Calabrese, Antonio N. , and Radford Sheena E.. 2018. “Mass Spectrometry‐Enabled Structural Biology of Membrane Proteins.” Methods 147: 187–205. 10.1016/j.ymeth.2018.02.020 [DOI] [PubMed] [Google Scholar]
- 21. Kauffmann, Clemens , Kazimierczuk Krzysztof, Schwarz Thomas C., Konrat Robert, and Zawadzka‐Kazimierczuk Anna. 2020. “A Novel High‐Dimensional NMR Experiment for Resolving Protein Backbone Dihedral Angle Ambiguities.” Journal of Biomolecular NMR 74: 257–65. 10.1007/s10858-020-00308-y [DOI] [PMC free article] [PubMed] [Google Scholar]
- 22. Wuthrich, Kurt . 2021. “Brownian Motion, Spin Diffusion and Protein Structure Determination in Solution.” Journal of Magnetic Resonance 331: 107031. 10.1016/j.jmr.2021.107031 [DOI] [PubMed] [Google Scholar]
- 23. Nerli, Santrupti , De Paula Viviane S., McShan Andrew C., and Sgourakis Nikolaos G.. 2021. “Backbone‐Independent NMR Resonance Assignments of Methyl Probes in Large Proteins.” Nature Communications 12: 691. 10.1038/s41467-021-20984-0 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 24. Papageorgiou, Anastassios C. , Poudel Nirmal, and Mattsson Jesse. 2021. “Protein Structure Analysis and Validation with X‐Ray Crystallography.” Methods in Molecular Biology 2178: 377–404. 10.1007/978-1-0716-0775-6_25 [DOI] [PubMed] [Google Scholar]
- 25. Yip, Ka Man , Fischer Niels, Paknia Elham, Chari Ashwin, and Stark Holger. 2020. “Atomic‐Resolution Protein Structure Determination by Cryo‐EM.” Nature 587: 157–61. 10.1038/s41586-020-2833-4 [DOI] [PubMed] [Google Scholar]
- 26. Adiyaman, Recep , and McGuffin Liam James. 2019. “Methods for the Refinement of Protein Structure 3D Models.” International Journal of Molecular Sciences 20(9): 2301. 10.3390/ijms20092301 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 27. Stiffler, Michael A. , Poelwijk Frank J., Brock Kelly P., Stein Richard R., Riesselman Adam, Teyra Joan, Sachdev, S. Sidhu , et al. 2020. “Protein Structure from Experimental Evolution.” Cell Systems 10: 15–24. 10.1016/j.cels.2019.11.008 [DOI] [PubMed] [Google Scholar]
- 28. Dorn, Márcio , Silva Mariel Barbachane, Buriol Luciana S., and Lamb Luis C.. 2014. “Three‐Dimensional Protein Structure Prediction: Methods and Computational Strategies.” Computational Biology and Chemistry 53PB: 251–76. 10.1016/j.compbiolchem.2014.10.001 [DOI] [PubMed] [Google Scholar]
- 29. Kanitkar, Tejashree Rajaram , Sen Neeladri, Nair Sanjana, Soni Neelesh, Amritkar Kaustubh, Ramtirtha Yogendra, and Madhusudhan M. S.. 2021. “Methods for Molecular Modelling of Protein Complexes.” Methods in Molecular Biology 2305: 53–80. 10.1007/978-1-0716-1406-8_3 [DOI] [PubMed] [Google Scholar]
- 30. Soni, Neelesh , and Madhusudhan M. S.. 2017. “Computational Modeling of Protein Assemblies.” Current Opinion in Structural Biology 44: 179–89. 10.1016/j.sbi.2017.04.006 [DOI] [PubMed] [Google Scholar]
- 31. Wu, Fandi , and Xu Jinbo. 2021. “Deep Template‐Based Protein Structure Prediction.” PLoS Computational Biology 17: e1008954. 10.1371/journal.pcbi.1008954 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 32. Jaroszewski, Lukasz . 2009. “Protein Structure Prediction Based on Sequence Similarity.” Methods in Molecular Biology 569: 129–56. 10.1007/978-1-59745-524-4_7 [DOI] [PubMed] [Google Scholar]
- 33. Petrey, Donald , Chen T. Scott, Deng Lei, Garzon Jose Ignacio, Hwang Howook, Lasso Gorka, Lee Hunjoong, Silkov Antonina, and Honig Barry. 2015. “Template‐Based Prediction of Protein Function.” Current Opinion in Structural Biology 32: 33–8. 10.1016/j.sbi.2015.01.007 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 34. Qu, Xiaotao , Swanson Rosemarie, Day Ryan, and Tsai Jerry. 2009. “A Guide to Template Based Structure Prediction.” Current Protein & Peptide Science 10: 270–85. 10.2174/138920309788452182 [DOI] [PubMed] [Google Scholar]
- 35. Chatzou, Maria , Magis Cedrik, Chang Jia‐Ming, Kemena Carsten, Bussotti Giovanni, Erb Ionas, and Notredame Cedric. 2016. “Multiple Sequence Alignment Modeling: Methods and Applications.” Briefings in Bioinformatics 17: 1009–23. 10.1093/bib/bbv099 [DOI] [PubMed] [Google Scholar]
- 36. Fiser, Andras . 2010. “Template‐Based Protein Structure Modeling.” Methods in Molecular Biology 673: 73–94. 10.1007/978-1-60761-842-3_6 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 37. Brylinski, Michal . 2013. “Unleashing the Power of Meta‐Threading for Evolution/Structure‐Based Function Inference of Proteins.” Frontiers in Genetics 4: 118. 10.3389/fgene.2013.00118 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 38. Pearce, Robin , and Zhang Yang. 2021. “Toward the Solution of the Protein Structure Prediction Problem.” The Journal of Biological Chemistry 297: 100870. 10.1016/j.jbc.2021.100870 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 39. Anishchenko, Ivan , Baek Minkyung, Park Hahnbeom, Hiranuma Naozumi, Kim David E., Dauparas Justas, Mansoor Sanaa, Humphreys Ian R., and Baker David. 2021. “Protein Tertiary Structure Prediction and Refinement Using Deep Learning and Rosetta in CASP14.” Proteins 89: 1722–33. 10.1002/prot.26194 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 40. Rother, Kristian , Rother Magdalena, Boniecki Micha, Puton Tomasz, and Bujnicki Janusz M.. 2011. “RNA and Protein 3D Structure Modeling: Similarities and Differences.” Journal of Molecular Modeling 17: 2325–36. 10.1007/s00894-010-0951-x [DOI] [PMC free article] [PubMed] [Google Scholar]
- 41. Xu, Min , Singla Jitin, Tocheva Elitza I., Chang Yi‐Wei, Stevens Raymond C., and Jensen Grant J.. 2019. “De Novo Structural Pattern Mining in Cellular Electron Cryotomograms.” Structure 27(679–691): e614. 10.1016/j.str.2019.01.005 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 42. Hiranuma, Naozumi , Park Hahnbeom, Baek Minkyung, Anishchenko Ivan, Dauparas Justas, and Baker Dauparas. 2021. “Improved Protein Structure Refinement Guided by Deep Learning Based Accuracy Estimation.” Nature Communication 12: 1340. 10.1038/s41467-021-21511-x [DOI] [PMC free article] [PubMed] [Google Scholar]
- 43. Vangaveti, Sweta , Vreven Thom, Zhang Yang, and Weng Zhiping. 2020. “Integrating Ab Initio and Template‐Based Algorithms for Protein‐Protein Complex Structure Prediction.” Bioinformatics 36: 751–7. 10.1093/bioinformatics/btz623 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 44. Jumper, John , Evans Richard, Pritzel Alexander, Green Tim, Figurnov Michael, Ronneberger Olaf, Tunyasuvunakool Kathryn, et al. 2021. “Highly Accurate Protein Structure Prediction with AlphaFold.” Nature 596: 583–9. 10.1038/s41586-021-03819-2 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45. Alford, Rebecca F. , and Gray Jeffrey J.. 2021. “Membrane Protein Engineering with Rosetta.” Methods Molecular Biology 2315: 43–57. 10.1007/978-1-0716-1468-6_3 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 46. Schoeder, Clara T. , Schmitz Samuel, Adolf‐Bryfogle Jared, Sevy Alexander M., Finn Jessica A., Sauer Marion F., Bozhanova Nina G., et al. 2021. “Modeling Immunity with Rosetta: Methods for Antibody and Antigen Design.” Biochemistry 60: 825–46. 10.1021/acs.biochem.0c00912 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 47. Yachnin, Brahm J. , Mulligan Vikram Khipple, Khare Sagar D., and Bailey‐Kellogg Chris. 2021. “MHCEpitopeEnergy, a Flexible Rosetta‐Based Biotherapeutic Deimmunization Platform.” Journal of Chemical Information and Modeling 61: 2368–82. 10.1021/acs.jcim.1c00056 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 48. Kemege, Kyle E. , Hickey John M., Lovell Scott, Battaile Kevin P., Zhang Yang, and Hefty P. Scott. 2011. “Ab Initio Structural Modeling of and Experimental Validation for Chlamydia trachomatis Protein CT296 Reveal Structural Similarity to Fe(II) 2‐Oxoglutarate‐dependent Enzymes.” Journal of Bacteriology 193: 6517–28. 10.1128/JB.05488-11 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 49. Wu, Sitao , Skolnick Jeffrey, and Zhang Yang. 2007. “Ab Initio Modeling of Small Proteins by Iterative TASSER Simulations.” BMC Biology 5: 17. 10.1186/1741-7007-5-17 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 50. Jumper, John , Evans Richard, Pritzel Alexander, Green Tim, Figurnov Michael, Ronneberger Olaf, Tunyasuvunakool Kathryn, et al. 2021. “Applying and Improving AlphaFold at CASP14.” Proteins 89: 1711–21. 10.1002/prot.26257 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 51. Kryshtafovych, Andriy , Schwede Torsten, Topf Maya, Fidelis Krzysztof, and Moult John. 2021. “Critical Assessment of Methods of Protein Structure Prediction (CASP)‐Round XIV.” Proteins 89: 1607–17. 10.1002/prot.26237 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 52. Yan, Yumeng , Wen Zeyu, Wang Xinxiang, and Huang Sheng‐You. 2017. “Addressing Recent Docking Challenges: A Hybrid Strategy to Integrate Template‐Based and Free Protein‐Protein Docking.” Proteins 85: 497–512. 10.1002/prot.25234 [DOI] [PubMed] [Google Scholar]
- 53. Yu, Dong‐Jun , Hu Jun, Yang Jing, Shen Hong‐Bin, Tang Jinhui, and Yang Jing‐Yu. 2013. “Designing Template‐Free Predictor for Targeting Protein‐Ligand Binding Sites with Classifier Ensemble and Spatial Clustering.” IEEE/ACM Transactions on Computational Biology and Bioinformatics 10: 994–1008. 10.1109/TCBB.2013.104 [DOI] [PubMed] [Google Scholar]
- 54. Delarue, Marc , and Koehl Patrice. 2018. “Combined Approaches from Physics, Statistics, and Computer Science for Ab Initio Protein Structure Prediction: Ex Unitate Vires (Unity is Strength)?” F1000Research 7: F1000. 10.12688/f1000research.14870.1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 55. Konagurthu, Arun S. , Subramanian Ramanan, Allison Lloyd, Abramson David, Stuckey Peter J., Garcia de la Banda Maria, and Lesk Arthur M.. 2020. “Universal Architectural Concepts Underlying Protein Folding Patterns.” Frontiers in Molecular Biosciences 7: 612920. 10.3389/fmolb.2020.612920 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 56. Wu, Tianqi , Hou Jie, Adhikari Badri, and Cheng Jianlin. 2020. “Analysis of Several Key Factors Influencing Deep Learning‐Based Inter‐Residue Contact Prediction.” Bioinformatics 36: 1091–8. 10.1093/bioinformatics/btz679 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 57. Tunyasuvunakool, Kathryn , Adler Jonas, Wu Zachary, Green Tim, Zielinski Michal, Žídek Augustin, Bridgland Alex, et al. 2021. “Highly Accurate Protein Structure Prediction for the Human Proteome.” Nature 596: 590–6. 10.1038/s41586-021-03828-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 58. El‐Gebali, Sara , Mistry Jaina, Bateman Alex, Eddy Sean R., Luciani Aurélien, Potter Simon C., Qureshi Matloob, et al. 2019. “The Pfam Protein Families Database in 2019.” Nucleic Acids Research 47: D427–32. 10.1093/nar/gky995 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 59. Finn, Robert D. , Coggill Penelope, Eberhardt Ruth Y., Eddy Sean R., Mistry Jaina, Mitchell Alex L., Potter Simon C., et al. 2016. “The Pfam Protein Families Database: Towards a More Sustainable Future.” Nucleic Acids Research 44: D279–85. 10.1093/nar/gkv1344 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 60. Mistry, Jaina , Chuguransky Sara, Williams Lowri, Qureshi Matloob, Salazar Gustavo A., Erik L. L. Sonnhammer , Tosatto Silvio C. E., et al. 2021. “Pfam: The Protein Families Database in 2021.” Nucleic Acids Research 49: D412–9. 10.1093/nar/gkaa913 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 61. Biehn, Sarah E. , and Lindert Steffen. 2021. “Protein Structure Prediction with Mass Spectrometry Data.” Annual Review of Physical Chemistry 73. 10.1146/annurev-physchem-082720-123928 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 62. Dokholyan, Nikolay V. 2020. “Experimentally‐Driven Protein Structure Modeling.” Journal of Proteomics 220: 103777. 10.1016/j.jprot.2020.103777 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 63. Ovchinnikov, Sergey , Park Hahnbeom, Varghese Neha, Huang Po‐Ssu, Pavlopoulos Georgios A., Kim David E., Kamisetty Hetunandan, Kyrpides Nikos C., and Baker David. 2017. “Protein Structure Determination Using Metagenome Sequence Data.” Science 355: 294–8. 10.1126/science.aah4043 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 64. Wang, Yan , Shi Qiang, Yang Pengshuo, Zhang Chengxin, Mortuza S. M., Xue Zhidong, Ning Kang, and Zhang Yang. 2019. “Fueling Ab Initio Folding with Marine Metagenomics Enables Structure and Function Predictions of New Protein Families.” Genome Biology 20: 229. 10.1186/s13059-019-1823-z [DOI] [PMC free article] [PubMed] [Google Scholar]
- 65. Wu, Qi , Peng Zhenling, Anishchenko Ivan, Cong Qian, Baker David, and Yang Jianyi. 2020. “Protein Contact Prediction using Metagenome Sequence Data and Residual Neural Networks.” Bioinformatics 36: 41–8. 10.1093/bioinformatics/btz477 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 66. Yang, Jianyi , Anishchenko Ivan, Park Hahnbeom, Peng Zhenling, Ovchinnikov Sergey, and Baker David. 2020. “Improved Protein Structure Prediction using Predicted Interresidue Orientations.” Proceedings of the National Academy of Sciences of the United States of America 117: 1496–503. 10.1073/pnas.1914677117 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 67. Aevarsson, Arnthór , Kaczorowska Anna‐Karina, Adalsteinsson Björn Thor, Ahlqvist Josefin, Al‐Karadaghi Salam, Altenbuchner Joseph, Hasan Arsin, et al. 2021. “Going to Extremes—a Metagenomic Journey into the Dark Matter of Life.” FEMS Microbiology Letters 368(12): fnab067. 10.1093/femsle/fnab067 [DOI] [PubMed] [Google Scholar]
- 68. Parks, Donovan H. , Rinke Christian, Chuvochina Maria, Chaumeil Pierre‐Alain, Woodcroft Ben J., Evans Paul N., Hugenholtz Philip, and Tyson Gene W.. 2017. “Recovery of Nearly 8,000 Metagenome‐Assembled Genomes Substantially Expands the Tree of Life.” Nature Microbiology 2: 1533–42. 10.1038/s41564-017-0012-7 [DOI] [PubMed] [Google Scholar]
- 69. Rinke, Christian , Schwientek Patrick, Sczyrba Alexander, Ivanova Natalia N., Anderson Iain J., Cheng Jan‐Fang, Darling Aaron, et al. 2013. “Insights into the Phylogeny and Coding Potential of Microbial Dark Matter.” Nature 499: 431–7. 10.1038/nature12352 [DOI] [PubMed] [Google Scholar]
- 70. Yang, Pengshuo , Zheng Wei, Ning Kang, and Zhang Yang. 2021. “Decoding the Link of Microbiome Niches with Homologous Sequences Enables Accurately Targeted Protein Structure Prediction.” Proceedings of the National Academy of Sciences of the United States of America 118: e2110828118. 10.1073/pnas.2110828118 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 71. Devkota, Suzanne . 2020. “Big Data and Tiny Proteins: Shining a Light on the Dark Corners of the Gut Microbiome.” Nature Reviews Gastroenterology & Hepatology 17: 68–9. 10.1038/s41575-019-0243-6 [DOI] [PubMed] [Google Scholar]
- 72. Falony, Gwen , Vieira‐Silva Sara, and Raes Jeroen. 2015. “Microbiology Meets Big Data: The Case of Gut Microbiota‐Derived Trimethylamine.” Annual Review of Microbiology 69: 305–21. 10.1146/annurev-micro-091014-104422 [DOI] [PubMed] [Google Scholar]
- 73. Heyer, Robert , Schallert Kay, Zoun Roman, Becher Beatrice, Saake Gunter, and Benndorf Dirk. 2017. “Challenges and Perspectives of Metaproteomic Data Analysis.” Journal of Biotechnology 261: 24–36. 10.1016/j.jbiotec.2017.06.1201 [DOI] [PubMed] [Google Scholar]
- 74. Svenningsen, Nanna B. , Perez‐Pantoja Danilo, Nikel Pablo I., Nicolaisen Mette H., de Lorenzo Víctor, and Nybroe Ole. 2015. “ Pseudomonas putida mt‐2 Tolerates Reactive Oxygen Species Generated During Matric Stress by Inducing a Major Oxidative Defense Response.” BMC Microbiology 15: 202. 10.1186/s12866-015-0542-1 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 75. Wang, Jicheng , Dong Xiao, Shao Yuyu, Guo Huiling, Pan Lin, Hui Wenyan, Kwok Lai‐Yu, Zhang Heping, and Zhang Wenyi. 2017. “Genome Adaptive Evolution of Lactobacillus casei under Long‐Term Antibiotic Selection Pressures.” BMC Genomics 18: 320. 10.1186/s12864-017-3710-x [DOI] [PMC free article] [PubMed] [Google Scholar]
- 76. Coulombe, Janie , Moodie Erica E. M., and Platt Robert W.. 2021. “Estimating the Marginal Effect of a Continuous Exposure on an Ordinal Outcome Using Data Subject to Covariate‐driven Treatment and Visit Processes.” Statistics in Medicine 40: 5746–64. 10.1002/sim.9151 [DOI] [PubMed] [Google Scholar]
- 77. Fakher, Hossein Ali , Panahi Mostafa, Emami Karim, Peykarjou Kambiz, and Zeraatkish Seyed Yaghoub. 2021. “Investigating Marginal Effect of Economic Growth on Environmental Quality Based on Six Environmental Indicators: Does Financial Development have a Determinative Role in Strengthening or Weakening this Effect?” Environmental Science and Pollution Research 28: 53679–99. 10.1007/s11356-021-14470-9 [DOI] [PubMed] [Google Scholar]
- 78. Mills, Molly C. , Evans Morgan V., Lee Seungjun, Knobloch Thomas, Weghorst Christopher, and Lee Jiyoung. 2021. “Acute Cyanotoxin Poisoning Reveals a Marginal Effect on Mouse Gut Microbiome Composition but Indicates Metabolic Shifts Related to Liver and Gut Inflammation.” Ecotoxicology and Environmental Safety 215: 112126. 10.1016/j.ecoenv.2021.112126 [DOI] [PubMed] [Google Scholar]
- 79. Lloyd‐Price, Jason , Arze Cesar, Ananthakrishnan Ashwin N., Schirmer Melanie, Avila‐Pacheco Julian, Poon Tiffany W., Andrews Elizabeth, et al. 2019. “Multi‐Omics of the Gut Microbial Ecosystem in Inflammatory Bowel Diseases.” Nature 569: 655–62. 10.1038/s41586-019-1237-9 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 80. Sunagawa, Shinichi , Coelho Luis Pedro, Chaffron Samuel, Kultima Jens Roat, Labadie Karine, Salazar Guillem, Djahanschiri Bardya, et al. 2015. “Ocean Plankton. Structure and Function of the Global Ocean Microbiome.” Science 348: 1261359. 10.1126/science.1261359 [DOI] [PubMed] [Google Scholar]
- 81. Thompson, Luke R. , Sanders Jon G., McDonald Daniel, Amir Amnon, Ladau Joshua, Locey Kenneth J., Prill Robert J., et al. 2017. “A Communal Catalogue Reveals Earth's Multiscale Microbial Diversity.” Nature 551: 457–63. 10.1038/nature24621 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 82. Chen, I‐Min A. , Chu Ken, Palaniappan Krishna, Pillay Manoj, Ratner Anna, Huang Jinghua, Huntemann Marcel, et al. 2019. “IMG/M v.5.0: An Integrated Data Management and Comparative Analysis System for Microbial Genomes and Microbiomes.” Nucleic Acids Research 47: D666–77. 10.1093/nar/gky901 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 83. Bahram, Mohammad , Hildebrand Falk, Forslund Sofia K., Anderson Jennifer L., Soudzilovskaia Nadejda A., Bodegom Peter M., Bengtsson‐Palme Johan, et al. 2018. “Structure and Function of the Global Topsoil Microbiome.” Nature 560: 233–7. 10.1038/s41586-018-0386-6 [DOI] [PubMed] [Google Scholar]
- 84. Li, Hanyan , Barber Mike, Lu Jingrang, and Goel Ramesh. 2020. “Microbial Community Successions and their Dynamic Functions During Harmful Cyanobacterial Blooms in a Freshwater Lake.” Water Research 185: 116292. 10.1016/j.watres.2020.116292 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 85. Chen, I‐Min A. , Markowitz Victor M., Chu Ken, Palaniappan Krishna, Szeto Ernest, Pillay Manoj, Ratner Anna, et al. 2017. “IMG/M: Integrated Genome and Metagenome Comparative Data Analysis System.” Nucleic Acids Research 45: D507–16. 10.1093/nar/gkw929 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 86. Mitchell, Alex L. , Almeida Alexandre, Beracochea Martin, Boland Miguel, Burgin Josephine, Cochrane Guy, Crusoe Michael R., et al. 2020. “MGnify: The Microbiome Analysis Resource in 2020.” Nucleic Acids Research 48: D570–8. 10.1093/nar/gkz1035 [DOI] [PMC free article] [PubMed] [Google Scholar]
- 87. Sayers, Eric W. , Beck Jeffrey, Bolton Evan E., Bourexis Devon, Brister James R., Canese Kathi, Comeau Donald C., et al. 2021. “Database Resources of the National Center for Biotechnology Information.” Nucleic Acids Research 49: D10–7. 10.1093/nar/gkaa892 [DOI] [PMC free article] [PubMed] [Google Scholar]
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Data Availability Statement
The data that support the findings of this study are openly available at https://doi.org/10.1126/science.aah4043 [63], https://doi.org/10.1186/s13059-019-1823-z, [64], and https://doi.org/10.1073/pnas.2110828118, [70]. Supporting Information (tables, scripts, graphical abstract, slides, videos, Chinese translated version, and update materials) are available online DOI or GitHub https://github.com/iMetaScience/iMeta2022Ning.